SpringBoot集成Kafka 配置工具类的详细代码
目录
- 1、单播模式,只有一个消费者组
- 2、广播模式,多个消费者组
spring-kafka 是基于 java版的 kafka client与spring的集成,提供了 KafkaTemplate,封装了各种方法,方便操作,它封装了apache的kafka-client,不需要再导入client依赖
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
YML配置
kafka:
#bootstrap-servers: server1:9092,server2:9093 #kafka开发地址,
#生产者配置
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 1 # 消息发送重试次数
#acks = 0:设置成 表示 producer 完全不理睬 leader broker 端的处理结果。此时producer 发送消息后立即开启下 条消息的发送,根本不等待 leader broker 端返回结果
#acks= all 或者-1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时还会等待所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给,消息安全但是吞吐量会比较低。
#acks = 1:默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给producer ,而无须等待其他副本写入该消息。折中方案,只要leader一直活着消息就不会丢失,同时也保证了吞吐量
acks: 1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 #批量大小
properties:
linger:
ms: 0 #提交延迟
buffer-memory: 33554432 # 生产端缓冲区大小
# 消费者配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 分组名称
group-id: web
enable-auto-commit: false
#提交offset延时(接收到消息后多久提交offset)
# auto-commit-interval: 1000ms
#当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
auto-offset-reset: latest
properties:
#消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
session.timeout.ms: 15000
#消费请求超时时间
request.timeout.ms: 18000
#批量消费每次最多消费多少条消息
#每次拉取一条,一条条消费,当然是具体业务状况设置
max-poll-records: 1
# 指定心跳包发送频率,即间隔多长时间发送一次心跳包,优化该值的设置可以减少Rebalance操作,默认时间为3秒;
heartbeat-interval: 6000
# 发出请求时传递给服务器的 ID。用于服务器端日志记录 正常使用后解开注释,不然只有一个节点会报错
#client-id: mqtt
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
#设置消费类型 批量消费 batch,单条消费:single
type: single
#指定容器的线程数,提高并发量
#concurrency: 3
#手动提交偏移量 manual达到一定数据后批量提交
#ack-mode: manual
ack-mode: MANUAL_IMMEDIATE #手動確認消息
# 认证
#properties:
#security:
#protocol: SASL_PLAINTEXT
#sasl:
#mechanism: SCRAM-SHA-256
#jaas:config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'
简单工具类,能满足正常使用,主题是无法修改的
@Component
@Slf4j
public class KafkaUtils<K, V> {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.bootstrap-servers}")
String[] servers;
/**
* 获取连接
* @return
*/
private Admin getAdmin() {
Properties properties = new Properties();
properties.put("bootstrap.servers", servers);
// 正式环境需要添加账号密码
return Admin.create(properties);
}
/**
* 增加topic
*
* @param name 主题名字
* @param partition 分区数量
* @param replica 副本数量
* @date 2022-06-23 chens
*/
public R addTopic(String name, Integer partition, Integer replica) {
Admin admin = getAdmin();
if (replica > servers.length) {
return R.error("副本数量不允许超过Broker数量");
}
try {
NewTopic topic = new NewTopic(name, partition, Short.parseShort(replica.toString()));
admin.createTopics(Collections.singleton(topic));
} finally {
admin.close();
}
return R.ok();
}
/**
* 删除主题
*
* @param names 主题名字集合
* @date 2022-06-23 chens
*/
public void deleteTopic(List<String> names) {
Admin admin = getAdmin();
try {
admin.deleteTopics(names);
} finally {
admin.close();
}
}
/**
* 查询所有主题
*
* @date 2022-06-24 chens
*/
public Set<String> queryTopic() {
Admin admin = getAdmin();
try {
ListTopicsResult topics = admin.listTopics();
Set<String> set = topics.names().get();
return set;
} catch (Exception e) {
log.error("查询主题错误!");
} finally {
admin.close();
}
return null;
}
// 向所有分区发送消息
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
return kafkaTemplate.send(topic, data);
}
// 指定key发送消息,相同key保证消息在同一个分区
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
return kafkaTemplate.send(topic, key, data);
}
// 指定分区和key发送。
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data) {
return kafkaTemplate.send(topic, partition, key, data);
}
}
发送消息 使用异步
@GetMapping("/{topic}")
public String test(@PathVariable String topic, @PathVariable Long index) throws ExecutionException, InterruptedException {
ListenableFuture future = null;
Chenshuang user = new Chenshuang(i, "陈爽", "123456", new Date());
String s = JSON.toJSONString(user);
KafkaUtils utils = new KafkaUtils();
future = kafkaUtils.send(topic, s);
// 异步回调,同步get,会等待 不推荐同步!
