Mysql中MyISAM和InnoDB的区别及说明
目录
- MyISAM和InnoDB的区别
- 1. 定义
- 2. 区别
- 3. 使用
- MyISAM和InnoDB索引结构分析
- 存储引擎作用于什么对象
- MyISAM和InnoDB对索引和数据的存储在磁盘上是如何体现的
- MyISAM主键索引与辅助索引的结构
- InnoDB主键索引与辅助索引的结构
- InnoDB索引结构需要注意的点
- 总结
MyISAM和InnoDB的区别
1. 定义
InnoDB:
InnoDB:MySQL默认的事务型引擎,也是最重要和使用最广泛的存储引擎。
它被设计成为大量的短期事务,短期事务大部分情况下是正常提交的,很少被回滚。InnoDB的性能与自动崩溃恢复的特性,使得它在非事务存储需求中也很流行。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
MyISAM:
MyISAM:在MySQL 5.5 及之前的版本,MyISAM是默认引擎。
MyISAM提供的大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM并不支持事务以及行级锁,而且一个毫无疑问的缺陷是崩溃后无法安全恢复。正是由于MyISAM引擎的缘故,即使MySQL支持事务已经很长时间了,在很多人的概念中MySQL还是非事务型数据库。尽管这样,它并不是一无是处的。对于只读的数据,或者表比较小,可以忍受修复操作,则依然可以使用MyISAM(但请不要默认使用MyISAM,而是应该默认使用InnoDB)
2. 区别
InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
InnoDB 是聚集索引,MyISAM 是非聚集索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。
这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
3. 使用
是否要支持事务,如果要请选择 InnoDB,如果不需要可以考虑 MyISAM;
如果表中绝大多数都只是读查询,可以考虑 MyISAM,如果既有读写也挺频繁,请使用InnoDB。
系统奔溃后,MyISAM恢复起来更困难,能否接受,不能接受就选 InnoDB;
MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的。如果你不知道用什么存储引擎,那就用InnoDB,至少不会差。
MyISAM和InnoDB索引结构分析
存储引擎作用于什么对象
存储引擎是作用在表上的,而不是数据库。
MyISAM和InnoDB对索引和数据的存储在磁盘上是如何体现的
先来看下面创建的两张表信息,role表使用的存储引擎是MyISAM,而user使用的是InnoDB:
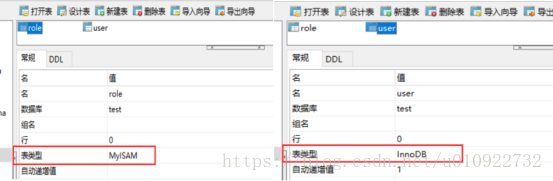
再来看下两张表在磁盘中的索引文件和数据文件:
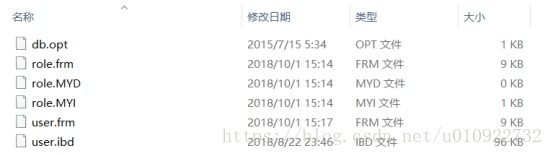
1. role表有三个文件,对应如下:
role.frm:表结构文件role.MYD:数据文件(MyISAM Data)role.MYI:索引文件(MyISAM Index)
2. user表有两个文件,对应如下:
user.frm:表结构文件user.ibd:索引和数据文件(InnoDB Data)
也由于两种引擎对索引和数据的存储方式的不同,我们也称MyISAM的索引为非聚集索引,InnoDB的索引为聚集索引。
MyISAM主键索引与辅助索引的结构
我们先列举一部分数据出来分析,如下:
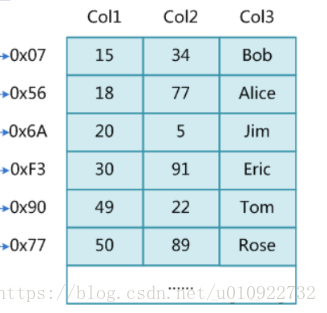
上面已经说明了MyISAM引擎的索引文件和数据文件是分离的,我们接着看一下下面两种索引结构异同。
1. 主键索引:
上一篇文章已经介绍过数据库索引是采用B+Tree存储,并且只在叶子节点存储数据,在MyISAM引擎中叶子结点存储的数据其实是索引和数据的文件指针两类。
如下图中我们以Col1列作为主键建立索引,对应的叶子结点储存形式可以看一下表格。
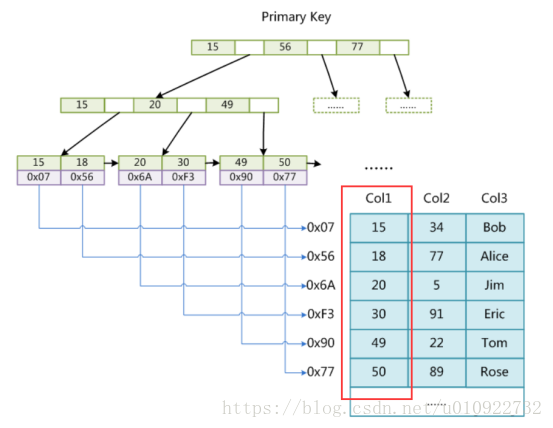
通过索引查找数据的流程:先从索引文件中查找到索引节点,从中拿到数据的文件指针,再到数据文件中通过文件指针定位了具体的数据。
2. 辅助(非主键)索引:
以Col2列建立索引,得到的辅助索引结构跟上面的主键索引的结构是相同的。
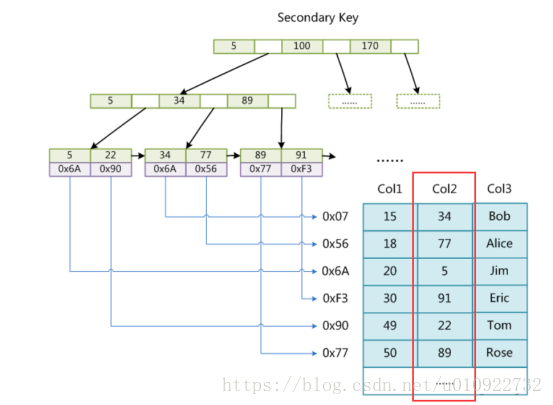
InnoDB主键索引与辅助索引的结构
1. 主键索引:
我们已经知道InnoDB索引是聚集索引,它的索引和数据是存入同一个.idb文件中的,因此它的索引结构是在同一个树节点中同时存放索引和数据,如下图中最底层的叶子节点有三行数据,对应于数据表中的Col1、Col2、Col3数据项。

2. 辅助(非主键)索引:
