分析从Linux源码看TIME_WAIT的持续时间
目录
- 一、前言
- 二、首先介绍下Linux环境
- 三、TIME_WAIT状态转移图
- 四、持续时间真如TCP_TIMEWAIT_LEN所定义么?
- 五、TIME_WAIT定时器源码
- 5.1、inet_twsk_schedule
- 5.2、具体的清理函数
- 5.3、先作出一个假设
- 5.4、如果一个slot中的TIME_WAIT<=100
- 5.5、如果一个slot中的TIME_WAIT>100
- 5.6、PAWS(Protection Against Wrapped Sequences)使得TIME_WAIT延长
一、前言
笔者一直以为在Linux下TIME_WAIT状态的Socket持续状态是60s左右。线上实际却存在TIME_WAIT超过100s的Socket。由于这牵涉到最近出现的一个复杂Bug的分析。所以,笔者就去Linux源码里面,一探究竟。
二、首先介绍下Linux环境
TIME_WAIT这个参数通常和五元组重用扯上关系。在这里,笔者先给出机器的内核参数设置,以免和其它问题相混淆。
cat /proc/sys/net/ipv4/tcp_tw_reuse 0
cat /proc/sys/net/ipv4/tcp_tw_recycle 0
cat /proc/sys/net/ipv4/tcp_timestamps 1
可以看到,我们设置了tcp_tw_recycle为0,这可以避免NAT下tcp_tw_recycle和tcp_timestamps同时开启导致的问题。
三、TIME_WAIT状态转移图
提到Socket的TIME_WAIT状态,不得就不亮出TCP状态转移图了:

持续时间就如图中所示的2MSL。但图中并没有指出2MSL到底是多长时间,但笔者从Linux源码里面翻到了下面这个宏定义。
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT * state, about 60 seconds */
如英文字面意思所示,60s后销毁TIME_WAIT状态,那么2MSL肯定就是60s喽?
四、持续时间真如TCP_TIMEWAIT_LEN所定义么?
笔者之前一直是相信60秒TIME_WAIT状态的socket就能够被Kernel回收的。甚至笔者自己做实验telnet一个端口号,人为制造TIME_WAIT,自己计时,也是60s左右即可回收。

但在追查一个问题时候,发现,TIME_WAIT有时候能够持续到111s,不然完全无法解释问题的现象。这就逼得笔者不得不推翻自己的结论,重新细细阅读内核对于TIME_WAIT状态处理的源码。当然,这个追查的问题也会写成博客分享出来,敬请期待_。
五、TIME_WAIT定时器源码
谈到TIME_WAIT何时能够被回收,不得不谈到TIME_WAIT定时器,这个就是专门用来销毁到期的TIME_WAIT Socket的。而每一个Socket进入TIME_WAIT时,必然会经过下面的代码分支:
tcp_v4_rcv
|->tcp_timewait_state_process
/* 将time_wait状态的socket链入时间轮
|->inet_twsk_schedule
由于我们的kernel并没有开启tcp_tw_recycle,所以最终的调用为:
/* 这边TCP_TIMEWAIT_LEN 60 * HZ */ inet_twsk_schedule(tw, &tcp_death_row, TCP_TIMEWAIT_LEN, TCP_TIMEWAIT_LEN);
好了,让我们按下这个核心函数吧。
5.1、inet_twsk_schedule
在阅读源码前,先看下大致的处理流程。Linux内核是通过时间轮来处理到期的TIME_WAIT socket,如下图所示:

内核将60s的时间分为8个slot(INET_TWDR_RECYCLE_SLOTS),每个slot处理7.5(60/8)范围time_wait状态的socket。
void inet_twsk_schedule(struct inet_timewait_sock *tw,struct inet_timewait_death_row *twdr,const int timeo, const int timewait_len)
{
......
// 计算时间轮的slot
slot = (timeo + (1 << INET_TWDR_RECYCLE_TICK) - 1) >> INET_TWDR_RECYCLE_TICK;
......
