C#中Linq的去重方式Distinct详解
前天在做批量数据导入新增时,要对数据进行有效性判断,其中还要去除重复,如果没出现linq的话可能会新声明一个临时对象集合,然后遍历原始数据判断把符合条件的数据添加到临时集合中,这在有了linq之后显得比较麻烦。
一、首先创建一个控制台应用程序,添加一个Person对象
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Compare
{
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
public Person(string name, int age)
{
this.Name = name;
this.Age = age;
}
}
}
二、创建测试数据
创建了一个Name="ZhangSan"的Person对象,放入personList两次,然后personList又创建了几个Person对象,这几个Person对象中也有Name、Age都重复的。例如:"XiaoMing",26.
Person person = new Person("ZhangSan",26);
List<Person> personList = new List<Person>() {
person,
new Person("XiaoMing",25),
new Person("CuiYanWei",25),
new Person("XiaoMing",26),
new Person("XiaoMing",25),
new Person("LaoWang",26),
new Person("XiaoMing",26),
person
};
三、测试
下面的代码中用了两种方式来选择不重复的数据。
List<Person> defaultDistinctPersons = personList.Distinct().ToList<Person>();
foreach (Person p in defaultDistinctPersons)
{
Console.WriteLine("Name:{0} Age:{1}",p.Name,p.Age);
}
Console.WriteLine("-----------------------------------------------------");
List<Person> comparePersons = personList.Distinct(new PersonCompare()).ToList<Person>();
foreach (Person p in comparePersons)
{
Console.WriteLine("Name:{0} Age:{1}", p.Name, p.Age);
}
Console.ReadLine();
在华丽分割线上面是使用默认的distinct,下面是通过集成IEqualityComparer接口。下面是实现接口的代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Compare
{
public class PersonCompare:IEqualityComparer<Person>
{
public bool Equals(Person x, Person y)
{
if (x == null || y == null)
return false;
return x.Name.Equals(y.Name) && x.Age == y.Age;
}
public int GetHashCode(Person obj)
{
return obj.GetHashCode();
}
}
}
在上面的代码中,继承IEqualityComparer接口,主要是实现了两个方法:bool Equals(T x, T y);int GetHashCode(T obj);可能即使实现了接口也不了解里面是怎么个原理,我们先看下运行结果。
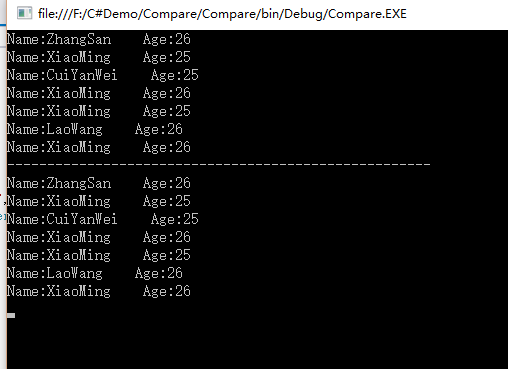
从上面的运行结果可以看到,两个运行结果是一样的,还是有重复的数据:例如XiaoMing,26.两个都没去除重复,只有ZhangSan那两个去除重复了。是不是有实现接口多此一举的感觉。那为什么还要有这个接口还要实现它呢?其实要说下GetHashCode和Equals。
在说GetHashCode和Equals之前先了解下distinct(),这个方法Distinct 默认比较的是对象的引用,所以使用默认的distinct()方法是ZhangSan对象是过滤除去的,而XiaoMing,26是两个不同的对象,没有除去。
然后说下GetHashCode和Equals两个方法.
1.哈希码哈希代码是一个用于在相等测试过程中标识对象的数值。它还可以作为一个集合中的对象的索引。如果两个对象的 Equals 比较结果相等,则每个对象的 GetHashCode 方法都必须返回同一个值。 如果两个对象的比较结果不相等,这两个对象的 GetHashCode 方法不一定返回不同的值.
简而言之,如果你发现两个对象 GetHashCode() 的返回值相等,那么这两个对象就很可能是同一个对象;但如果返回值不相等,这两个对象一定不是同一个对象.
