Python RawString与open文件的newline换行符遇坑解决
目录
- 背景
- 思路
- 遇到的问题
- 思考过程
- Raw String
- 如果字符串没转义字符,那么 Raw String 跟普通 String 完全一致
- 误区:注意单个字符的引号问题
- 启发
- 正则替换的问题
- open 文件的 newline 参数
背景
一次工作中,我需要完成某个文件的字符串替换。
需求是这样的:文件A有个占位符,需要利用Python3,把占位符替换成文件B的内容。文件都不大,可以一次性读到内存处理。
我想,这不是简单的open read replace write就搞定了嘛?
结果,还真有点麻烦!
思路
- 全量读取文件A,保存到变量templace
- 全量读取文件B,保存到变量text
- 利用python的
re.sub实现正则替换,保存到新变量result - 把变量result内容写入文件A
with open('A', encoding='utf8') as f:
template = f.read()
with open('B', encoding='utf8') as f:
text = f.read()
result = re.sub(r'占位标识符', text, template, 1)
with open('A', 'w', encoding='utf8') as f:
f.write(result)
遇到的问题
文件B内有换行符,也有字符串\n,按上文的方式处理后,所有的字符串\n都变成了换行符!
举个例子,template是我是:{}(其中{}就是占位符),text是下面的文本:
哈哈 哈哈\n哈哈
替换后,如下图所示:
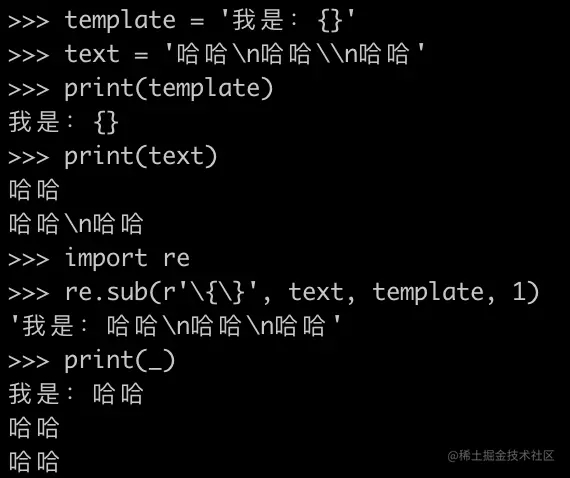
可以看到,当我打印re.sub结果时,所有的\n都变成了换行符,字符串\n消失了!
这的确令人烦躁,本来五分钟可以搞定,结果要花多余的时间处理这个问题。如果你学会了本文,以后都不用再去费脑筋了~
思考过程
一开始遇到这个问题,是在写入文件后发现的,所以并没定位的这么准确,当时跟换行符相关的,我怀疑了以下方面:
- 字符串定义没有使用 Raw String(例如
r'xxx'这种方式)。 - 正则替换出了问题。
- 写入文件时,
newline参数导致。
如果我们能把这3个问题全都弄清楚,以后定位就非常快了!
