Python 循环读取数据内存不足的解决方案
看代码吧~
import gc
for x in list(locals().keys())[:]:
del locals()[x]
# del all_s_x, AE, AE_split, x_ticks, split
gc.collect()
补充:Python读取大文件的"坑“与内存占用检测
python读写文件的api都很简单,一不留神就容易踩”坑“。笔者记录一次踩坑历程,并且给了一些总结,希望到大家在使用python的过程之中,能够避免一些可能产生隐患的代码。
1.read()与readlines():
随手搜索python读写文件的教程,很经常看到read()与readlines()这对函数。所以我们会常常看到如下代码:
with open(file_path, 'rb') as f:
sha1Obj.update(f.read())
or
with open(file_path, 'rb') as f:
for line in f.readlines():
print(line)
这对方法在读取小文件时确实不会产生什么异常,但是一旦读取大文件,很容易会产生MemoryError,也就是内存溢出的问题。
Why Memory Error?
我们首先来看看这两个方法:
当默认参数size=-1时,read方法会读取直到EOF,当文件大小大于可用内存时,自然会发生内存溢出的错误。

同样的,readlines会构造一个list。list而不是iter,所以所有的内容都会保存在内存之上,同样也会发生内存溢出的错误。

2.正确的用法:
在实际运行的系统之中如果写出上述代码是十分危险的,这种”坑“十分隐蔽。所以接下来我们来了解一下正确用,正确的用法也很简单,依照API之中对函数的描述来进行对应的编码就OK了:
如果是二进制文件推荐用如下这种写法,可以自己指定缓冲区有多少byte。显然缓冲区越大,读取速度越快。
with open(file_path, 'rb') as f:
while True:
buf = f.read(1024)
if buf:
sha1Obj.update(buf)
else:
break
而如果是文本文件,则可以用readline方法或直接迭代文件(python这里封装了一个语法糖,二者的内生逻辑一致,不过显然迭代文件的写法更pythonic )每次读取一行,效率是比较低的。笔者简单测试了一下,在3G文件之下,大概性能和前者差了20%.
with open(file_path, 'rb') as f:
while True:
line = f.readline()
if buf:
print(line)
else:
break
with open(file_path, 'rb') as f:
for line in f:
print(line)
3.内存检测工具的介绍:
对于python代码的内存占用问题,对于代码进行内存监控十分必要。这里笔者这里推荐两个小工具来检测python代码的内存占用。
memory_profiler
首先先用pip安装memory_profiler
pip install memory_profiler
memory_profiler是利用python的装饰器工作的,所以我们需要在进行测试的函数上添加装饰器。
from hashlib import sha1
import sys
@profile
def my_func():
sha1Obj = sha1()
with open(sys.argv[1], 'rb') as f:
while True:
buf = f.read(10 * 1024 * 1024)
if buf:
sha1Obj.update(buf)
else:
break
print(sha1Obj.hexdigest())
if __name__ == '__main__':
my_func()
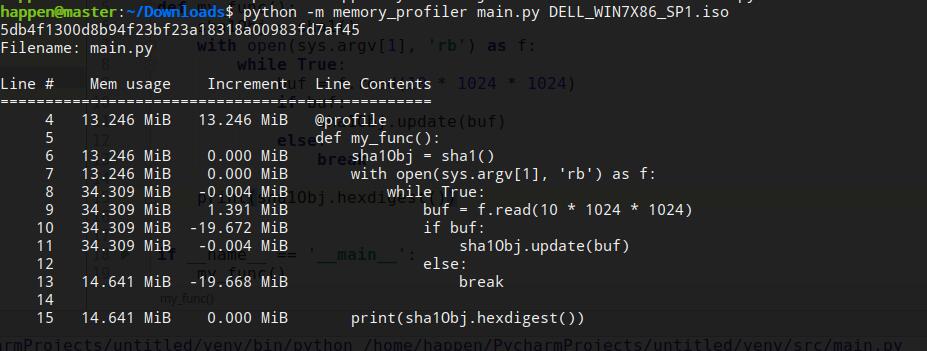
之后在运行代码时加上** -m memory_profiler**
就可以了解函数每一步代码的内存占用了
guppy
依样画葫芦,仍然是通过pip先安装guppy
pip install guppy
之后可以在代码之中利用guppy直接打印出对应各种python类型(list、tuple、dict等)分别创建了多少对象,占用了多少内存。
from guppy import hpy
import sys
def my_func():
mem = hpy()
with open(sys.argv[1], 'rb') as f:
while True:
buf = f.read(10 * 1024 * 1024)
if buf:
print(mem.heap())
else:
break
如下图所示,可以看到打印出对应的内存占用数据:
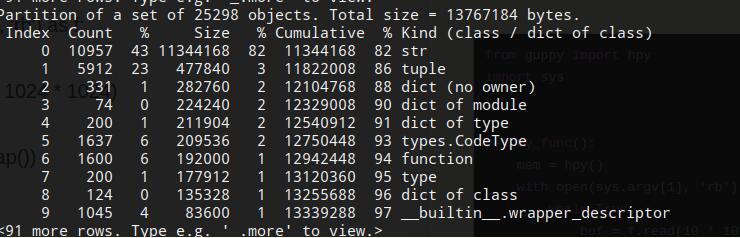
通过上述两种工具guppy与memory_profiler可以很好地来监控python代码运行时的内存占用问题。
4.小结:
python是一门崇尚简洁的语言,但是正是因为它的简洁反而更多了许多需要仔细推敲和思考的细节。希望大家在日常工作与学习之中也能多对一些细节进行总结,少踩一些不必要的“坑”。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
强悍的Python读取大文件的解决方案
Python 环境下文件的读取问题,请参见拙文 Python基础之文件读取的讲解 这是一道著名的 Python 面试题,考察的问题是,Python 读取大文件和一般规模的文件时的区别,也即哪些接口不适合读取大文件. 1. read() 接口的问题 f = open(filename, 'rb') f.read() 我们来读取 1 个 nginx 的日至文件,规模为 3Gb 大小.read() 方法执行的操作,是一次性全部读入内存,显然会造成: MemoryError ... 也即会发生内存溢出.
-

10种检测Python程序运行时间、CPU和内存占用的方法
在运行复杂的Python程序时,执行时间会很长,这时也许想提高程序的执行效率.但该怎么做呢? 首先,要有个工具能够检测代码中的瓶颈,例如,找到哪一部分执行时间比较长.接着,就针对这一部分进行优化. 同时,还需要控制内存和CPU的使用,这样可以在另一方面优化代码. 因此,在这篇文章中我将介绍7个不同的Python工具,来检查代码中函数的执行时间以及内存和CPU的使用. 1. 使用装饰器来衡量函数执行时间 有一个简单方法,那就是定义一个装饰器来测量函数的执行时间,并输出结果: import time
-
python检测空间储存剩余大小和指定文件夹内存占用的实例
1.检测指定路径下所有文件所占用内存 import os def check_memory(path, style='M'): i = 0 for dirpath, dirname, filename in os.walk(path): for ii in filename: i += os.path.getsize(os.path.join(dirpath,ii)) if style == 'M': memory = i / 1024. / 1024. print '%.2f MB' % me
-
Python 循环读取数据内存不足的解决方案
看代码吧~ import gc for x in list(locals().keys())[:]: del locals()[x] # del all_s_x, AE, AE_split, x_ticks, split gc.collect() 补充:Python读取大文件的"坑"与内存占用检测 python读写文件的api都很简单,一不留神就容易踩"坑".笔者记录一次踩坑历程,并且给了一些总结,希望到大家在使用python的过程之中,能够避免一些可能产生隐患的代
-
python 循环读取txt文档 并转换成csv的方法
如下所示: # -*- coding: utf-8 -*- """ Created on Fri Jul 29 15:49:06 2016 @author: user """ import os #从文件中读取某一行 linecache.checkcache可以刷新cache ,linecache可以缓存某一行的信息 import linecache def GetFileNameAndExt(filename): (filepath,tempf
-
python hbase读取数据发送kafka的方法
本例子实现从hbase获取数据,并发送kafka. 使用 #!/usr/bin/env python #coding=utf-8 import sys import time import json sys.path.append('/usr/local/lib/python3.5/site-packages') from thrift import Thrift from thrift.transport import TSocket from thrift.transport import
