教你如何使用Python快速爬取需要的数据
一、基础第三方库使用
1.基本使用方法
"""例"""
from urllib import request
response = request.urlopen(r'http://bbs.pinggu.org/')
#返回状态 200证明访问成功
print("返回状态码: "+str(response.status))
#读取页面信息转换文本并进行解码,如果本身是UTF-8就不要,具体看页面格式
#搜索“charset”查看编码格式
response.read().decode('gbk')[:100]

2.Request
使用request()来包装请求,再通过urlopen()获取页面。俗称伪装。让服务器知道我们是通过浏览器来访问的页面,有些情况可能会被直接毙掉。
url = r'http://bbs.pinggu.org/'
headers = {'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': r'http://www.lagou.com/zhaopin/Python/?labelWords=label',
'Connection': 'keep-alive'}
req = request.Request(url, headers=headers)
page = request.urlopen(req).read()
page = page.decode('gbk')
page[:100]

包含data的方法。
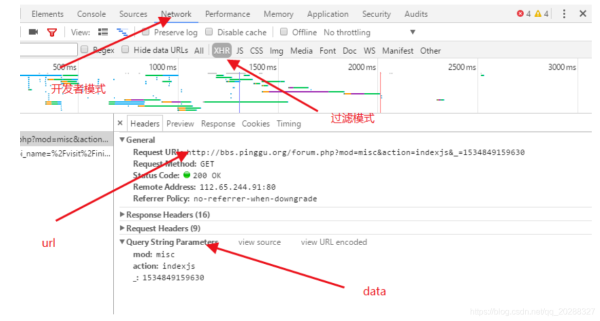
import urllib.parse
url = r'https://new-api.meiqia.com/v1/throttle/web?api_name=%2Fvisit%2Finit&ent_id=7276&v=1534848690048'
headers = {'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Referer': r'http://www.lagou.com/zhaopin/Python/?labelWords=label',
'Connection': 'keep-alive'}
values={'api_name':'/visit/init','ent_id':'7276','v':'1534848690048'}
data = urllib.parse.urlencode(values).encode(encoding='UTF8')
req = request.Request(url, data,headers=headers)
page = request.urlopen(req).read()
page = page.decode('gbk')
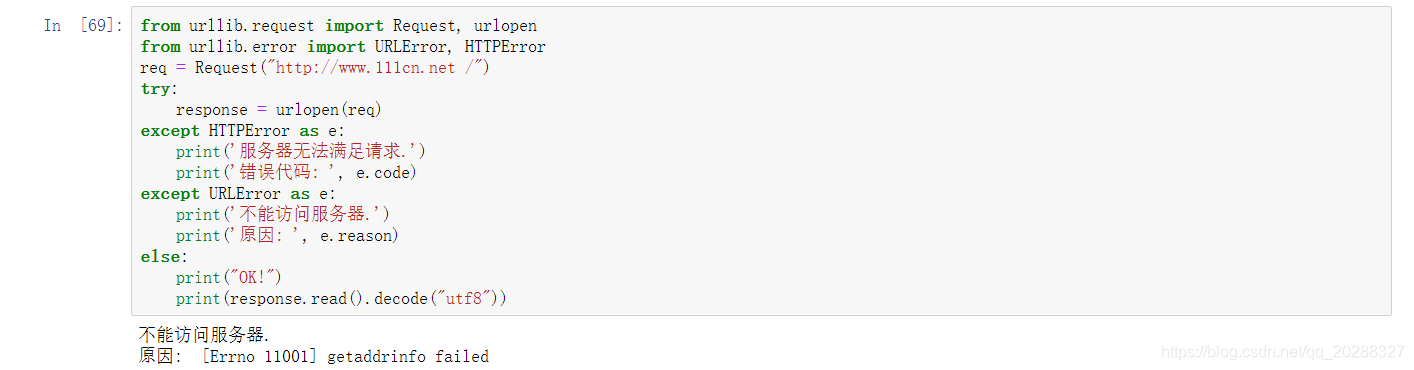
3.异常处理
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
req = Request("//www.jb51.net /")
try:
response = urlopen(req)
except HTTPError as e:
print('服务器无法满足请求.')
