mariadb集群搭建---Galera Cluster+ProxySQL教程
目录
- 前言
- 一、Galera Cluster
- 二、基础环境搭建
- 三、加入配置参数启动集群
- 四、 测试
- 五、ProxySql
- 总结
前言
本篇主要用于记录mariaDb环境下Galera Cluster模式集群环境的搭建过程,只做演示中间参数可能会有不当地方需自行调整。
案例所采用的的是最新10.5.8版本,Mariadb10.1以后的版本中MariaDB Galera Cluste不再单独发行,而是以galera-25.3.12-2.el7.x86_64包的形式出现。如果是10.0以下版本需要另外去安装下Galera Cluster环境。
详情可以去到官网了解https://mariadb.com/kb/en/galera-cluster/
一、Galera Cluster
MariaDB Galera Cluster 是一套在 mysql innodb 存储引擎上面实现multi-master及数据实时同步的系统架构,业务层面无需做读写分离工作,数据库读写压力都能按照既定的规则分发到各个节点上去。在数据方面完全兼容 MariaDB 和 MySQL。
Galera Cluster 与传统的复制方式不同,不通过I/O_thread和sql_thread进行同步,而是在更底层通过wsrep实现文件系统级别的同步,可以做到几乎实时同步。
特点:
- 功能特性
- 同步复制 Synchronous replication
- Active-active multi-master 拓扑逻辑
- 可对集群中任一节点进行数据读写
- 自动成员控制,故障节点自动从集群中移除
- 自动节点加入
- 真正并行的复制,基于行级
- 直接客户端连接,原生的 MySQL 接口
- 每个节点都包含完整的数据副本
- 多台数据库中数据同步由 wsrep 接口实现
局限性:
- 目前的复制仅仅支持InnoDB存储引擎,任何写入其他引擎的表,包括mysql.*表将不会复制,但是DDL语句会被复制的,因此创建用户将会被复制,但是insert into mysql.user…将不会被复制的.
- DELETE操作不支持没有主键的表,没有主键的表在不同的节点顺序将不同,如果执行SELECT…LIMIT… 将出现不同的结果集.
- 在多主环境下LOCK/UNLOCK TABLES不支持,以及锁函数GET_LOCK(), RELEASE_LOCK()…
- 查询日志不能保存在表中。如果开启查询日志,只能保存到文件中。
- 允许最大的事务大小由wsrep_max_ws_rows和wsrep_max_ws_size定义。任何大型操作将被拒绝。如大型的LOAD DATA操作。
- 由于集群是乐观的并发控制,事务commit可能在该阶段中止。如果有两个事务向在集群中不同的节点向同一行写入并提交,失败的节点将中止。对 于集群级别的中止,集群返回死锁错误代码(Error: 1213 SQLSTATE:
- 40001 (ER_LOCK_DEADLOCK)).
- XA事务不支持,由于在提交上可能回滚。
- 整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
- 集群节点建议最少3个。
- 如果DDL语句有问题将破坏集群。
注:Galera集群至少需要三个节点
二、基础环境搭建
1.安装docker与docker-compose
这里默认都已经安装好,下面简单给出安装需要的命令。
下面命令是基于centos8.0以上环境
sudo yum install -y yum-utils sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install docker-ce docker-ce-cli containerd.io sudo systemctl start docker 这里建议大家在/etc/docker下增加国内镜像源,可以自行去阿里注册申请。目录下添加daemon.json镜像源配置后重启docker systemctl restart docker
docker-compose:
这里有一个比较低概率的小坑提醒大伙,如果你使用的是arm架构的系统就不能采取常规方式安装。楼主之前买了华为云鲲鹏务器因为是arm架构自己没有注意在此采坑解决了很久,最后还是通过给华为兄弟提交工单才解决。
下面给出解决问题的地址。
如有相同情况请采用下面方式安装https://support.huaweicloud.com/prtg-kunpengmm/dockercompose_01_0001.html
x86系统有很多方式 通过curl weget下载安装包都可以,不过github经常会丢包很慢建议使用国内镜像。
下面给出centos8下常规pip3安装方式,如果是centos7则用pip
pip3 install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com --upgrade pip
pip3 install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com docker-compose
方便快捷一步到位
起初打算采用docker的方式进行配置但是由于容器的很多局限性普通数据库放在docker并不合适会有很多弊端后面改变了主意,索性将这部分留下当做一个简单的安装教程。
2. 常规环境搭建
想要安装最新版本,需要添加自己的repo仓库配置。这里使用国内清华提供的镜像速度更快一点。/etc/yum.repos.d下创建mariadb.repo文件。想要那个版本自己去更改即可,需要注意的就是10.4后glera文件的路径有所不同由原来的的glera改为了glera-4。
最后更新yum缓存 yum clean all ; yum makecache
# MariaDB 10.5 CentOS repository list - created 2020-12-16 12:37 UTC # http://downloads.mariadb.org/mariadb/repositories/ [mariadb] name = MariaDB baseurl = https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-10.5.8/yum/centos8-amd64/ gpgkey = https://mirrors.tuna.tsinghua.edu.cn/mariadb/yum/RPM-GPG-KEY-MariaDB module_hotfixes=1 gpgcheck=1
直接使用yum install -y命令安装,这里我们会发现镜像只给我们安装了mariadb-client客户端。
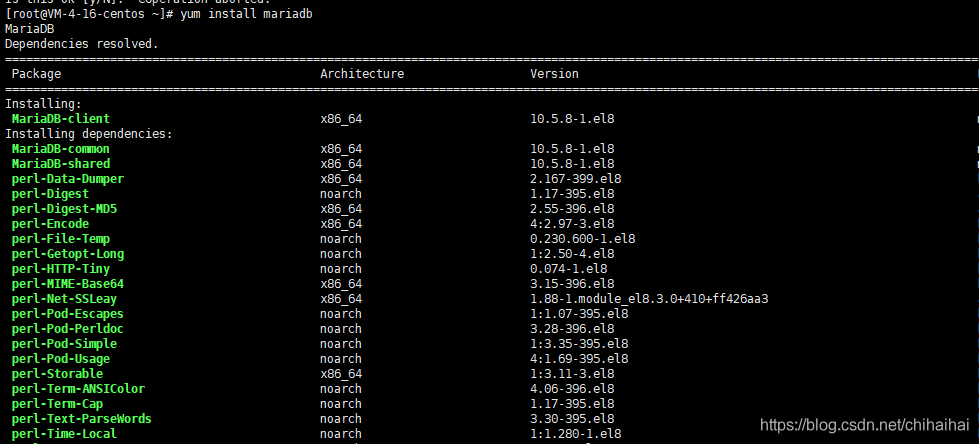
后面我在官网找到了答案,还需要单独安装服务端