当GetHashCode可以直接分辨出不相等时,Equals就没必要调用了,而当GetHashCode返回相同结果时,Equals方法会被调用从而确保判断对象是否真的相等。所以,还是那句话:GetHashCode没必要一定把对象分辨得很清楚(况且它也不可能,一个int不可能代表所有的可能出现的值),有Equals在后面做保障。GetHashCode仅需要对对象进行快速判断。
上面的几句算是总结性的说明了两个方法的是怎么个路子,这也能解释出ZhangSan的重复去除,而其他的几个对象没有去重复的原因,ZhangSan那是一个对象,其他的虽然Name、Age相等,但不是同一个对象。
我们可以稍微改动下代码来验证上面的语句.在实现IEqualityComparer的接口类中打印出一些信息就能看明白
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Compare
{
public class PersonCompare:IEqualityComparer<Person>
{
public bool Equals(Person x, Person y)
{
if (x == null || y == null)
return false;
Console.WriteLine("XName:{0} XAge:{1} XHashCode:{2} YName:{3} YAge:{4} YHashCode:{5}", x.Name, x.Age, x.GetHashCode(),y.Name,y.Age,y.GetHashCode());
return x.Name.Equals(y.Name) && x.Age == y.Age;
}
public int GetHashCode(Person obj)
{
Console.WriteLine("GetHashCode Name:{0} Age:{1} HashCode:{2}",obj.Name,obj.Age,obj.GetHashCode());
return obj.GetHashCode();
}
}
}
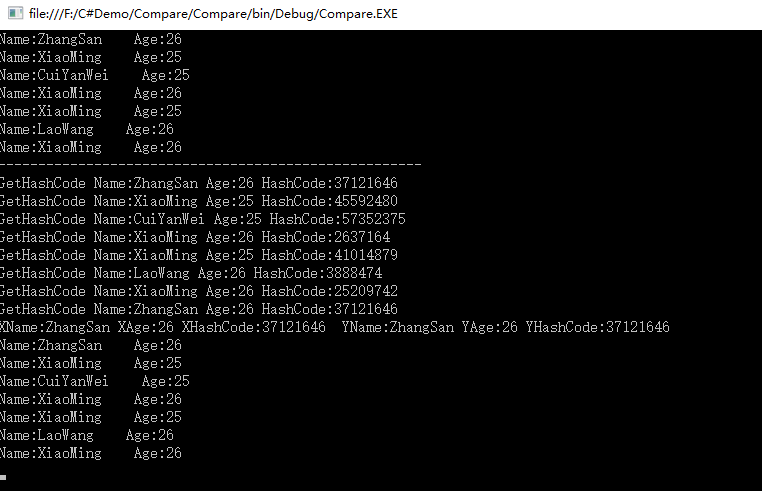
在GetHashCode中打印了对象的Name、Age和HashCode。可以看到HashCode只有ZhangSan的是相同的,在Equals方法中只打印出了ZhangSan的,还是因为上面的先判断HashCode,相等了再使用Equals判断。
我们再改动下实现IEqualityComparer的接口类
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Compare
{
public class PersonCompare:IEqualityComparer<Person>
{
public bool Equals(Person x, Person y)
{
if (x == null || y == null)
return false;
Console.WriteLine("XName:{0} XAge:{1} XHashCode:{2} YName:{3} YAge:{4} YHashCode:{5}", x.Name, x.Age, x.GetHashCode(), y.Name, y.Age, y.GetHashCode());
return x.Name.Equals(y.Name) && x.Age == y.Age;
}
public int GetHashCode(Person obj)
{
//Console.WriteLine("GetHashCode Name:{0} Age:{1} HashCode:{2}",obj.Name,obj.Age,obj.GetHashCode());
//return obj.GetHashCode();
string s = string.Format("{0}_{1}",obj.Name,obj.Age);
Console.WriteLine("Name:{0} Age:{1} HashCode:{2}",obj.Name,obj.Age, s.GetHashCode());
return s.GetHashCode();
}
}
}