// 慢时间轮的逻辑,由于没有开启TCP\_TW\_RECYCLE,timeo总是60*HZ(60s)
// 所有都走slow_timer逻辑
if (slot >= INET_TWDR_RECYCLE_SLOTS) {
/* Schedule to slow timer */
if (timeo >= timewait_len) {
slot = INET_TWDR_TWKILL_SLOTS - 1;
} else {
slot = DIV_ROUND_UP(timeo, twdr->period);
if (slot >= INET_TWDR_TWKILL_SLOTS)
slot = INET_TWDR_TWKILL_SLOTS - 1;
}
tw->tw_ttd = jiffies + timeo;
// twdr->slot当前正在处理的slot
// 在TIME_WAIT_LEN下,这个逻辑一般7
slot = (twdr->slot + slot) & (INET_TWDR_TWKILL_SLOTS - 1);
list = &twdr->cells[slot];
} else{
// 走短时间定时器,由于篇幅原因,不在这里赘述
......
}
......
/* twdr->period 60/8=7.5 */
if (twdr->tw_count++ == 0)
mod_timer(&twdr->tw_timer, jiffies + twdr->period);
spin_unlock(&twdr->death_lock);
}
从源码中可以看到,由于我们传入的timeout皆为TCP_TIMEWAIT_LEN。所以,每次刚成为的TIME_WAIT状态的socket即将链接到当前处理slot最远的slot(+7)以便处理。如下图所示:

如果Kernel不停的产生TIME_WAIT,那么整个slow timer时间轮就会如下图所示:

所有的slot全部挂满了TIME_WAIT状态的Socket。
5.2、具体的清理函数
每次调用inet_twsk_schedule时候传入的处理函数都是:
/*参数中的tcp_death_row即为承载时间轮处理函数的结构体*/
inet_twsk_schedule(tw,&tcp_death_row,TCP_TIMEWAIT_LEN,TCP_TIMEWAIT_LEN)
/* 具体的处理结构体 */
struct inet_timewait_death_row tcp_death_row = {
......
/* slow_timer时间轮处理函数 */
.tw_timer = TIMER_INITIALIZER(inet_twdr_hangman, 0,
(unsigned long)&tcp_death_row),
/* slow_timer时间轮辅助处理函数*/
.twkill_work = __WORK_INITIALIZER(tcp_death_row.twkill_work,
inet_twdr_twkill_work),
/* 短时间轮处理函数 */
.twcal_timer = TIMER_INITIALIZER(inet_twdr_twcal_tick, 0,
(unsigned long)&tcp_death_row),
};
由于我们这边主要考虑的是设置为TCP_TIMEWAIT_LEN(60s)的处理时间,所以直接考察slow_timer时间轮处理函数,也就是inet_twdr_hangman。这个函数还是比较简短的:
void inet_twdr_hangman(unsigned long data)
{
struct inet_timewait_death_row *twdr;
unsigned int need_timer;