print('错误代码: ', e.code)
except URLError as e:
print('不能访问服务器.')
print('原因: ', e.reason)
else:
print("OK!")
print(response.read().decode("utf8"))
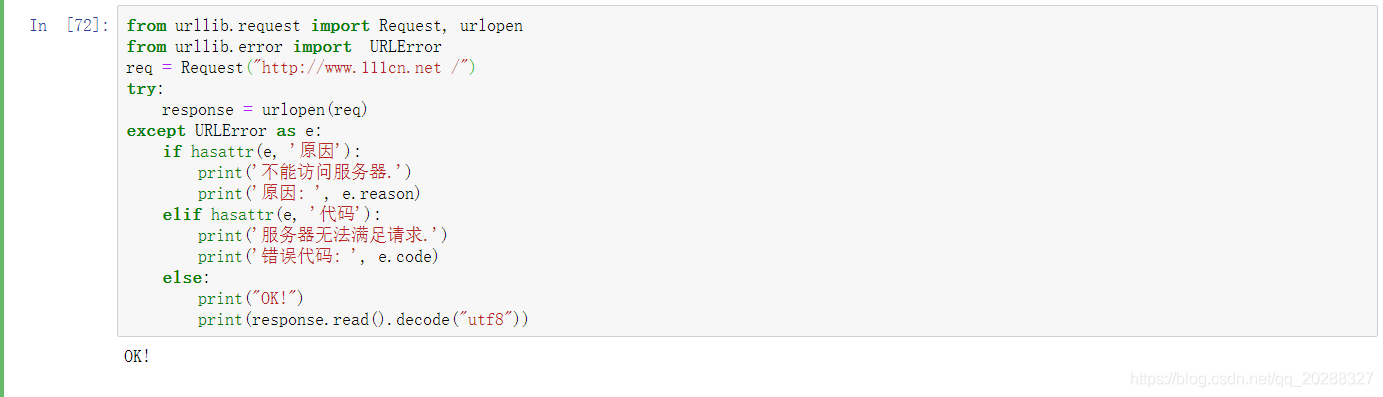
from urllib.request import Request, urlopen
from urllib.error import URLError
req = Request("//www.jb51.net /")
try:
response = urlopen(req)
except URLError as e:
if hasattr(e, '原因'):
print('不能访问服务器.')
print('原因: ', e.reason)
elif hasattr(e, '代码'):
print('服务器无法满足请求.')
print('错误代码: ', e.code)
else:
print("OK!")