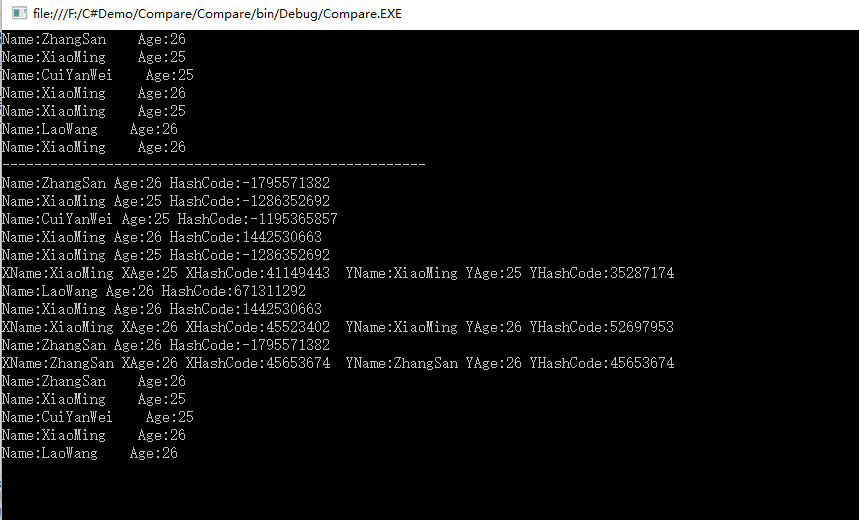
根据上面的的代码和测试结果我们可以看到,GetHashCode执行了7次(7个对象),Equals执行了3次,因为ZhangSan,26和XiaoMing,25两个的哈希码是一样的就没有继续往下执行。
到此这篇关于Linq之Distinct详解的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
全面分析c# LINQ
大家好,这是 [C#.NET 拾遗补漏] 系列的第 08 篇文章,今天讲 C# 强大的 LINQ 查询.LINQ 是我最喜欢的 C# 语言特性之一. LINQ 是 Language INtegrated Query 单词的首字母缩写,翻译过来是语言集成查询.它为查询跨各种数据源和格式的数据提供了一致的模型,所以叫集成查询.由于这种查询并没有制造新的语言而只是在现有的语言基础上来实现,所以叫语言集成查询. 一些基础 在 C# 中,从功能上 LINQ 可分为两类:LINQ to Object 和 L
-

C#笔记之EF Code First 数据模型 数据迁移
目录 一.EF的创建 二.修改数据库 一.加数据库字段 二.加数据库 表 EF的基本使用 一.EF的创建二.修改数据库一.加数据库字段二.加数据库 表 一.EF的创建 第一步: 创建一个类库 第二步: 选择类库 第三步:选择ADO.NET 实体数据模型,名称和你数据库名字对应,我的叫LetDB 第四步:出现了窗体 先解释一下这些EF模型: 1.来自数据库的EF设计器: 先有数据库,根据数据库生成模型 2.空EF设计模型: 模型优先,通过设计的模型生成数据库 3.空 Code First 模型:
-
C# EF去除重复列DistinctBy方式
目录 C# EF去除重复列DistinctBy C#集合用Distinct去掉重复的元素,IEqualityComparer<T>原理 json测试数据 实体类型 总结 C# EF去除重复列DistinctBy 在网上看了LinQ有DistinctBy方法,实际在用的时候并没有找到,后来参照了该网站才发现写的是拓展方法 https://www.jb51.net/article/273355.htm 1.添加一个扩展方法 public static class DistinctByCla
-
C#中Linq的去重方式Distinct详解
前天在做批量数据导入新增时,要对数据进行有效性判断,其中还要去除重复,如果没出现linq的话可能会新声明一个临时对象集合,然后遍历原始数据判断把符合条件的数据添加到临时集合中,这在有了linq之后显得比较麻烦. 一.首先创建一个控制台应用程序,添加一个Person对象 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;
-
Spring中Bean的命名方式代码详解
本文主要描述的是关于spring中bean的命名方式,通过简单实例向大家介绍了六种方式,具体如下. 一般情况下,在配置一个Bean时需要为其指定一个id属性作为bean的名称.id在IoC容器中必须是唯一的,此外id的命名需要满足xml对id的命名规范. 在实际情况中,id命名约束并不会给我们带来影响.但是如果用户确实希望用到一些特殊字符来对bean进行命名,那么可以使用bean的name属性来进行命名,name属性没有字符上的限制,几乎可以使用任何字符. 每个Bean可以有一个或多个id,我们
-
Java中对象的序列化方式克隆详解
Java 序列化技术可以使你将一个对象的状态写入一个Byte 流里,并且可以从其它地方把该Byte 流里的数据读出来,重新构造一个相同的对象. 简述: 用字节流的方式,复制Java对象 代码: 流克隆复制函数 public static Object deepClone(Object obj){ if(obj == null){ return null; } try { ByteArrayOutputStream byteOut = new ByteArrayOutputStream(); Ob
-
JS中多种方式创建对象详解