future.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
System.out.println("发送成功:" + result);
}
});
return "发送成功";
}
建立主题
如果broker端配置auto.create.topics.enable为true(默认为true),当收到客户端的元数据请求时则会创建topic。
向一个不存在的主题发送和消费都会创建一个新的主题,很多时候,非预期的创建主题,会导致很多意想不到的问题,建议关掉该特性。
Topic主题用来区分不同类型的消息,实际也就是适用于不同的业务场景,默认消息保存一周时间;
同一个Topic主题下,默认是一个partition分区,也就是只能有一个消费者来消费,如果想提升消费能力,就需要增加分区;
同一个Topic的多个分区,可以有三种方式分派消息(key,value)到不同的分区,指定分区、HASH路由、默认,同一个分区内的消息ID唯一,并顺序;
消费者消费partition分区内的消息时,是通过offsert来标识消息的位置;
GroupId用来解决同一个Topic主题下重复消费问题,比如一条消费需要多个消费者接收到,就可以通过设置不同的GroupId实现,
实际消息是存一份的,只是通过逻辑上设置标识来区分,系统会记录Topic主题下–》GroupId分组下–》partition分区下的offsert,来标识是否消费过。
发送消息的高可用—
集群模式,多副本方式实现;一条消息的提交,可能通过设置acks标识实现不同的可用性,=0时,发送成功就OK;=1时,master成功响应才OK,=all时,一半以上的响应才OK(真正的高可用)
消费消息的高可用—
可以关闭自动标识offsert模式,先拉取消息,消费完成后,再去设置offsert位置,来解决消费高可用
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaTopic {
// yml自定义主题,项目启动就创建,
@Value("${spring.kafka.topic}")
String topic;
@Value("${spring.kafka.bootstrap-servers}")
String[] server;
/**
* 项目启动 初始化主题,如果存在不会覆盖主题的
*/
@Bean
public NewTopic batchTopic() {
// 最大复制因子 <= 经纪人broker数量.
return new NewTopic(topic, 10, (short) server.length);
}
}
监听类 ,一条消息,各分组内的消费者只有一个消费者消费一次,如果消息在1区,指定分区1监听也会消费
也可以同个方法监听不同的主题,指定位移监听
同组会均匀消费,不同组会重复消费。
1、单播模式,只有一个消费者组
(1)topic只有1个partition,该组内有多个消费者时,此时同一个partition内的消息只能被该组中的一 个consumer消费。当消费者数量多于partition数量时,多余的消费者是处于空闲状态的,如图1所示。topic,test只有一个partition,并且只有1个group,G1,该group内有多个consumer,只能被其中一个消费者消费,其他的处于空闲状态。

图一
(2)该topic有多个partition,该组内有多个消费者,比如test 有3个partition,该组内有2个消费者,那么可能就是C0对应消费p0,p1内的数据,c1对应消费p2的数据;如果有3个消费者,就是一个消费者对应消费一个partition内的数据了。图解分别如图2,图3.这种模式在集群模式下使用是非常普遍的,比如我们可以起3个服务,对应的topic设置3个partiition,这样就可以实现并行消费,大大提高处理消息的效率。

图二

图三
2、广播模式,多个消费者组
如果想实现广播的模式就需要设置多个消费者组,这样当一个消费者组消费完这个消息后,丝毫不影响其他组内的消费者进行消费,这就是广播的概念。
(1)多个消费者组,1个partition
该topic内的数据被多个消费者组同时消费,当某个消费者组有多个消费者时也只能被一个消费者消费,如图4所示:
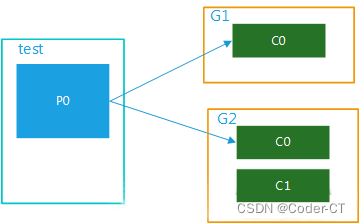
图四
(2)多个消费者组,多个partition
该topic内的数据可被多个消费者组多次消费,在一个消费者组内,每个消费者又可对应该topic内的一个或者多个partition并行消费,如图五:
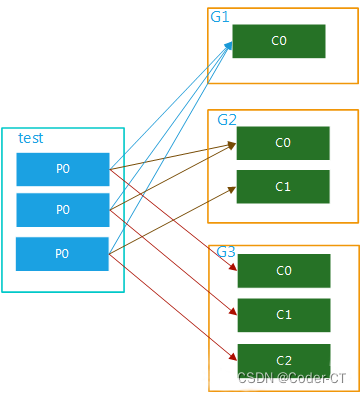
注意: 消费者的数量并不能决定一个topic的并行度。它是由分区的数目决定的。
再多的消费者,分区数少,也是浪费!
一个组的最大并行度将等于该主题的分区数。
@Component
@Slf4j
public class Consumer {
// 监听主题 分组a
@KafkaListener(topics =("${spring.kafka.topic}") ,groupId = "a")