这次我们以数据表中的Col3列的字符串数据建立辅助索引,它的索引结构跟主键索引的结构有很大差别,我们来看下面的图:
在最底层的叶子结点有两行数据,第一行的字符串是辅助索引,按照ASCII码进行排序,第二行的整数是主键的值。

InnoDB索引结构需要注意的点
- 1. 数据文件本身就是索引文件
- 2. 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 3. 聚集索引中叶节点包含了完整的数据记录
- 4. InnoDB表必须要有主键,并且推荐使用整型自增主键
正如我们上面介绍InnoDB存储结构,索引与数据是共同存储的,不管是主键索引还是辅助索引,在查找时都是通过先查找到索引节点才能拿到相对应的数据,如果我们在设计表结构时没有显式指定索引列的话,MySQL会从表中选择数据不重复的列建立索引,如果没有符合的列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,并且这个字段长度为6个字节,类型为整型。
那为什么推荐使用整型自增主键而不是选择UUID?
UUID是字符串,比整型消耗更多的存储空间;
在B+树中进行查找时需要跟经过的节点值比较大小,整型数据的比较运算比字符串更快速;
自增的整型索引在磁盘中会连续存储,在读取一页数据时也是连续;UUID是随机产生的,读取的上下两行数据存储是分散的,不适合执行where id > 5 && id < 20的条件查询语句。
在插入或删除数据时,整型自增主键会在叶子结点的末尾建立新的叶子节点,不会破坏左侧子树的结构;UUID主键很容易出现这样的情况,B+树为了维持自身的特性,有可能会进行结构的重构,消耗更多的时间。
为什么非主键索引结构叶子节点存储的是主键值?
保证数据一致性和节省存储空间,可以这么理解:商城系统订单表会存储一个用户ID作为关联外键,而不推荐存储完整的用户信息,因为当我们用户表中的信息(真实名称、手机号、收货地址···)修改后,不需要再次维护订单表的用户数据,同时也节省了存储空间。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Mysql更换MyISAM存储引擎为Innodb的操作记录总结
一般情况下,mysql会默认提供多种存储引擎,可以通过下面的查看: 1)查看mysql是否安装了innodb插件. 通过下面的命令结果可知,已经安装了innodb插件. mysql> show plugins; +------------+--------+----------------+---------+---------+ | Name | Status | Type | Library | License | +------------+--------+---------------
-

MySQL存储引擎MyISAM与InnoDB区别总结整理
1.MySQL默认存储引擎的变迁 在MySQL 5.1之前的版本中,默认的搜索引擎是MyISAM,从MySQL 5.5之后的版本中,默认的搜索引擎变更为InnoDB. 2.MyISAM与InnoDB存储引擎的主要特点 MyISAM存储引擎的特点是:表级锁.不支持事务和全文索引,适合一些CMS内容管理系统作为后台数据库使用,但是使用大并发.重负荷生产系统上,表锁结构的特性就显得力不从心: 以下是MySQL 5.7 MyISAM存储引擎的版本特性: InnoDB存储引擎的特点是:行级锁.事务安全(A
-
MySQL创建数据表时设定引擎MyISAM/InnoDB操作
我在配置mysql时将配置文件中的默认存储引擎设定为了InnoDB.今天查看了MyISAM与InnoDB的区别,在该文中的第七条"MyISAM支持GIS数据,InnoDB不支持.即MyISAM支持以下空间数据对象:Point,Line,Polygon,Surface等." 作为一个地理信息系统专业的学生(其实是测绘专业)来讲,能存储空间数据的数据库才是好数据库,原谅我是数据库小白的身份. 有三种方式可以设定数据库引擎: (1)修改配置文件 将安装目录下~\MySQL\mysql-5.6
-
Mysql中MyISAM和InnoDB的区别及说明
目录 MyISAM和InnoDB的区别 1. 定义 2. 区别 3. 使用 MyISAM和InnoDB索引结构分析 存储引擎作用于什么对象 MyISAM和InnoDB对索引和数据的存储在磁盘上是如何体现的 MyISAM主键索引与辅助索引的结构 InnoDB主键索引与辅助索引的结构 InnoDB索引结构需要注意的点 总结 MyISAM和InnoDB的区别 1. 定义 InnoDB: InnoDB:MySQL默认的事务型引擎,也是最重要和使用最广泛的存储引擎. 它被设计成为大量的短期事务,短期事务大
-
MySQL存储引擎简介及MyISAM和InnoDB的区别