Raw String
Python中,如果字符串常量的定义前加了个r,就表示 Raw String 原始字符串。
Raw String 特点在于,字符串常量里的\将不具有转义作用,它仅仅代表它自己。
例如,你定义个普通字符串"\n",这个字符串长度其实是1,它只包含了1个换行符,对应的 ASCII 是10。
如果你定义了原始字符串"\n",这个字符串长度就是2,它包含了字符\和字符n。
如果字符串没转义字符,那么 Raw String 跟普通 String 完全一致
转义字符有这些:
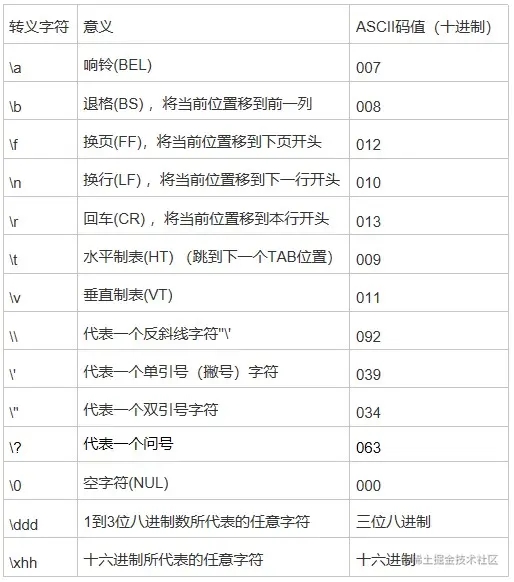
也就是说r'\haha'跟'\haha'是完全一致的,因为\h不是转义字符,所以这种情况下,没必要加r。

误区:注意单个字符的引号问题
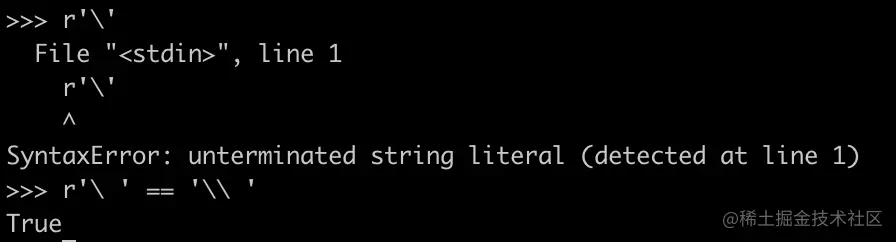
有一个令人疑惑的点:理论上讲,r'\'应该就是'\\',但是当你使用r'\'时,Python会报错。
这是因为Python在编译时,读取字符串时,如果字符串以单引号开头,遇到\'后,不论你是不是Raw String,都会继续认为是字符串,不会把'当作结束符。估计是一个历史遗留问题。我们只能接受现实。
如何证明呢?你给字符后面加个空格,发现它们是相等的:r'\ '和'\\ '。但是单独的字符r'\'就报错了。
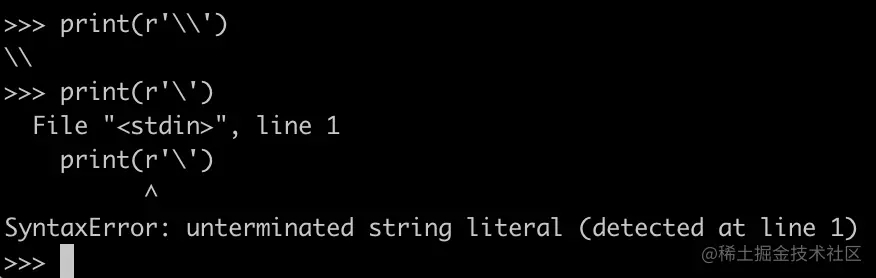
但是这种情况只有r'\'或r"\"才会发生,如果字符串长度为2,是没问题的,例如r"\\"可以被合法定义。
启发
定义字符串时,如果你是这么定义:"哈哈\n哈哈",那么这个字符串长度是5,包含了1个换行符。
如果你是这么定义:r"哈哈\n哈哈",那么这个字符串长度是6,不包含换行符,包含字符\和n。
同样,当你写入文件时,如果是f.write('\n'),就表明写入了换行符,但如果是f.write(r'\n'),就表明写入了字符串"\n"。
正则替换的问题
这是导致本文问题的根本原因。使用re.sub时,所有的字符串r"\n"都被当作了换行符。
怎么办呢?
只要我们替换前,把原始文件对应的字符串的r"\n"都改为r"\\n",手动多加了一次转义符,那么re.sub时,就不会把r"\n"当作一个整体改成换行符了,反而会把r"\\"当作一个整体,替换为字符\。这样r"\n"字符串就保留下来了!当然,其它转义字符,也统统保留下来了。这就是正确的解法了。
open 文件的 newline 参数
with open(filename, 'r', newline=None) as f: f.read()
这个主要是因为不同操作系统的换行符不同,所以有了这个参数。Windows 是 CRLF 即 \r\n,Unix 是 LF 即\n,旧版 Macintosh 是 CR 即\r。
通常情况下,我们不需要加这个参数,Python 会自动为我们做这些事情:
- 读取文件时,自动把文本中的各种换行符统一转换为
"\n"。 - 写入文件时,根据当前的操作系统,自动把
"\n"转换为对应的换行符,通过os.linesep可以查看当前操作系统换行符。
当然,你也可以主动设置 newline 参数:
- 读取文件时,如果 newline 是空字符串
'',则Python不会做任何自动转换,读到什么就是什么。 - 读取文件时,如果 newline 是非空字符串,则Python会把换行符转化为这个非空字符串,例如你可以指定为
'\r'或'\r\n'或其它。 - 写入文件时,如果 newline 是空字符串
'',则Python不会做任何自动转换,现在换行符是什么,就写入什么。 - 写入文件时,如果 newline 是非空字符串,则Python会把
\n转化为这个非空字符串,例如你可以指定为'\r'或'\r\n'或其它。
注意,newline 参数只对文本文件有效,如果是二进制读写,newline 是无用的。
其实,大部分时候我们无需关注这个 newline 参数。
以上就是Python RawString与open文件的newline换行符遇坑解决的详细内容,更多关于Python RawString open文件 newline换行符的资料请关注我们其它相关文章!