public void getMessage(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组a
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "a")
public void getMessage2(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage3(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage4(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 指定监听分区1的消息
@KafkaListener(topicPartitions = {@TopicPartition(topic = ("${spring.kafka.topic}"),partitions = {"1"})})
public void getMessage5(ConsumerRecord message, Acknowledgment ack) {
Long id = JSONObject.parseObject(message.value().toString()).getLong("id");
//确认收到消息//确认收到消息
ack.acknowledge();
}
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* 注意:topics和topicPartitions不能同时使用;
**/
@KafkaListener(id = "c1",groupId = "c",topicPartitions = {
@TopicPartition(topic = "t1", partitions = { "0" }),
@TopicPartition(topic = "t2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})
public void getMessage6(ConsumerRecord record,Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
/**
* 批量消费监听goods变更消息
* yml配置listener:type 要改为batch
* ymk配置consumer:max-poll-records: ??(每次拉取多少条数据消费)
* concurrency = "2" 启动多少线程执行,应小于等于broker数量,避免资源浪费
*/
@KafkaListener(id="sync-modify-goods", topics = "${spring.kafka.topic}",concurrency = "4")
public void getMessage7(List<ConsumerRecord<String, String>> records){
for (ConsumerRecord<String, String> msg:records) {
GoodsChangeMsg changeMsg = null;
try {
changeMsg = JSONObject.parseObject(msg.value(), GoodsChangeMsg.class);
syncGoodsProcessor.handle(changeMsg);
}catch (Exception exception) {
log.error("解析失败{}", msg, exception);
}
}
}
}
到此这篇关于SpringBoot集成Kafka 配置工具类的文章就介绍到这了,更多相关SpringBoot集成Kafka 配置工具类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Springboot 2.x集成kafka 2.2.0的示例代码
目录 引言 基本环境 代码编写 1.基本引用pom 2.基本配置 3.实体类 4.生产者端 5.消费者 6.测试 效果展示 遇到的问题 引言 kafka近几年更新非常快,也可以看出kafka在企业中是用的频率越来越高,在springboot中集成kafka还是比较简单的,但是应该注意使用的版本和kafka中基本配置,这个地方需要信心,防止进入坑中. 版本对应地址:https://spring.io/projects/spring-kafka 基本环境 springboot版本2.1.4 kafk
-
Springboot集成Kafka实现producer和consumer的示例代码
本文介绍如何在springboot项目中集成kafka收发message. Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能.高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息.支持通过Kafka服务器和消费机集群来分区消息.支持Hadoop并行数据加载. 安装Kafka 因为安装kafka需要zookeeper的支持,所以Windows安装时需要将zookee