MyISAM:默认的MySQL插件式存储引擎,它是在Web.数据仓储和其他应用环境下最常使用的存储引擎之一.注意,通过更改 STORAGE_ENGINE 配置变量,能够方便地更改MySQL服务器的默认存储引擎. InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务支持. BDB:可替代InnoDB的事务引擎,支持COMMIT.ROLLBACK和其他事务特性. Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问. Merge:允许MyS
-
MySQL MyISAM 与InnoDB 的区别
区别: 1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务: 2. InnoDB支持外键,而MyISAM不支持.对一个包含外键的InnoDB表转为MYISAM会失败: 3. InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高.但
-
聊一聊MyISAM和InnoDB的区别
主要有以下区别: 1.MySQL默认采用的是MyISAM. 2.MyISAM不支持事务,而InnoDB支持.InnoDB的AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,所以最好是把多条SQL语句显示放在begin和commit之间,组成一个事务去提交. 3.InnoDB支持数据行锁定,MyISAM不支持行锁定,只支持锁定整个表.即MyISAM同一个表上的读锁和写锁是互斥的,MyISAM并发读写时如果等待队列中既有读请求又有写请求,默认写请求的
-
MYSQL中 char 和 varchar的区别
CHAR和VARCHAR类型相似,差别主要在存储,尾随空格和检索方式上. CHAR和VARCHAR相同的是:CHAR和VARCHAR都指定了字符长度,注意是字符长度.例如char(30) 和 varchar(30)表示都可以存30个字符.有一点要注意的是在utf8mb4编码中,每个字符占4个节点.在utf8中,每个字符占3个字节.当要存储的字符超过CHAR/VARCHAR指定的最大长度.在sql mode 没开启的时候是截断要存储的字串,只存储前30位 CHAR列中的值是定长的字符串.长度可以指
-
Mysql中where与on的区别及何时使用详析
之前在写连表查询的时候,老是分不清楚where和on的区别,导致有时写的SQL会出现一点小的问题,这里专门写篇文章做下记录,如果你也分不清,那么请参考 二者的区别及什么时候使用 说明:区分on和where首先我们将连接分为内部连接和非内部连接,内部连接时on和where的作用是一样的,通常我们分不清它们的区别说的是非内部连接 一般on用来连接两个表,只的是连接的条件,在内部连接时,可以省略on,此时它表示的是两个表的笛卡尔积:使用on连接后,mysql会生成一张临时表,而where就是在临时表的
-
MySQL中replace into与replace区别详解
目录 0.故事的背景 1.replace into 的使用方法 2.有唯一索引时—replace into & 与replace 效果 3.没有唯一索引时—replace into 与 replace 1).replace函数的具体情况 2).replace into 函数的具体情况 4.replace的用法 本篇为抛砖引玉篇,之前没关注过replace into 与replace 的区别.经过多个场景测试,居然没找到在插入数据的时候两者有什么本质的区别?如果了解详情的伙伴们,请告知留言告知一二
-
MySQL中interactive_timeout和wait_timeout的区别
在用mysql客户端对数据库进行操作时,打开终端窗口,如果一段时间没有操作,再次操作时,常常会报如下错误: ERROR 2013 (HY000): Lost connection to MySQL server during query ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect... 这个报错信息就意味着当前的连接已经断开,需要重新建立连接. 那么,连接的时长是如何确认的?
-
全面了解mysql中utf8和utf8mb4的区别
一.简介 MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode.好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换.当然,为了节省空间,一般情况下使用utf8也就够了. 二.内容描述 那上面说了既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了.三个字节的 UT
-
当面试官问mysql中char与varchar的区别
目录 char与varchar的区别 char与varchar的区别 以上就是当面试官问mysql中char与varchar的区别的详细内容,更多关于char与varchar的区别的资料请关注我们其它相关文章!