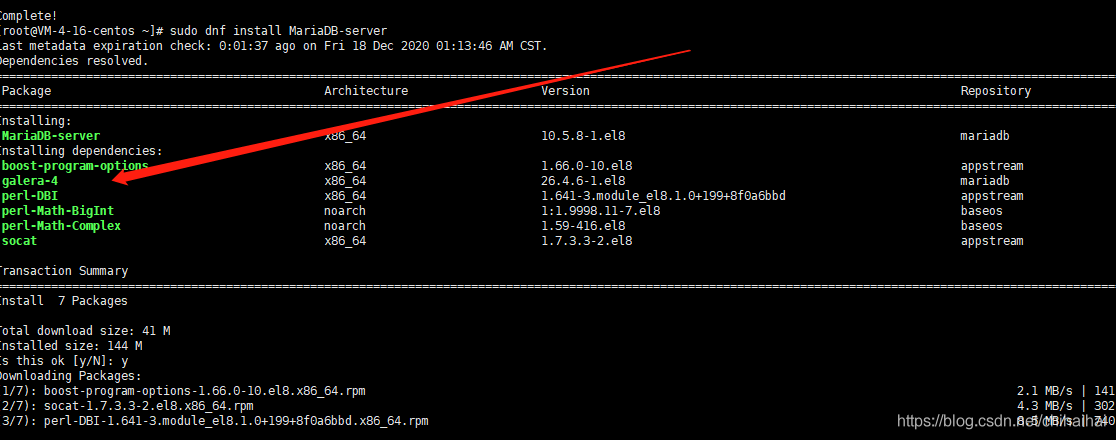
新版本直接将glera加在了安装包中不再需要我们单独安装,成功安装后就可以正常启动了
3.启动初始化并创建授权用户
systemctl start mariadb #启动mariadb systemctl enable mariadb #设置开机自启动 systemctl stop mariadb #停止MariaDB systemctl restart mariadb #重启MariaDB mysql_secure_installation #设置root密码等相关 mysql -uroot -p #测试登录 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY '你的密码' WITH GRANT OPTION; 允许远程访问 flush privileges; 刷新权限
在成功启动后我们需要创建一个用于集群间远程访问的用户这个用户将在后面你的集群配置中用到,用来建立互相访问验证
GRANT ALL PRIVILEGES ON *.* TO 'galera_chihai'@'%'IDENTIFIED BY 'xxx' WITH GRANT OPTION;
角色添加成功

后面我们要用到MariaDB-backup需要单独安装,MariaDB-backup相对于默认的rsync和 mysqldump, xtrabackup, xtrabackup-v2等方案都有长足的优势这也是官方目前推荐的方式。
是在mysql的Percona Xtrabackup 2.3.8 备份工具进行的升级与改进。mariadb-backup是官方目前最推崇的同步解决方案,如果为了追求稳定也可以直接使用rsync。
详情参阅官网:
https://mariadb.com/kb/en/mariabackup-overview/
MariaDB 10.1 introduced features that are exclusive to MariaDB, such as InnoDB Page Compression and Data-at-Rest
Encryption. These exclusive features have been very popular with MariaDB users. However, existing backup solutions
from the MySQL ecosystem, such as Percona XtraBackup, did not support full backup capability for these features.To address the needs of our users, we decided to develop a backup solution that would fully support these popular
MariaDB-exclusive features. We did this by creating Mariabackup, which is based on the well-known and commonly
used backup tool called Percona XtraBackup. Mariabackup was originally extended from version 2.3.8.
sudo yum install MariaDB-backup

三、加入配置参数启动集群
1.添加配置
10.5.8版本目录结构如下:
官方镜像配置文件目录结构:/etc/mysql /etc/mysql |-- conf.d | |-- docker.cnf | |-- mysqld_safe_syslog.cnf |-- debian-start |-- debian.cnf |-- mariadb.cnf |-- mariadb.conf.d |-- my.cnf
下面是我测试用的简单配置文件,单独创建一个用于glera集群的配置文件置于/etc/my.cnf.d中即可
这里官方给出了几个必填参数:
地址:https://mariadb.com/kb/en/configuring-mariadb-galera-cluster/#mandatory-options