-
Python从文件中读取数据的方法步骤
一.读取整个文件内容 在读取文件之前,我们先创建一个文本文件resource.txt作为源文件. resource.txt my name is joker, I am 18 years old, How about you? 如何读取文件全部内容,我们编写到reader.py文件中. reader.py with open('resource.txt') as file_obj: content = file_obj.read() print(content) 需要注意的是需要将resourc
-
Python二进制文件读取并转换为浮点数详解
本文所用环境: Python 3.6.5 |Anaconda custom (64-bit)| 引言 由于某些原因,需要用python读取二进制文件,这里主要用到struct包,而这个包里面的方法主要是unpack.pack.calcsize.详细介绍可以看:Python Struct 官方文档.这里主要讨论,python二进制转浮点数的操作. python中一个float类型的数占4个字节. 二进制数据转float,可以用struct.unpack()来实现. 小文件读取 较小的文件,可以一次
-
基于PHP和Mysql相结合使用jqGrid读取数据并显示
jqGrid可以动态读取和加载外部数据,本文将结合PHP和Mysql给大家讲解如何使用jqGrid读取数据并显示,以及可以通过输入关键字查询数据的ajax交互过程. 下面给大家展示效果图,喜欢的朋友可以阅读全文哦. jqGrid本身带有search和edit表格模块,但是这些模块会使得整个插件体积显得有点庞大,而且笔者认为jqGrid的搜索查询和编辑/添加功能不好用,所以笔者放弃jqGrid自有的search和edit表格模块,借助jquery利器来完成相关功能,符合项目的实际应用. XHTML
-
python分块读取大数据,避免内存不足的方法
如下所示: def read_data(file_name): ''' file_name:文件地址 ''' inputfile = open(file_name, 'rb') #可打开含有中文的地址 data = pd.read_csv(inputfile, iterator=True) loop = True chunkSize = 1000 #一千行一块 chunks = [] while loop: try: chunk = dcs.get_chunk(chunkSize) chunks
-
python numpy实现多次循环读取文件 等间隔过滤数据示例
numpy的np.fromfile会出现如下的问题,只能一次性读取文件的内容,不能追加读取,连续两次的np.fromfile读到的东西一样 如果数据文件太大(几个G或以上)不能一次性全读进去,需要追加读取 而我希望读到的donser1和donser2是连续的两段 (实际使用时,比如说读取的文件是二进制数据文件,每一块文件都包括包头+数据,希望将这两块分开获取,然后再做进一步处理) 代码: import numpy as np length=2500 plt_arr=np.linspace(0.0
-
Python matplotlib读取excel数据并用for循环画多个子图subplot操作
读取excel数据需要用到xlrd模块,在命令行运行下面命令进行安装 pip install xlrd 表格内容大致如下,有若干sheet,每个sheet记录了同一所学校的所有学生成绩,分为语文.数学.英语.综合.总分 考号 姓名 班级 学校 语文 数学 英语 综合 总分 ... ... ... ... 136 136 100 57 429 ... ... ... ... 128 106 70 54 358 ... ... ... ... 110.5 62 92 44 308.5 画多张子图需要
-
Python内存泄漏和内存溢出的解决方案
一.内存泄漏 像Java程序一样,虽然Python本身也有垃圾回收的功能,但是同样也会产生内存泄漏的问题. 对于一个用 python 实现的,长期运行的后台服务进程来说,如果内存持续增长,那么很可能是有了"内存泄露". 1.内存泄露的原因 对于 python 这种支持垃圾回收的语言来说,怎么还会有内存泄露? 概括来说,有以下三种原因: 所用到的用 C 语言开发的底层模块中出现了内存泄露. 代码中用到了全局的 list. dict 或其它容器,不停的往这些容器中插入对象,而忘记了在使用完