twdr = (struct inet_timewait_death_row *)data;
spin_lock(&twdr->death_lock);
if (twdr->tw_count == 0)
goto out;
need_timer = 0;
// 如果此slot处理的time_wait socket已经达到了100个,且还没处理完
if (inet_twdr_do_twkill_work(twdr, twdr->slot)) {
twdr->thread_slots |= (1 << twdr->slot);
// 将余下的任务交给work queue处理
schedule_work(&twdr->twkill_work);
need_timer = 1;
} else {
/* We purged the entire slot, anything left? */
// 判断是否还需要继续处理
if (twdr->tw_count)
need_timer = 1;
// 如果当前slot处理完了,才跳转到下一个slot
twdr->slot = ((twdr->slot + 1) & (INET_TWDR_TWKILL_SLOTS - 1));
}
// 如果还需要继续处理,则在7.5s后再运行此函数
if (need_timer)
mod_timer(&twdr->tw_timer, jiffies + twdr->period);
out:
spin_unlock(&twdr->death_lock);
}
虽然简单,但这个函数里面有不少细节。第一个细节,就在inet_twdr_do_twkill_work,为了防止这个slot的time_wait过多,卡住当前的流程,其会在处理完100个time_wait socket之后就回返回。这个slot余下的time_wait会交给Kernel的work_queue机制去处理。

值得注意的是。由于在这个slow_timer时间轮判断里面,根本不判断精确时间,直接全部删除。所以轮到某个slot,例如到了52.5-60s这个slot,直接清理52.5-60s的所有time_wait。即使time_wait还没有到60s也是如此。而小时间轮(tw_cal)会精确的判定时间,由于篇幅原因,就不在这里细讲了。
注: 小时间轮(tw\_cal)在tcp\_tw\_recycle开启的情况下会使用
5.3、先作出一个假设
我们假设,一个时间轮的数据最多能在一个slot间隔时间,也就是(60/8=7.5)内肯定能处理完毕。由于系统有tcp_tw_max_buckets设置,如果设置的比较合理,这个假设还是比较靠谱的。
注: 这里的60/8为什么需要精确到小数,而不是7。
因为实际计算的时候是拿60*HZ进行计算,
如果HZ是1024的话,那么period应该是7680,即精度精确到ms级。
所以在本文中计算的时候需要精确到小数。
5.4、如果一个slot中的TIME_WAIT<=100
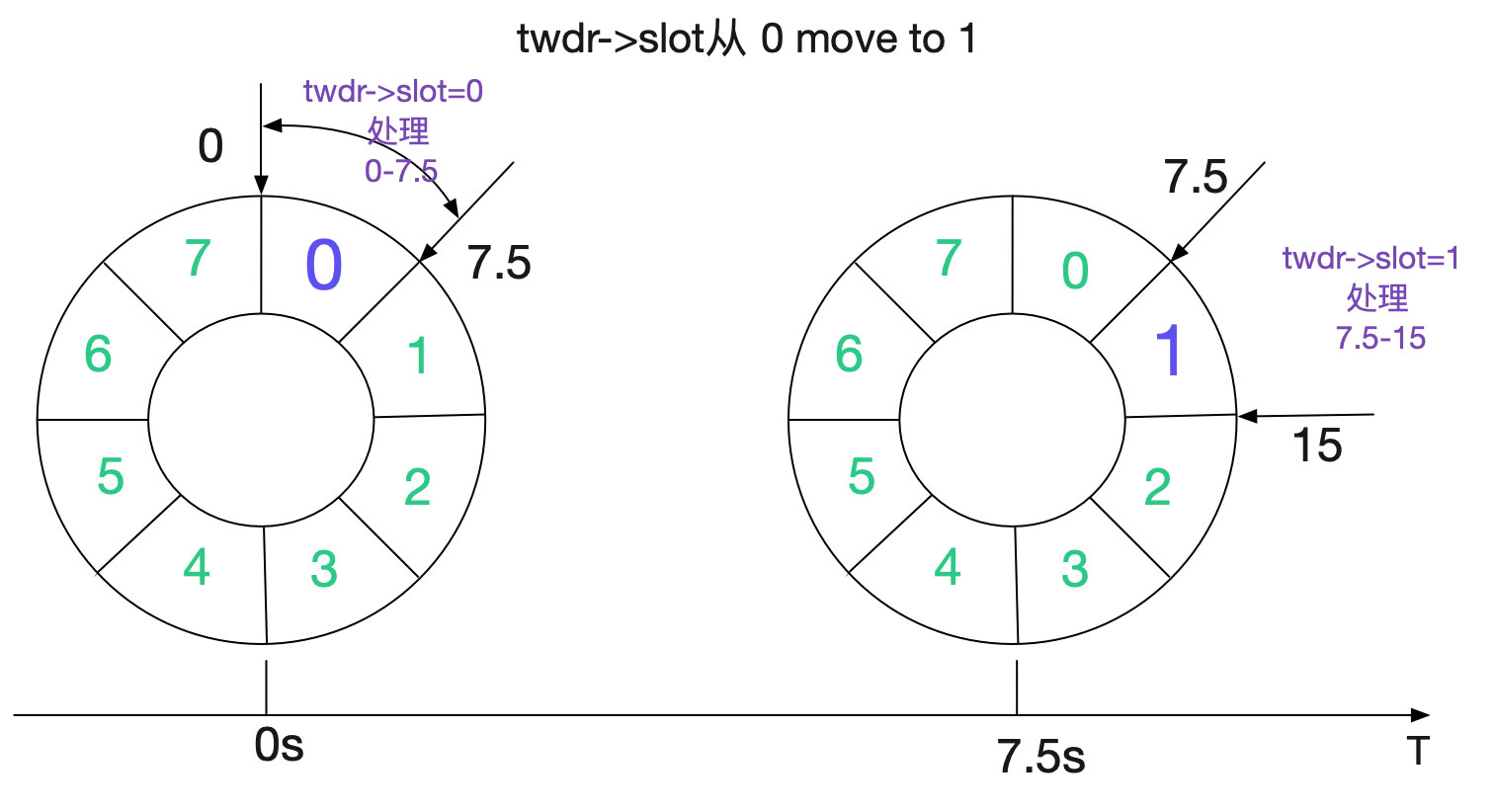
如果一个slot的TIME_WAIT<=100,很自然的,我们的处理函数并不会启用work_queue。同时,还将slot+1,使得在下一个period的时候可以处理下一个slot。如下图所示:
5.5、如果一个slot中的TIME_WAIT>100
如果一个slot的TIME_WAIT>100,Kernel会将余下的任务交给work_queue处理。同时,slot不变!也即是说,下一个period(7.5s后)到达的时候,还会处理同样的slot。按照我们的假设,这时候slot已经处理完毕,那么在第7.5s的时候才将slot向前推进。也就是说,假设slot一开始为0,到真正处理slot 1需要15s!