这里需要注意的一点是在设定了binlog_format=ROW后必须要设置log-bin否则系统会发出警告。
配置中如果不需要自定义端口的话4567可以省略。其余配置自行根据自己机器情况配置
[galera] binlog_format=ROW log-bin=mysql-bin default-storage-engine=innodb innodb_autoinc_lock_mode=2 bind-address=0.0.0.0 wsrep_on=ON wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_name=mariadb wsrep_cluster_address="gcomm://39.107.xx.xx:4567,120.26.xx.xx:4567,42.192.xx.xx:4567" wsrep_node_name=controller-88 wsrep_node_address=42.192.53.88 wsrep_sst_auth=sst:sstpass123 wsrep_sst_method=rsync wsrep_causal_reads=ON wsrep_slave_threads=4 wsrep_certify_nonPK=1 wsrep_max_ws_rows=131072 wsrep_max_ws_size=1073741824 wsrep_debug=0 wsrep_convert_LOCK_to_trx=0 wsrep_retry_autocommit=1 wsrep_auto_increment_control=1 wsrep_drupal_282555_workaround=0 wsrep_causal_reads=0 wsrep_notify_cmd=
2.重新启动集群节点
这里需要注意版本不同启动命令也有区别,自己需留意自己使用的版本。只有第一个主节点启动的时候需要加入下面步骤,其余节点正常启动即可。
第一个节点 sudo galera_new_cluster 其余节点 systemctl restart mariadb
如果是云服务器默认情况下确保自己的如下端口都已经开放,涉及到的端口:
- 4444:请求SST(全量同步),在新节点加入时起作用
- 4568:传输IST(增量同步),节点下线,重启加入时起作用
- 4567:组成员之间沟通的端口
到这里我们先看下集群状态看看当前这一个节点是否已经配置成功 ```bash show status like '%wsrep%';
可以看到当前节点已经成功加入集群,我们重复前面的工作在另外两台服务器上配置相应的环境。
这里如果只有一台主机的话就按多实例的方式来配置

紧接着剩余机器重复上述步骤即可,但是切记后面不再需要启动new-cluster。
踩坑规避:
1.需要修改open-file-limit参数,很多时候默认的最大可打开文件数是不够用的这个时候会直接导致启动失败。首先需要查看linux本身的配置情况,更改/etc/security/limits.conf :这个文件规定了上限。修改后再去修改/usr/lib/systemd/system下两个mariadb.service和mairadb@.service中的配置信息即可。直接在mysql配置文件中修改你会发现并不起作用,因为这里的配置参数优先级更高覆盖掉了你的配置
2.这里再贴出一个我本人亲自经历的天坑,很多时候集群武器第一个成功立马启动,但是第二个节点开始glera状态一切正常查看节点信息也成功加入到集群中,但是mariadb服务无法启动netsate -anpt查看3306端口并没有启动。因为我所有数据库都是新创建的所以不存在同步数据需要很久的情况,但是再等待了十来分钟后依然会发现mysql无法连接没有启动,glera集群一切正常。这个时候查询日志也找不到什么关键错误信息误以为是哪里出问题了就被我手动关闭准备重新构建,但是万万忽略了机器本身的性能。因为我测试使用的是3台最垃圾的1核2g的学生机,忽略了这个问题导致误判启动时间。遇到3306没起来glera正常又没有报错的情况只需要耐心多等待一会即可。同时这里还有一个问题因为我3台测试机有两台是centos8,一台centos7。两个系统也有明显的差别,7比8启动快了很多。这里的原因需要打个问号可能是多方原因。如果需要同步的数据量很大sst超时,则记得在配置中修改超时时间
四、 测试
show status like ‘%wsrep%’;

这里我们新建一个数据库看一下是否能同步成功:

当你测试数据能真正同步成功这一步才算大功告成。搭建期间基本把能踩的坑踩了一遍很痛苦,后续有遇到问题的朋友可以留言一起探讨。下一步我们就该为集群搭建负载均很的配置了。
五、ProxySql
1.安装:
这里我直接使用了我当前环境提供的默认版本2.0.9,大家可以自行选择适合的版本。
在ProxySQL V2.0.0 以上版本可以原生支持 galera 集群,不再需要 scheduler 调度程序中使用外部脚本。
yum install proxysql -y
官网galera中使用教程地址:https://proxysql.com/blog/effortlessly-scaling-out-galera-cluster-with-proxysql/
2.结构
proxysql的目录结构:
数据目录:/var/lib/proxysql/
proxysql.db:配置数据存储文件,后端数据库的账号、密码、路由等存储在这个数据库里面。proxysql.log:此文件是日志文件。proxysql.pid:此文件是是进程pid文件。
配置文件目录:/etc/proxysql.cnf,是一些静态配置项,用来配置一些启动选项。此配置文件只在第一次启动的时候读取进行初始化,后面只读取proxysql.db文件。
启动脚本:/etc/init.d/proxysql
proxysql 的默认管理端口是 6032,客户端服务端口是 6033。默认的用户名密码都是 admin,可以在配置文件里看到。
ProxySQL默认有五个数据库:

对每个库的功能介绍如下:
- main库:
- disk库:
- stats库:
- monitor库:
可见有五个库: main、disk、stats 、monitor 和 stats_history
main:内存配置数据库,表里存放后端 db 实例、用户验证、路由规则等信息。表名以runtime_开头的表示 proxysql 当前运行的配置内容,不能通过 dml 语句修改,只能修改对应的不以runtime_ 开头的(在内存)里的表,然后LOAD使其生效, SAVE使其存到硬盘以供下次重启加载。main 库中有如下信息:
库下的主要表:
mysql_servers: 后端可以连接 MySQL 服务器的列表mysql_users: 配置后端数据库的账号和监控的账号。mysql_query_rules: 指定 Query 路由到后端不同服务器的规则列表。
注: 表名以 runtime_开头的表示 ProxySQL 当前运行的配置内容,不能通过 DML 语句修改。
只能修改对应的不以 runtime 开头的表,然后 “LOAD” 使其生效,“SAVE” 使其存到硬盘以供下次重启加载。
disk:是持久化到硬盘的配置库,对应/var/lib/proxysql/proxysql.db文件,也就是 sqlite 的数据文件。stats:是 proxysql 运行抓取的统计信息库,包括到后端各命令的执行次数、流量、processlist、查询种类汇总/执行时间等等。monitor:存储 monitor 模块收集的信息,主要是对后端 db 的健康、延迟检查。stats_history: 这个库是 ProxySQL 收集的有关其内部功能的历史指标
3.启动:
systemctl start proxysql.service netstat -anlp | grep proxysql 查看下是否启动成功

4.连接
使用MySQL客户端连接管理:
mysql -uadmin -padmin -h127.0.0.1 -P 6032
但是这个默认的用户只能在本地使用。如果想要远程连接到ProxySQL,例如用windows上的navicat连接Linux上的ProxySQL管理接口,必须自定义一个管理员账户。
配置 ProxySQL 所需账户:
在 Master 的MySQL 上创建 ProxySQL 的监控账户和对外访问账户
#proxysql 的监控账户 create user 'monitor'@'%' identified by '199651ch'; grant all privileges on *.* to 'monitor'@'%' with grant option; #proxysql 的对外访问账户 create user 'proxysql'@'xxx' identified by 'xxxx'; grant all privileges on *.* to 'xxx'@'xxx' with grant option;
5.配置信息介绍
配置结构如下:

整套配置系统分为三层:顶层为 RUNTIME ,中间层为 MEMORY , 底层也就是持久层 DISK 和 CONFIG FILE 。
RUNTIME:代表 ProxySQL 当前生效的正在使用的配置,无法直接修改这里的配置,必须要从下一层 “load” 进来。MEMORY:MEMORY 层上面连接 RUNTIME 层,下面连接持久层。这层可以正常操作 ProxySQL 配置,随便修改,不会影响生产环境。修改一个配置一般都是现在 MEMORY 层完成的,确认正常之后在加载达到 RUNTIME 和 持久化的磁盘上。
DISK 和 CONFIG FILE:持久化配置信息,重启后内存中的配置信息会丢失,所需要将配置信息保留在磁盘中。重启时,可以从磁盘快速加载回来。
要重新配置 MySQL 用户,可执行下面的其中一个命令: 1、LOAD MYSQL USERS FROM MEMORY / LOAD MYSQL USERS TO RUNTIME 将内存数据库中的配置加载到 runtime 数据结构,反之亦然。 2、SAVE MYSQL USERS TO MEMORY / SAVE MYSQL USERS FROM RUNTIME 将 MySQL 用户从 runtime 持久化到内存数据库。 3、LOAD MYSQL USERS TO MEMORY / LOAD MYSQL USERS FROM DISK 从磁盘数据库中加载 MySQL 用户到内存数据库中。 4、SAVE MYSQL USERS FROM MEMORY / SAVE MYSQL USERS TO DISK 将内存数据库中的 MySQL 用户持久化到磁盘数据库中。 5、LOAD MYSQL USERS FROM CONFIG 从配置文件中加载 MySQL 用户到内存数据库中。 要处理 MySQL server: 1、LOAD MYSQL SERVERS FROM MEMORY / LOAD MYSQL SERVERS TO RUNTIME 将 MySQL server 从内存数据库中加载到 runtime。 2、SAVE MYSQL SERVERS TO MEMORY / SAVE MYSQL SERVERS FROM RUNTIME 将 MySQL server 从 runtime 持久化到内存数据库中。 3、LOAD MYSQL SERVERS TO MEMORY / LOAD MYSQL SERVERS FROM DISK 从磁盘数据库中加载 MySQL server 到内存数据库。 4、SAVE MYSQL SERVERS FROM MEMORY / SAVE MYSQL SERVERS TO DISK 从内存数据库中将 MySQL server 持久化到磁盘数据库中。 5、LOAD MYSQL SERVERS FROM CONFIG 从配置文件中加载 MySQL server 到内存数据库中 要处理 MySQL 的查询规则(mysql query rules): 1、 LOAD MYSQL QUERY RULES FROM MEMORY / LOAD MYSQL QUERY RULES TO RUNTIME 将 MySQL query rules 从内存数据库加载到 runtime 数据结构。 2、 SAVE MYSQL QUERY RULES TO MEMORY / SAVE MYSQL QUERY RULES FROM RUNTIME 将 MySQL query rules 从 runtime 数据结构中持久化到内存数据库。 3、 LOAD MYSQL QUERY RULES TO MEMORY / LOAD MYSQL QUERY RULES FROM DISK 从磁盘数据库中加载 MySQL query rules 到内存数据库中。 4、 SAVE MYSQL QUERY RULES FROM MEMORY / SAVE MYSQL QUERY RULES TO DISK 将 MySQL query rules 从内存数据库中持久化到磁盘数据库中。 5、 LOAD MYSQL QUERY RULES FROM CONFIG 从配置文件中加载 MySQL query rules 到内存数据库中。 要处理 MySQL 变量(MySQL variables): 1、 LOAD MYSQL VARIABLES FROM MEMORY / LOAD MYSQL VARIABLES TO RUNTIME 将 MySQL variables 从内存数据库加载到 runtime 数据结构。 2、 SAVE MYSQL VARIABLES TO MEMORY / SAVE MYSQL VARIABLES FROM RUNTIME 将 MySQL variables 从 runtime 数据结构中持久化到内存数据中。 3、 LOAD MYSQL VARIABLES TO MEMORY / LOAD MYSQL VARIABLES FROM DISK 从磁盘数据库中加载 MySQL variables 到内存数据库中。 4、 SAVE MYSQL VARIABLES FROM MEMORY / SAVE MYSQL VARIABLES TO DISK 将 MySQL variables 从内存数据库中持久化到磁盘数据库中。 5、 LOAD MYSQL VARIABLES FROM CONFIG 从配置文件中加载 MySQL variables 到内存数据库中。 要处理管理变量(admin variables): 1、 LOAD ADMIN VARIABLES FROM MEMORY / LOAD ADMIN VARIABLES TO RUNTIME 将 admin variables 从内存数据库加载到 runtime 数据结构。 2、 SAVE ADMIN VARIABLES TO MEMORY / SAVE ADMIN VARIABLES FROM RUNTIME 将 admin variables 从 runtime 持久化到内存数据库中。 3、 LOAD ADMIN VARIABLES TO MEMORY / LOAD ADMIN VARIABLES FROM DISK 从磁盘数据库中加载 admin variables 到内存数据库中。 4、 SAVE ADMIN VARIABLES FROM MEMORY / SAVE ADMIN VARIABLES TO DISK 将 admin variables 从内存数据库中持久化到磁盘数据库。 5、 LOAD ADMIN VARIABLES FROM CONFIG 从配置文件中加载 admin variables 到内存数据库中。
ProxySQL配置文件的修改流程一般是:
1、第一次启动时候,修改必要的CONFIG FILE配置。
2、以后配置修改MEMORY中的表,然后加载到RUNTIME并保存到DISK持久化。
这里有几个最常用的命令:如何让修改的配置生效(runtime),以及如何持久化到磁盘上(disk)。记住,只要不是加载到 runtime,修改的配置就不会生效。
LOAD MYSQL USERS TO RUNTIME; 将内存数据库中的配置加载到 runtime 数据结构 SAVE MYSQL USERS TO DISK; 将内存数据库中的 MySQL 用户持久化到磁盘数据库中。 LOAD MYSQL SERVERS TO RUNTIME; 将 MySQL server 从内存数据库中加载到 runtime。 SAVE MYSQL SERVERS TO DISK; 从内存数据库中将 MySQL server 持久化到磁盘数据库中。 LOAD MYSQL QUERY RULES TO RUNTIME; 将 MySQL query rules 从内存数据库加载到 runtime 数据结构。 SAVE MYSQL QUERY RULES TO DISK; 将 MySQL query rules 从内存数据库中持久化到磁盘数据库中。 LOAD MYSQL VARIABLES TO RUNTIME; 将 MySQL variables 从内存数据库加载到 runtime 数据结构。 SAVE MYSQL VARIABLES TO DISK; 将 MySQL variables 从内存数据库中持久化到磁盘数据库中。 LOAD ADMIN VARIABLES TO RUNTIME; 将 admin variables 从内存数据库加载到 runtime 数据结构。 SAVE ADMIN VARIABLES TO DISK; 将 admin variables 从内存数据库中持久化到磁盘数据库。 注意:只有加载到 runtime 状态时才会去做最后的有效性验证。在保存到内存数据库或持久化到磁盘上时,都不会发生任何警告或错误。当 加载到 runtime 时,如果出现错误,将恢复为之前保存得状态,这时可以去检查错误日志。
disk and config file 持久化配置文件
disk -> 是sqlite3 数据库 ,默认位置是$DATADIR/proxysql.db( /var/lib/proxysql/proxysql.db)
config file 是一个传统配置文件:一般不更改
在内存中动态更改配置,如果重启,没进行持久化(save) 则会丢失。
三则之间关系:
proxysql 启动时,首先去找/etc/proxysql.cnf 找到它的datadir,如果datadir下有proxysql.db 就加载proxysql.db的配置
如果启动proxysql时带有–init标志,会用/etc/proxsql.cnf的配置,把Runtime,disk全部初始化一下。
再调用时调用–reload 会把/etc/proxysql.cnf 和disk 中配置进行合并。如果冲突需要用户干预。disk会覆盖config file。
关于传统的配置文件:
传统配置文件默认路径为/etc/proxysql.cnf,也可以在二进制程序proxysql上使用-c或–config来手动指定配置文件。
默认情况下:几乎不需要手动去配置proxysql.cnf。端口号,管理proxysql用户名,密码,可以在这里修改。
6.实际应用中修改配置
1.设置读写服务器mariadb参数
这里由于我只启动了三个节点的原因,所以测试环境直接配置为两主一从,实际生产环境下配置为两主两从会更好点增加节点容错性。首先需要确定mysql读服务器已进行相应配置,对其中两个读节点进行设置为1。写设置为0
set global read_only=1; 只读 set global read_only=0; 读写