1.内置对象创建 var girl=new Object(); girl.name='hxl'; console.log(typeof girl); 2.工厂模式,寄生构造函数模式 function Person(name){ var p=new Object();//内部进行实例化 p.name=name; p.say=function(){ console.log('my name is '+ p.name); } return p;//注:一定要返回 } var girl=Person('
-
Android 中倒计时验证两种常用方式实例详解
Android 中倒计时验证两种常用方式实例详解 短信验证码功能,这里总结了两种常用的方式,可以直接拿来使用.看图: 说明:这里的及时从10开始,是为了演示的时间不要等太长而修改的. 1.第一种方式:Timer /** * Description:自定义Timer * <p> * Created by Mjj on 2016/12/4. */ public class TimeCount extends CountDownTimer { private Button button; //参数依
-
Spring 3.x中三种Bean配置方式比较详解
以前Java框架基本都采用了XML作为配置文件,但是现在Java框架又不约而同地支持基于Annotation的"零配置"来代替XML配置文件,Struts2.Hibernate.Spring都开始使用Annotation来代替XML配置文件了:而在Spring3.x提供了三种选择,分别是:基于XML的配置.基于注解的配置和基于Java类的配置. 下面分别介绍下这三种配置方式:首先定义一个用于举例的JavaBean. package com.chinalife.dao public cl
-
JS中原始值和引用值的储存方式示例详解
在ECMAscript中,变量可以存放两种类型的值,即原始值和引用值 原始值指的是代表原始数据类型的值,也叫基本数据类型,包括:Number.Stirng.Boolean.Null.Underfined 引用值指的是复合数据类型的值,包括:Object.Function.Array.Date.RegExp 根据数据类型不同,有的变量储存在栈中,有的储存在堆中.具体区别如下: 原始变量及他们的值储存在栈中,当把一个原始变量传递给另一个原始变量时,是把一个栈房间的东西复制到另一个栈房间,且这两个原始
-
Python中lru_cache的使用和实现详解
在计算机软件领域,缓存(Cache)指的是将部分数据存储在内存中,以便下次能够更快地访问这些数据,这也是一个典型的用空间换时间的例子.一般用于缓存的内存空间是固定的,当有更多的数据需要缓存的时候,需要将已缓存的部分数据清除后再将新的缓存数据放进去.需要清除哪些数据,就涉及到了缓存置换的策略,LRU(Least Recently Used,最近最少使用)是很常见的一个,也是 Python 中提供的缓存置换策略. 下面我们通过一个简单的示例来看 Python 中的 lru_cache 是如何使用的.
-
Java8利用Stream实现列表去重的方法详解
目录 一. Stream 的distinct()方法 1.1 对于 String 列表的去重 1.2 对于实体类列表的去重 二. 根据 List<Object> 中 Object 某个属性去重 2.1 新建一个列表出来 2.2 通过 filter() 方法 一. Stream 的distinct()方法 distinct()是Java 8 中 Stream 提供的方法,返回的是由该流中不同元素组成的流.distinct()使用 hashCode() 和 eqauls() 方法来获取不同的元素.
-
Java实现List去重的方法详解
目录 简介 直接去重 根据对象属性去重 法1:TreeSet 法2:stream+TreeSet 所有代码 简介 本文用示例介绍Java的List(ArrayList.LinkedList等)的去重的方法. List去重的方法 一共有这几种方法(按推荐顺序排列): JDK8的stream的distinct 转为HashSet(分不保持顺序和保持顺序两种) 转为TreeSet 使用retainAll/removeAll.contains.equals等基本方法 直接去重 package com.e