假设每一个slot的TIME_WAIT都>100的话,那么每个slot的处理都需要15s。
对于这种情况,笔者写了个程序进行模拟。
public class TimeWaitSimulator {
public static void main(String[] args) {
double delta = (60) * 1.0 / 8;
// 0表示开始清理,1表示清理完毕
// 清理完毕之后slot向前推进
int startPurge = 0;
double sum = 0;
int slot = 0;
while (slot < 8) {
if (startPurge == 0) {
sum += delta;
startPurge = 1;
if (slot == 7) {
// 因为假设进入work_queue之后,很快就会清理完
// 所以在slot为7的时候并不需要等最后的那个purge过程7.5s
System.out.println("slot " + slot + " has reach the last " + sum);
break;
}
}
if (startPurge == 1) {
sum += delta;
startPurge = 0;
System.out.println("slot " + "move to next at time " + sum);
// 清理完之后,slot才应该向前推进
slot++;
}
}
}
}
得出结果如下面所示:
slot move to next at time 15.0
slot move to next at time 30.0
slot move to next at time 45.0
slot move to next at time 60.0
slot move to next at time 75.0
slot move to next at time 90.0
slot move to next at time 105.0
slot 7 has reach the last 112.5
也即处理到52.5-60s这个时间轮的时候,其实外面时间已经过去了112.5s,处理已经完全滞后了。不过由于TIME_WAIT状态下的Socket(inet_timewait_sock)所占用内存很少,所以不会对系统可用资源造成太大的影响。但是,这会在NAT环境下造成一个坑,这也是笔者文章前面提到过的Bug。
上面的计算如果按照图和时间线画出来,应该是这么个情况:

也即TIME_WAIT状态的Socket在一个period(7.5s)内能处理完当前slot的情况下,最多能够存在112.5s!
如果7.5s内还处理不完,那么响应时间轮的轮转还得继续加上一个或多个perod。但在tcp_tw_max_buckets的限制,应该无法达到这么严苛的条件。
5.6、PAWS(Protection Against Wrapped Sequences)使得TIME_WAIT延长
事实上,以上结论还是不够严谨。TIME_WAIT时间还可以继续延长!看下这段源码:
enum tcp_tw_status
tcp_timewait_state_process(struct inet_timewait_sock *tw, struct sk_buff *skb,
const struct tcphdr *th)
{
......
if (paws_reject)
NET_INC_STATS_BH(twsk_net(tw), LINUX_MIB_PAWSESTABREJECTED);
if (!th->rst) {
/* In this case we must reset the TIMEWAIT timer.
*
* If it is ACKless SYN it may be both old duplicate
* and new good SYN with random sequence number <rcv_nxt.
* Do not reschedule in the last case.
*/
/* 如果有回绕校验失败的包到达的情况下,或者其实ack包
* 重置定时器到新的60s之后
* /
if (paws_reject || th->ack)
inet_twsk_schedule(tw, &tcp_death_row, TCP_TIMEWAIT_LEN,
TCP_TIMEWAIT_LEN);
/* Send ACK. Note, we do not put the bucket,
* it will be released by caller.