7.创建 ProxySQL 监控用户
要在 ProxySQL 中启用对后端节点的监视,需要创建一个具有USAGE权限的用户,并在 ProxySQL 中配置该用户。为 ProxySQL 配置监控账号:
set mysql-monitor_username='monitor'; set mysql-monitor_password='xxx';
上面这两句是修改变量的方式还可以在main库下面用sql语句方式修改
UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_username'; UPDATE global_variables SET variable_value='xxx' WHERE variable_name='mysql-monitor_password';
修改后,保存到runtime和disk
load mysql variables to runtime; save mysql variables to disk;
8.创建 ProxySQL 客户端用户
ProxySQL 必须具有可以访问后端节点的用户。要添加用户需要在mysql_users表中插入,首先在后端服务器创建用户,主要根据实际业务需求创建用户
show create table mysql_users\G;

配置mysql_users 表,将proxysql用户添加到该表中。
-- 这个用户默认指向写组 2
insert into mysql_users (username,password,default_hostgroup) values ('proxysql','xxxx',2);
load mysql users to runtime;
save mysql users to disk;

重要字段说明
username # 前端应用连接ProxySQL,以及 ProxySQL 将 SQL 语句路由给后端 MySQL 所使用的用户名。 password # 对应的密码。可以是明文密码也可以是 hash 密码。如果使用hash密码,先在后端某个 MySQL 节点上执行 select password(PASSWORD),然后将加密结果复制到该字段。 default_hostgroup # 该用户默认的路由目标。例如,指定 root 用户的该字段值为 1 时,则使用 root 用户发送的 SQL 语句默认将路由到 hostgroup_id=1 组中的某个节点上。 active: 1 # 1 代表用户生效,0 代表不生效 default_schema # 登录后端默认连接的数据库,为 NULL 时则由全局变量 mysql-default_schema 决定 transaction_persistent # 值为 1 时,表示事务持久化:当某连接使用该用户开启了一个事务后,那么在事务提交/回滚之前,所有的语句都路由到同一个组中,避免语句分散到不同组
9.将集群节点添加到ProxySQL
ProxySQL 使用 hostgroups 配置后端节点的组群。就可以通过将不同类型的流量路由到不同的组来平衡群集中的负载。可以通过多种方式配置主机组(例如主从,读写组),每个后端节点可以配置在多个组中。在 ProxySQL 中添加后端 MySQL 集群节点,需要在mysql_servers表中插入相应的记录,其中hostgroup_id为2是写组、3是读组:

INSERT INTO mysql_servers ( hostgroup_id, hostname, PORT, weight ) values (2,'42.192.53.88',3306,100),(3,'39.107.143.191',3306,100),(3,'120.26.161.80',3306,100); 注:严格需要写明comment load mysql servers to runtime; save mysql servers to disk;
添加了节点,三台机器都是online 状态

对心跳信息的监控(ping指标的监控):
SELECT * FROM monitor.mysql_server_ping_log ORDER BY time_start_us DESC LIMIT 10;
配置后如果connect_error的结果为NULL则表示正常。

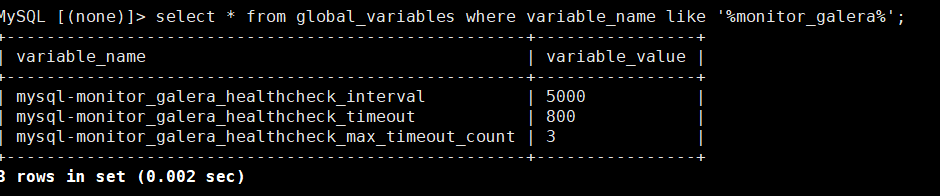
查看控制超时和检查间隔时间的全局变量:
select * from global_variables where variable_name like '%monitor_galera%';
10.配置 ProxySQL 上关于 Galera 集群的规则
用于定义 galera 集群的mysql_galera_hostgroups表的定义:
使用show create table mysql_galera_hostgroups\G命令查看表结构。
writer_hostgroup # 定义写入主机组的ID backup_writer_hostgroup # 定义备份写入组的 ID,如果是多主模式运行,写入节点数量大于 max_writers,权重低的主机就被放入该值定义的组中。 reader_hostgroup # 定义读取主机组ID。 offline_hostgroup # 当监控主机处于脱机状态时,就放入 offline_hostgroup 定义的组中。 active # 启用配置(0 或 1)。 max_writers # 限制写入主机数,大于此值就被放入 backup_writer_hostgroup 定义的组中。 writer_is_also_reader # 启用后,写入组的节点也属于读取主机组。(0 或 1) max_transactions_behind # 防止读取的后端主机有延迟数据,延迟事务数超过此值就避开此节点。延迟事务数由 wsrep_local_recv_queue 查询。 comment # 备注信息。

官方文档:https://github.com/sysown/proxysql/wiki/Main-(runtime)#mysql_galera_hostgroups
添加galera服务器配置:
INSERT INTO mysql_galera_hostgroups ( writer_hostgroup, backup_writer_hostgroup, reader_hostgroup, offline_hostgroup, active, max_writers, writer_is_also_reader, max_transactions_behind )
VALUES
( 2, 4, 3, 1, 1, 1, 0, 100 );
-- 加载配置和持久化:
load mysql servers to runtime;
save mysql servers to disk;