相关推荐
-
python3 读写文件换行符的方法
最近在处理文本文件时,遇到编码格式和换行符的问题. 基本上都是GBK 和 UTF-8 编码的文本文件,但是python3 中默认的都是按照 utf-8 来打开.用不正确的编码参数打开,在读取内容时,会抛出异常. open(dirpath + "\\" + file, mode = "r+", encoding = "gbk", newline = "") 捕获抛出的异常,关闭文件.使用另外一种编码格式打开文件再重新读取. 读取
-

python open函数中newline参数实例详解
目录 问题的由来 具体实例 总结 问题的由来 我在读pythoncsv模块文档 看到了这样一句话 如果 csvfile 是文件对象,则打开它时应使用 newline=‘’.其备注:如果没有指定 newline=‘’,则嵌入引号中的换行符将无法正确解析,并且在写入时,使用 \r\n 换行的平台会有多余的 \r 写入.由于 csv 模块会执行自己的(通用)换行符处理,因此指定 newline=‘’ 应该总是安全的. 我就在思考open函数中的newline参数的作用,因为自己之前在使用open函数时
-
Python 整行读取文本方法并去掉readlines换行\n操作
我就废话不多说了,大家还是直接看代码吧~ import os path="dir/dir" # 目录 files=os.listdir(path) # 读取该下的所有文本 for i in files: f1 = open(dic_path + i,"r") data = f1.read().splitlines() for j in data: print(j) 补充知识:Python 三种读文件方法read(), readline(), readlines()及
-
python使用正则表达式匹配txt特定字符串(有换行)
在原txt文件中,我们需要匹配出的字符串为:休闲服务(中间参杂着换行) 直接复制到notebook里进行处理 ①发现需要拿出的字符串都在证卷研究报告前,第一步就把证券报告前面的所有内容全部提出来(包括换行) ②发现需要的字符串在两个换行符(\n)的中间,再对其进行处理 完整代码 import re txt = """ 行业报告 | 行业点评 休闲服务 证券研究报告""" result = re.findall(r"([\s\S]*)证券
-
对于Python中RawString的理解介绍
总结 1.'''作用: 可以表示 "多行注释" ."多行字符串" ."其内的单双引号不转义" 2.r 代表的意思是: raw 3.r 只对其内的反斜杠起作用(注意单个 \ 的问题) raw string 有什么用处呢? raw string 就是会自动将反斜杠转义. >>> print('\n') >>> print(r'\n') \n >>> (注:出现了两个空行是因为 print() 会自
-
python实现去除空格及tab换行符的方法
目录 1.先放个大招:去除字符串中所有的空格和tab换行符 2.strip()方法,去除字符串开头或者结尾的空格 3.lstrip()方法,去除字符串开头的空格 4.rstrip()方法,去除字符串结尾的空格 5.replace()方法,去除字符串全部的空格 1.先放个大招:去除字符串中所有的空格和tab换行符 str=" a b c de f " print(str.replace(" ","").replace("\n",
-
Python RawString与open文件的newline换行符遇坑解决
目录 背景 思路 遇到的问题 思考过程 Raw String 如果字符串没转义字符,那么 Raw String 跟普通 String 完全一致 误区:注意单个字符的引号问题 启发 正则替换的问题 open 文件的 newline 参数 背景 一次工作中,我需要完成某个文件的字符串替换. 需求是这样的:文件A有个占位符,需要利用Python3,把占位符替换成文件B的内容.文件都不大,可以一次性读到内存处理. 我想,这不是简单的open read replace write就搞定了嘛? 结果,还真有
-
Bash技巧:把变量赋值为换行符(判断文件是否以换行符结尾)
变量赋值为换行符 在 bash 中,如果要把变量赋值为换行符,写为 '\n' 没有效果,需要写为 $'\n'.具体举例如下: $ newline='\n' $ echo $newline \n $ newline=$'\n' $ echo $newline 可以看到,把 newline 变量赋值为 'n',得到的是 n 这个字符串,而不是换行符自身. 这是 bash 和 C 语言不一样的地方. 在 C 语言中,'n' 对应换行符自身,只有一个字符:而 "n" 对应一个字符串. 但是在