*/
/* 向对端发送当前time wait状态应该返回的ACK */
return TCP_TW_ACK;
}
inet_twsk_put(tw);
/* 注意,这边通过paws校验的包,会返回tcp_tw_success,使得time_wait状态的
* socket五元组也可以三次握手成功重新复用
* /
return TCP_TW_SUCCESS;
}
上面的逻辑如下图所示:

注意代码最后的return TCP_TW_SUCCESS,通过PAWS校验的包,会返回TCP_TW_SUCCESS,使得TIME_WAIT状态的Socket(五元组)也可以三次握手成功重新复用!
以上就是分析从Linux源码看TIME_WAIT的持续时间的详细内容,更多关于Linux源码 TIME_WAIT持续时间的资料请关注我们其它相关文章!
相关推荐
-
apache time_wait连接数太多问题解决方法
最近发现apache与负载均衡器的的连接数过多,而且大部分都是time_wait,调整apache2.conf后也没效果. 通过调整内核参数解决: 复制代码 代码如下: vi /etc/sysctl.conf 编辑文件,加入以下内容: 复制代码 代码如下: net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 然后,执行 /sb
-
解决time_wait强制关闭socket
解决time_wait 今天我在测试代码的时候,边开边看电影,服务端的CPU消耗和内存使用让我挺满意的 可是过了一会,在统计达到了一定连接后,后来连接很多无法登陆.象上公交车,拥 挤不堪无法上车,用netstat -an查看了下连接状态,time_wait状态的端口非常多 原因就在此了,消耗完系统的端口数,服务端将就无法接收新连接,找到问题就来说明 time_wait,这个东西默认存活时间为2分钟,够长的,这点很要命,更多的大家百度下 对付这个问题,我写了一个函数,强制关闭socket,代码环境
-
探讨如何减少Linux服务器TIME_WAIT过多的问题
TIME_WAIT状态的意义: 客户端与服务器端建立TCP/IP连接后关闭SOCKET后,服务器端连接的端口状态为TIME_WAIT是不是所有执行主动关闭的socket都会进入TIME_WAIT状态呢?有没有什么情况使主动关闭的socket直接进入CLOSED状态呢?主动关闭的一方在发送最后一个 ack 后就会进入 TIME_WAIT 状态 停留2MSL(max segment lifetime)时间,这个是TCP/IP必不可少的,也就是"解决"不了的.也就是TCP/IP设计者本来是这
-
解决linux下大量TIME WAIT的方法详解
问题描述:在Linux系统中高并发的Squid服务器,TCP TIME_WAIT套接字数量经常达到两.三万,服务器很容易被拖死.解决方法:通过修改Linux内核参数,可以减少linux服务器的IME_WAIT套接字数量.vi /etc/sysctl.conf增加以下几行: 复制代码 代码如下: net.ipv4.tcp_fin_timeout = 30net.ipv4.tcp_keepalive_time = 1200net.ipv4.tcp_syncookies = 1net.ipv4.tcp
-

分析从Linux源码看TIME_WAIT的持续时间
目录 一.前言 二.首先介绍下Linux环境 三.TIME_WAIT状态转移图 四.持续时间真如TCP_TIMEWAIT_LEN所定义么? 五.TIME_WAIT定时器源码 5.1.inet_twsk_schedule 5.2.具体的清理函数 5.3.先作出一个假设 5.4.如果一个slot中的TIME_WAIT<=100 5.5.如果一个slot中的TIME_WAIT>100 5.6.PAWS(Protection Against Wrapped Sequences)使得TIME_WAIT延
-
从Linux源码看Socket(TCP)Client端的Connect的示例详解
前言 笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情. 今天笔者就来从Linux源码的角度看下Client端的Socket在进行Connect的时候到底做了哪些事情.由于篇幅原因,关于Server端的Accept源码讲解留给下一篇博客. (基于Linux 3.10内核) 一个最简单的Connect例子 int clientSocket; if((clientSocket = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
-
详解从Linux源码看Socket(TCP)的bind
