Python sklearn分类决策树方法详解
目录
- 决策树模型
- 决策树学习
- 使用Scikit-learn进行决策树分类
决策树模型
决策树(decision tree)是一种基本的分类与回归方法。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
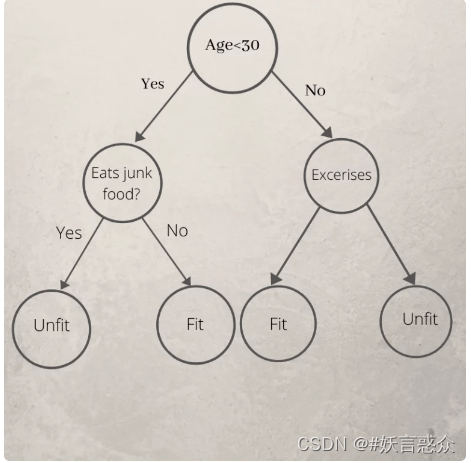
用于预测一个人是否肥胖或不肥胖的决策树
决策树学习
决策树学习算法包括3部分:特征选择、树的生成和树的剪枝。常用的算法有ID3、 C4.5和CART。
1、特征选择的目的在于选取对训练数据能够分类的特征。特征选择的关键是其准则。常用的准则如下:
(1)样本集合D对特征A的信息增益(ID3)
(2)样本集合D对特征A的信息增益比(C4.5)
(3)样本集合D的基尼指数(CART)
2.决策树的生成。通常使用信息增益最大、信息增益比最大或基尼指数最小作为特征选择的准则。决策树的生成往往通过计算信息增益或其他指标,从根结点开始,递归地产生决策树。这相当于用信息增益或其他准则不断地选取局部最优的特征,或将训练集分割为能够基本正确分类的子集。
3.决策树的剪枝。由于生成的决策树存在过拟合问题,需要对它进行剪枝,以简化学到的决策树。决策树的剪枝,往往从已生成的树上剪掉一些叶结点或叶结点以上的子树,并将其父结点或根结点作为新的叶结点,从而简化生成的决策树。
使用Scikit-learn进行决策树分类
import numpy as np
from sklearn.datasets import load_iris
from sklearn import tree
import matplotlib.pyplot as plt
iris=load_iris()
print(iris.feature_names)
print(iris.target_names)
#划分数据集
removed =[0,50,100]
new_target = np.delete(iris.target,removed)
new_data = np.delete(iris.data,removed, axis=0)
#训练分类器
clf = tree.DecisionTreeClassifier() # 定义决策树分类器
clf=clf.fit(new_data,new_target)
prediction = clf.predict(iris.data[removed])
print("Original Labels",iris.target[removed])
print("Labels Predicted",prediction)
#绘制决策树
plt.figure(figsize=(15, 10))
tree.plot_tree(clf, feature_names=iris.feature_names, filled=True)
plt.show()

参考链接传送门
到此这篇关于Python sklearn分类决策树方法详解的文章就介绍到这了,更多相关Python sklearn决策树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python pandas 数据排序的几种常用方法
前言: pandas中排序的几种常用方法,主要包括sort_index和sort_values. 基础数据: import pandas as pd import numpy as np data = { 'brand':['Python', 'C', 'C++', 'C#', 'Java'], 'B':[4,6,8,12,10], 'A':[10,2,5,20,16], 'D':[6,18,14,6,12], 'years':[4,1,1,30,30], 'C':[8,12,18,8,2] }
-

Python sklearn库三种常用编码格式实例
目录 OneHotEncoder独热编码实例 LabelEncoder标签编码实例 OrdinalEncoder特征编码实例 OneHotEncoder独热编码实例 class sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error') 目的:将分类要素编码为one-hot数字数组
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Python sklearn转换器估计器和K-近邻算法
目录 一.转换器和估计器 1. 转换器 2.估计器(sklearn机器学习算法的实现) 3.估计器工作流程 二.K-近邻算法 1.K-近邻算法(KNN) 2. 定义 3. 距离公式 三.电影类型分析 1 问题 2 K-近邻算法数据的特征工程处理 四.K-近邻算法API 1.步骤 2.代码 3.结果及分析 五.K-近邻总结 一.转换器和估计器 1. 转换器 想一下之前做的特征工程的步骤? 1.实例化 (实例化的是一个转换器类(Transformer)) 2.调用fit_transform(对于文档
-
python sklearn与pandas实现缺失值数据预处理流程详解
注:代码用 jupyter notebook跑的,分割线线上为代码,分割线下为运行结果 1.导入库生成缺失值 通过pandas生成一个6行4列的矩阵,列名分别为'col1','col2','col3','col4',同时增加两个缺失值数据. import numpy as np import pandas as pd from sklearn.impute import SimpleImputer #生成缺失数据 df=pd.DataFrame(np.random.randn(6,4),colu
-
python机器学习sklearn实现识别数字
目录 简介 数据集 数据处理 数据分离 训练数据 数据可视化 完整代码 简介 本文主要简述如何通过sklearn模块来进行预测和学习,最后再以图表这种更加直观的方式展现出来 数据集 学习数据 预测数据 数据处理 数据分离 因为我们打开我们的的学习数据集,最后一项是我们的真实数值,看过小唐上一篇的人都知道,老规矩先进行拆分,前面的特征放一块,后面的真实值放一块,同时由于数据没有列名,我们选择使用iloc[]来实现分离 def shuju(tr_path,ts_path,sep='\t'): tra
-
python库sklearn常用操作