-
Java读文件修改默认换行符的实现
目录 Java读文件修改默认换行符 方法如下 Java替换换行符 Java读文件修改默认换行符 Java默认换行符是'\n'.但有时数据并不以'\n'进行换行 方法如下 public static void testRead(String confPath) throws IOException { System.setProperty("line.separator", "/03"); BufferedReader brConf = new BufferedRea
-
PHP按行读取文件时删除换行符的3种方法
PHP按行读取文件 去掉换行符"\n": 第一种: 复制代码 代码如下: $content=str_replace("\n","",$content);echo $content; 或者: 复制代码 代码如下: $content=str_replace(array("\n","\r"),"",$content); 第二种: 复制代码 代码如下: $content=preg_replace
-
python中关于py文件之间相互import的问题及解决方法
目录 问题背景 实例演示 问题背景 调试脚本时,遇到一个问题:ImportError: cannot import name 'A' from 'study_case.a' (/Users/rchera/PycharmProjects/test/study_case/a.py) 具体情况是这样婶儿的: 前些日子写了一个py文件,它的功能主要是创建数据(暂且称为create_data.py,每条数据会生成一个唯一的id): 同时写了另一个py文件,它的功能主要是操作数据,例如对数据进行编辑.删除等
-
bat和python批量重命名文件的实现代码
最近从某网站下载了一批文档,但是文件是用数字串命名的文档(很多图书馆都这样吧),现在我也下载完了这些文件,也有这些文件的列表,就是不能一个一个的把文件给重命名吧所以从网上找了这几个脚本. 一.使用bat脚本(windows系统默认可用) 打开记事本,将这些代码写入记事本,另存为xx.bat文件(注意后缀名,很多小白保存成了xx.bat.txt,因为txt是隐藏的,以为不行) @echo off for /r "d:\pdf" %%a in (*.pdf) do ( for /f &qu
-
python按行读取文件,去掉每行的换行符\n的实例
如下所示: for line in file.readlines(): line=line.strip('\n') 以上这篇python按行读取文件,去掉每行的换行符\n的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Python处理文本换行符实例代码 Python按行读取文件的简单实现方法 python去掉行尾的换行符方法 Python实现读取文件最后n行的方法 python去除空格和换行符的实现方法(推荐)
-
Python编程中的文件操作攻略
open函数 你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的辅助方法才可以调用它进行读写. 语法: file object = open(file_name [, access_mode][, buffering]) 各个参数的细节如下: file_name:file_name变量是一个包含了你要访问的文件名称的字符串值. access_mode:access_mode决定了打开文件的模式:只读,写入,追加等.所有可取值见如下的完全列表.这个参数是非强制的
-
Python实现将一个大文件按段落分隔为多个小文件的简单操作方法
本文实例讲述了Python实现将一个大文件按段落分隔为多个小文件的简单操作方法.分享给大家供大家参考,具体如下: 今天帮同学处理一点语料.语料文件有点大,并且是以连续两个换行符作为段落标志,他想把它按段落分隔成多个小文件,即每3个段落组成一个新文件.由于以前没有遇到过类似的操作,在网上找了一些相似的方法,看起来都有点复杂.所以经尝试,自己写了一段代码,完美解决问题. 基本思路是,先读原文件内容,并使用正则表达式,依据\n\n进行切片处理,结果为一个列表,其中每一个列表元素都存放一个切片中的内容;