查看配置
select * from mysql_servers; select * from runtime_mysql_servers; select * from mysql_galera_hostgroups;
统计MySQL连接池信息:
select * from stats.stats_mysql_connection_pool;
11.配置路由规则
路由规则官网文档:https://github.com/sysown/proxysql/wiki/Main-(runtime)#mysql_query_rules
配置读写分离,就是配置ProxySQL 路由规则,ProxySQL 的路由规则非常灵活,可以基于用户,基于schema,以及单个sql语句实现路由规则定制。
注意: 我这只是试验,只是配置了几个简单的路由规则,实际情况配置路由规则,不应该是就根据所谓的读、写操作来进行读写分离,而是从收集(慢日志)的各项指标找出压力大,执行频繁的语句单独写规则,做缓存等等。比如 先在测试几个核心sql语句,分析性能提升的百分比,在逐渐慢慢完善路由规则。
和查询规则有关的表有两个:mysql_query_rules和mysql_query_rules_fast_routing
表mysql_query_rules_fast_routing是mysql_query_rules的扩展,并在以后评估快速路由策略和属性(仅在ProxySQL 1.4.7+中可用)。
介绍一下改表mysql_query_rules的几个字段:
rule_id # 规则ID active # 激活此条规则 match_digest # SQL匹配正则 destination_hostgroup # 匹配的规则路由到此主机组 apply # 配置为1表示规则不匹配后继续匹配其他规则。
这里我创建两个规则:
1、把所有以select 开头的语句全部分配到读组中,读组编号是20
2、把 select … for update 语句,这是一个特殊的select语句,会产生一个写锁(排他锁),把他分到编号为10 的写组中,其他所有操作都会默认路由到写组中
INSERT INTO mysql_query_rules ( rule_id, active, match_digest, destination_hostgroup, apply ) VALUES ( 1, 1, '^SELECT.*', 3, 1 ), ( 2, 1, '^SELECT.* FOR UPDATE$', 2, 1 ); load mysql query rules to runtime; save mysql query rules to disk;
查看集群中每个节点的状态:
select * from mysql_server_galera_log order by time_start_us desc limit 3;
select … for update规则的rule_id必须要小于普通的select规则的rule_id,因为ProxySQL是根据rule_id的顺序进行规则匹配的。
CREATE USER 'proxysql'@'%' IDENTIFIED BY 'xxxx'; GRANT USAGE ON *.* TO 'proxysql'@'%'; FLUSH PRIVILEGES;
测试读写分离:

我们向测试数据库表中插入一条数据试试:

成功插入
我们再进行查询看看到底使用了那个节点:

如果想在 ProxySQL 中查看SQL请求路由信息stats_mysql_query_digest
select hostgroup,schemaname,username,digest_text,count_star from stats_mysql_query_digest;
从结果来看跟我们预期的一样,查询跟插入分别使用了读写组中的节点

count_start 统计sql 语句次数,可以分析哪些 sql ,频繁执行
读写分离设置成功后,还可以调权重,比如让某台机器承受更多的读操作
update mysql_servers set weight=10 hostname='xxxx'; load mysql servers to runtime; save mysql servers to disk;
总结
在实际生产中我们这样简单的环境是远远不够的,起码需要ProxySQL Cluster双节点集群环境,两个节点间数据自动同步。最后就可以结合Keepalived,利用VIP资源漂移来实现ProxySQL双节点的无感知故障切换,即对外提供一个统一的vip地址,并且在keepalived.conf文件中配置proxysql服务的监控脚本,当宕机或proxysql服务挂掉时就将vip资源漂移到另一个正常的节点上,从而使proxysql的代理层持续无感应地提供服务。来保证我们服务的高可用性。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
mysql的集群模式 galera-cluster部署详解
一: galera-cluster 的介绍 Galera Cluster是Codership公司开发的一套免费开源的高可用方案,官网为http://galeracluster.com.Galera Cluster即为安装了Galera的Mariadb集群(本文只介绍Mariadb Garela集群).其本身具有multi-master特性,支持多点写入.Galera Cluster的三个(或多个)节点是对等关系,每个节点均支持写入,集群内部会保证写入数据的一致性与完整性,具体实现原理会在本篇中做
-