目录 一.一个最简单的Server端例子 二.bind系统调用 2.1.inet_bind 2.2.inet_csk_get_port 三.判断端口号是否冲突 四.SO_REUSEADDR和SO_REUSEPORT 五.SO_REUSEADDR 六.SO_REUSEPORT 七.总结 一.一个最简单的Server端例子 众所周知,一个Server端Socket的建立,需要socket.bind.listen.accept四个步骤. 代码如下: void start_server(){ // se
-
Android10 App 启动分析进程创建源码解析
目录 正文 RootActivityContainer ActivityStartController 调用startActivityUnchecked方法 ActivityStackSupervisor 启动进程 RuntimeInit.applicationInit这个方法 正文 从前文# Android 10 启动分析之SystemServer篇 (四)中可以得知,系统在完成所有的初始化工作后,会通过 mAtmInternal.startHomeOnAllDisplays(currentU
-
解析Linux源码之epoll
目录 一.前言 二.简单的epoll例子 2.1.epoll_create 2.2.struct eventpoll 2.3.epoll_ctl(add) 2.4.ep_insert 2.5.tfile->f_op->poll的实现 2.6.回调函数的安装 2.7.epoll_wait 2.8.ep_send_events 三.事件到来添加到epoll就绪队列(rdllist)的过程 3.1.可读事件到来 3.2.可写事件到来 四.关闭描述符(close fd) 五.总结 一.前言 在linu
-
分析Android Choreographer源码
一.前言 目前大部分手机都是 60Hz 的刷新率,也就是 16.6ms 刷新一次,系统为了配合屏幕的刷新频率,将 Vsync 的周期也设置为 16.6 ms,每个 16.6 ms , Vsync 信号唤醒 Choreographer 来做 App 的绘制操作,这就是引入 Choreographer 的主要作用.了解 Choreographer 还可以帮助 App 开发者知道程序每一帧运行的基本原理,也可以加深对 Message.Handler.Looper.MessageQueue.Measur
-
Java从源码看异步任务计算FutureTask
目录 了解一下什么是FutureTask? FutureTask 是如何实现的呢? FutureTask 运行流程 FutureTask 的使用 前言: 大家是否熟悉FutureTask呢?或者说你有没有异步计算的需求呢?FutureTask就能够很好的帮助你实现异步计算,并且可以实现同步获取异步任务的计算结果.下面我们就一起从源码分析一下FutureTask. 了解一下什么是FutureTask? FutureTask 是一个可取消的异步计算. FutureTask提供了对Future的基本实
-
解析从小程序开发者工具源码看原理实现
如何查看小程序开发者工具源码 下面我们通过微信小程序开发者工具的源码来说说小程序的底层实现原理.以开发者工具版本号State v1.02.1904090的源码来窥探小程序的实现思路.如何查看微信源码,对于mac用户而言,查看微信小程序开发者工具的包内容,然后进入Contents/Resources/app.nw/js/core/index.js,注释掉如下代码就可以查看开发者工具渲染后的代码. // 打开 inspect 窗口 if (nw.App.argv.indexOf('inspect')
-
浅析从vue源码看观察者模式
观察者模式 首先话题下来,我们得反问一下自己,什么是观察者模式? 概念 观察者模式(Observer):通常又被称作为发布-订阅者模式.它定义了一种一对多的依赖关系,即当一个对象的状态发生改变的时候,所有依赖于它的对象都会得到通知并自动更新,解决了主体对象与观察者之间功能的耦合. 讲个故事 上面对于观察者模式的概念可能会比较官方化,所以我们讲个故事来理解它. A:是共产党派往国民党密探,代号 001(发布者) B:是共产党的通信人员,负责与 A 进行秘密交接(订阅者) A 日常工作就是在明面采集
-
从源码看angular/material2 中 dialog模块的实现方法
本文将探讨material2中popup弹窗即其Dialog模块的实现. 使用方法 引入弹窗模块 自己准备作为模板的弹窗内容组件 在需要使用的组件内注入 MatDialog 服务 调用 open 方法创建弹窗,并支持传入配置.数据,以及对关闭事件的订阅 深入源码 进入material2的源码,先从 MatDialog 的代码入手,找到这个 open 方法: open<T>( componentOrTemplateRef: ComponentType<T> | TemplateRef