-
SpringBoot集成Kafka的步骤
SpringBoot集成Kafka 本篇主要讲解SpringBoot 如何集成Kafka ,并且简单的 编写了一个Demo 来测试 发送和消费功能 前言 选择的版本如下: springboot : 2.3.4.RELEASE spring-kafka : 2.5.6.RELEASE kafka : 2.5.1 zookeeper : 3.4.14 本Demo 使用的是 SpringBoot 比较高的版本 SpringBoot 2.3.4.RELEASE 它会引入 spring-kafka 2.5
-
SpringBoot整合Kafka工具类的详细代码
目录 kafka是什么? 应用场景 kafka是什么? Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素. 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决. 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案.Kafka的
-
Springboot集成Kafka进行批量消费及踩坑点
目录 引入依赖 创建配置类 Kafka 消费者 引入依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.3.11.RELEASE</version> </dependency> 因为我的项目的 springboot 版本是 1.5.22.RELE
-
SpringBoot集成Kafka 配置工具类的详细代码
目录 1.单播模式,只有一个消费者组 2.广播模式,多个消费者组 spring-kafka 是基于 java版的 kafka client与spring的集成,提供了 KafkaTemplate,封装了各种方法,方便操作,它封装了apache的kafka-client,不需要再导入client依赖 <!-- kafka --> <dependency> <groupId>org.springframework.kafka</groupId> <arti
-
springboot利用@Aspect实现日志工具类的详细代码
目录 一.导包 二.在启动类上进行注解自动扫描 三.工具类 四.结果 一.导包 <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjrt</artifactId> <version>1.8.12</version> </dependency> <dependency> <groupId>org.aspectj<
-
SpringBoot结合Redis配置工具类实现动态切换库
我使用的版本是SpringBoot 2.6.4 可以实现注入不同的库连接或是动态切换库 <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.6.4</version> </parent> <dependency> <
-
springboot集成flyway自动创表的详细配置
Flayway是一款数据库版本控制管理工具,,支持数据库版本自动升级,Migrations可以写成sql脚本,也可以写在java代码里:不仅支持Command Line和java api ,也支持Build构建工具和Spring boot,也可以在分布式环境下能够安全可靠安全地升级数据库,同时也支持失败恢复. Flyway最核心的就是用于记录所有版本演化和状态的MetaData表,Flyway首次启动会创建默认名为SCHEMA_VERSION的元素局表. 表中保存了版本,描述,要执行的sql脚本
-
SpringBoot集成kafka全面实战记录
本文是SpringBoot+Kafka的实战讲解,如果对kafka的架构原理还不了解的读者,建议先看一下<大白话kafka架构原理>.<秒懂kafka HA(高可用)>两篇文章. 一.生产者实践 普通生产者 带回调的生产者 自定义分区器 kafka事务提交 二.消费者实践 简单消费 指定topic.partition.offset消费 批量消费 监听异常处理器 消息过滤器 消息转发 定时启动/停止监听器 一.前戏 1.在项目中连接kafka,因为是外网,首先要开放kafka配置文件
-
Springboot集成kafka高级应用实战分享
目录 深入应用 1.1 springboot-kafka 1.2 消息发送 1.2.1 发送类型 1.2.2 序列化 1.2.3 分区策略 1.3 消息消费 1.3.1 消息组别 1.3.2 位移提交 深入应用 1.1 springboot-kafka 1)配置文件 kafka: bootstrap-servers: 52.82.98.209:10903,52.82.98.209:10904 producer: # producer 生产者 retries: 0 # 重试次数 acks: 1 #