构建双vip的高可用MySQL集群
目录 一. 项目描述: 二.项目环境: 二.项目步骤: 三.项目概念图: 四.部署zabbix监控系统 4.1 准备: 4.2 步骤: 五.项目心得: 一. 项目描述: 本项目的目的是: 构建一个高可用的能实现读写分离的高效的MySQL集群 确保业务的稳定,能沟通方便的监控整个集群 同时能批量的去部署和管理整个集群. 二.项目环境: 8台服务器(2G,2核),centos7.8 mysql5.7.30 mysqlrouter8.0.21 keepalived2.0.10 zabbix a
-
MySQL Router实现MySQL的读写分离的方法
1.简介 MySQL Router是MySQL官方提供的一个轻量级MySQL中间件,用于取代以前老版本的SQL proxy. 既然MySQL Router是一个数据库的中间件,那么MySQL Router必须能够分析来自前面客户端的SQL请求是写请求还是读请求,以便决定这个SQL请求是发送给master还是slave,以及发送给哪个master.哪个slave.这样,MySQL Router就实现了MySQL的读写分离,对MySQL请求进行了负载均衡. 因此,MySQL Router的前提是后端
-
mariadb集群搭建---Galera Cluster+ProxySQL教程
目录 前言 一.Galera Cluster 二.基础环境搭建 三.加入配置参数启动集群 四. 测试 五.ProxySql 总结 前言 本篇主要用于记录mariaDb环境下Galera Cluster模式集群环境的搭建过程,只做演示中间参数可能会有不当地方需自行调整. 案例所采用的的是最新10.5.8版本,Mariadb10.1以后的版本中MariaDB Galera Cluste不再单独发行,而是以galera-25.3.12-2.el7.x86_64包的形式出现.如果是10.0以下版本需要另
-
Redis 集群搭建和简单使用教程
前言 Redis集群搭建的目的其实也就是集群搭建的目的,所有的集群主要都是为了解决一个问题,横向扩展. 在集群的概念出现之前,我们使用的硬件资源都是纵向扩展的,但是纵向扩展很快就会达到一个极限,单台机器的Cpu的处理速度,内存大小,硬盘大小没办法一直满足需求,而且机器纵向扩展的成本是相当高的.集群的出现就是能够让多台机器像一台机器一样工作,实现了资源的横向扩展. Redis是内存型数据库,当我们要存储的数据达到一定程度时,单台机器的内存满足不了我们的需求,搭建集群则是一种很好的解决方案. 介绍安
-
Redis的Cluster集群搭建的实现步骤
目录 一.引言 二.Redis的Cluster模式介绍 1.Redis群集101 2.Redis群集TCP端口 3.Redis集群和Docker 4.Redis集群数据分片 5.Redis集群之主从模型 6.Redis集群一致性保证 7.Redis群集配置参数 三.创建和使用Redis群集 四.使用创建群集脚本创建Redis群集 五.测试故障转移 六.手动故障转移 七.总结 一.引言 本文档只对Redis的Cluster集群做简单的介绍,并没有对分布式系统的所涉及到的概念做深入的探讨.本文只是针
-
Docker微服务的ETCD集群搭建教程详解
目录 etcd的特性 Etcd构建自身高可用集群主要有三种形式 本次搭建的基础环境 1.将服务器挨个添加进集群 2.将服务器统一添加进集群 etcd api接口 服务注册与发现 etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现.etcd是由CoreOS开发并维护的,灵感来自于 ZooKeeper 和 Doozer,它使用Go语言编写,并通过Raft一致性算法处理日志复制以保证强一致性.Raft是一个来自Stanford的新的一致性算法,适用于分布式系统的日志复制,Raft通过选举的
-
redis集群搭建教程及遇到的问题处理
这里,在一个Linux虚拟机上搭建6个节点的redis伪集群,思路很简单,一台虚拟机上开启6个redis实例,每个redis实例有自己的端口.这样的话,相当于模拟出了6台机器了,然后在以这6个实例组建redis集群就可以了. 前提:redis已经安装,目录为/usr/local/redis-4.0.1 如不会,可以参考一下文章 windows下安装redis Linux下安装redis redis集群是用的ruby脚本,所以要想执行该脚本,需要ruby环境..对应redis的源码src目
-
docker redis5.0 cluster集群搭建的实现
系统环境:ubuntu16.04LTS 本文是使用 6 个 docker 容器搭建单机集群测试,实际环境如果是多台,可对应修改容器数量.端口号和集群 ip 地址,每台机器都按下面步骤同样操作即可. 拉取redis官方镜像 docker pull redis:5.0 创建配置文件和数据目录 创建目录 mkdir ~/redis_cluster cd ~/redis_cluster 新建一个模板文件sudo vim redis_cluster.tmpl,填入如下内容: # redis端口 port
-
Redis Cluster 集群搭建你会吗
三台机器 201.202.203,每台机器装两个 redis 实例,构建 redis cluster 集群. 1. 安装 添加 redis-cluster 目录,将 redis 压缩包拷贝到该目录下,解压压缩包. 解压完后,将文件夹 redis-5.0.3 重命名为 redis1. [root@test201 redis-cluster]# mv redis-5.0.3 redis1 需要在 redis1 目录下使用 make 命令进行编译. [root@test201 redis-cluste
-
Redis Cluster集群收缩主从节点详细教程
目录 1.Cluster集群收缩概念 2.将6390主节点从集群中收缩 2.1.计算需要分给每一个节点的槽位数 2.2.分配1365个槽位给192.168.81.210的6380节点 2.3.分配1365个槽位给192.168.81.220的6380节点 2.4.分配1365个槽位给192.168.81.230的6380节点 2.5.查看当前集群槽位分配 3.验证数据迁移过程是否导致数据异常 4.将下线的主节点从集群中删除 4.1.删除节点 4.2.调整主从交叉复制 4.3.当节点存在数据无法删
-
分布式Redis Cluster集群搭建与Redis基本用法
目录 Redis集群搭建 Redis是啥 集群(Cluster) RedisCluster说明 RedisCluster节点 RedisCluster集群模式 不能保证一致性 创建和使用Redis集群 部署三个主节点 非docker docker安装 创建集群 Redis入门 Redis中的数据类型 字符串(string) 哈希(Hash) 列表(Lists) 集合(Set) 有序集合(sortedset) Redis 集群搭建 Redis 是啥 Redis(全称 REmote DIctiona
-
redis 分片集群搭建与使用教程
目录 前言 搭建集群架构图 前置准备 搭建步骤 创建集群 Redis散列插槽说明 集群伸缩(添加节点) 故障转移 使用redistemplate访问分片集群 前言 redis可以说在实际项目开发中使用的非常频繁,在redis常用集群中,我们聊到了redis常用的几种集群方案,不同的集群对应着不同的场景,并且详细说明了各种集群的优劣,本篇将以redis 分片集群为切入点,从redis 分片集群的搭建开始,详细说说redis 分片集群相关的技术点: 单点故障: 单机写(高并发写)瓶颈: 单机存储数据