目录 前言 一.MinMaxScaler 前言 sklearn是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类.回归.降维以及聚类:还包含了监督学习.非监督学习.数据变换三大模块.sklearn拥有完善的文档,使得它具有了上手容易的优势:并它内置了大量的数据集,节省了获取和整理数据集的时间.因而,使其成为了广泛应用的重要的机器学习库. sklearn是一个无论对于机器学习还是深度学习都必不可少的重要的库,里面包含了关于机器学习的几乎所有需要的功能,因为sklearn库的内容
-
一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
Python sklearn分类决策树方法详解
目录 决策树模型 决策树学习 使用Scikit-learn进行决策树分类 决策树模型 决策树(decision tree)是一种基本的分类与回归方法. 分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点(leaf node).内部结点表示一个特征或属性,叶结点表示一个类. 用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子
-
python安装sklearn模块的方法详解
可直接用这行命令!: pip install -U scikit-learn 其他命令: (1)更新pip python -m pip install --upgrade pip (2)安装 scipy 在网址http://www.lfd.uci.edu/~gohlke/pythonlibs/ 中找到你需要的版本scipy 例如windows 64 位 Python2.7 对应下载:scipy-0.18.0-cp27-cp27m-win_amd64.whl cd 下载scipy 目录下,安装 p
-
python生成式的send()方法(详解)
随便在网上找了找,感觉都是讲半天讲不清楚,这里写一下. def generator(): while True: receive=yield 1 print('extra'+str(receive)) g=generator() print(next(g)) print(g.send(111)) print(next(g)) 输出: 1 extra111 1 extraNone 1 为什么会这样呢,点进send就能看到一句话 send:Resumes the generator and "sen
-
Python中格式化format()方法详解
Python中格式化format()方法详解 Python中格式化输出字符串使用format()函数, 字符串即类, 可以使用方法; Python是完全面向对象的语言, 任何东西都是对象; 字符串的参数使用{NUM}进行表示,0, 表示第一个参数,1, 表示第二个参数, 以后顺次递加; 使用":", 指定代表元素需要的操作, 如":.3"小数点三位, ":8"占8个字符空间等; 还可以添加特定的字母, 如: 'b' - 二进制. 将数字以2为基
-
对python函数签名的方法详解
函数签名对象,表示调用函数的方式,即定义了函数的输入和输出. 在Python中,可以使用标准库inspect的一些方法或类,来操作或创建函数签名. 获取函数签名及参数 使用标准库的signature方法,获取函数签名对象:通过函数签名的parameters属性,获取函数参数. # 注意是小写的signature from inspect import signature def foo(value): return value # 获取函数签名 foo_sig = signature(foo)
-
把JSON数据格式转换为Python的类对象方法详解(两种方法)
JOSN字符串转换为自定义类实例对象 有时候我们有这种需求就是把一个JSON字符串转换为一个具体的Python类的实例,比如你接收到这样一个JSON字符串如下: {"Name": "Tom", "Sex": "Male", "BloodType": "A", "Hobbies": ["篮球", "足球"]} 我需要把这个转换为具
-
对python 自定义协议的方法详解
前面说到最近在写python的一些东西,然后和另外一位小伙伴定义了协议,然后昨天我有一部分东西没理解对,昨天上午我自己重写了一遍接收和发送的全部逻辑,昨天下午补了压力测试的脚本,自测没问题之后告知联调的小伙伴. 结果上午还是出了一点问题,然后我们两对代码,他写了一个python的实现.还好最后我这边没问题.(我也害怕是我这边出问题啊,所以我自己的代码都自己检查了好几遍) 简单放一下他的实现: import struct import ctypes class E(Exception): def
-
Python底层封装实现方法详解
这篇文章主要介绍了Python底层封装实现方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 事实上,python封装特性的实现纯属"投机取巧",之所以类对象无法直接调用私有方法和属性,是因为底层实现时,python偷偷改变了它们的名称. python在底层实现时,将它们的名称都偷偷改成了"_类名__属性(方法)名"的格式 class Person: def setname(self, name): if le
-
python集合删除多种方法详解
这篇文章主要介绍了python集合删除多种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 删除指定的元素 A={'a','c','b','d','e'} print("原集合:",A) A.remove('a') # 不存在会报错 print("删除a后:",A) A.discard('b') # 不存在不会报错 print("删除b后:",A) A.pop() print("
-
Python实现括号匹配方法详解
这篇文章主要介绍了python实现括号匹配方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.用一个栈[python中可以用List]就可以解决,时间和空间复杂度都是O(n) # -*- coding: utf8 -*- # 符号表 SYMBOLS = {'}': '{', ']': '[', ')': '(', '>': '<'} SYMBOLS_L, SYMBOLS_R = SYMBOLS.values(), SYMBOLS.ke