print(response.read().decode("utf8"))
4.HTTP认证
import urllib.request
# 私密代理授权的账户
user = "user_name"
# 私密代理授权的密码
passwd = "uesr_password"
# 代理IP地址 比如可以使用百度西刺代理随便选择即可
proxyserver = "177.87.168.97:53281"
# 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码
passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码
passwdmgr.add_password(None, proxyserver, user, passwd)
# 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象
# 注意,这里不再使用普通ProxyHandler类了
proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr)
# 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler
opener = urllib.request.build_opener(proxyauth_handler)
# 5. 构造Request 请求
request = urllib.request.Request("http://bbs.pinggu.org/")
# 6. 使用自定义opener发送请求
response = opener.open(request)
# 7. 打印响应内容
print (response.read())
5.ROBOT协议
目标网址后加/robots.txt,例如:https://www.jd.com/robots.txt
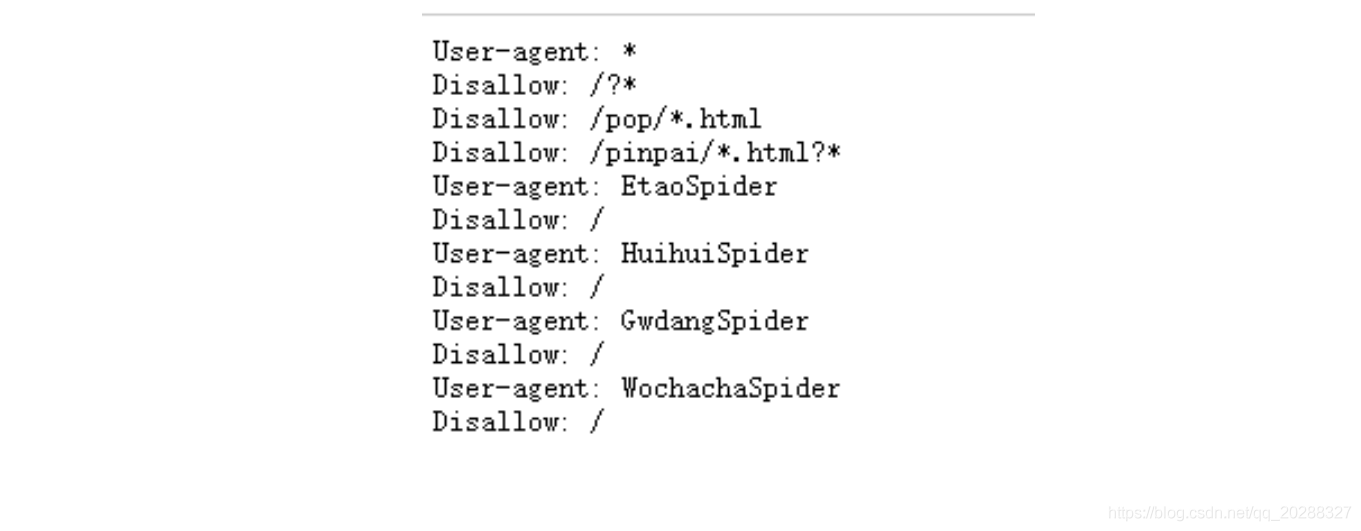
第一个的意思就是说对于所有的爬虫,不能爬取在/?开头的路径,也不能访问和/pop/*.html 匹配的路径。
后面四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
- User-agent: 这里是爬虫的名字
- Disallow: /该爬虫不允许访问的内容。
二、爬虫的网页抓取
1.爬虫的用途
实现浏览器的功能,通过制定的URL,直接返回用户所需要的数据。
一般步骤:
- 查找域名对应的IP地址 (比如:119.75.217.109是哪个网站?)。
- 向对应的IP地址发送get或者post请求。
- 服务器相应结果200,返回网页内容。
- 开始抓你想要的东西吧。
2.网页分析
获取对应内容之后进行分析,其实就需要对一个文本进行处理,把你需要的内容从网页中的代码中提取出来的过程。BeautifulSoup可实现惯用的文档导航、查找、修改文档功能。如果lib文件夹下没有BeautifulSoup的使用命令行安装即可。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志
from bs4 import BeautifulSoup
soup = BeautifulSoup('<meta content="all" name="robots" />',"html.parser")
tag=soup.meta
# tag的类别
type(tag)
>>> bs4.element.Tag
# tag的name属性
tag.name
>>> 'meta'
# attributes属性
tag.attrs
>>> {'content': 'all', 'name': 'robots'}
# BeautifulSoup属性
type(soup)
>>> bs4.BeautifulSoup
soup.name
>>> '[document]'
# 字符串的提取
markup='<b><a href="http://house.people.com.cn/" rel="external nofollow" target="_blank">房产</a></b>'
soup=BeautifulSoup(markup,"lxml")
text=soup.b.string
text
>>> '房产'
type(text)
>>> bs4.element.NavigableString
4.BeautifulSoup 应用举例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
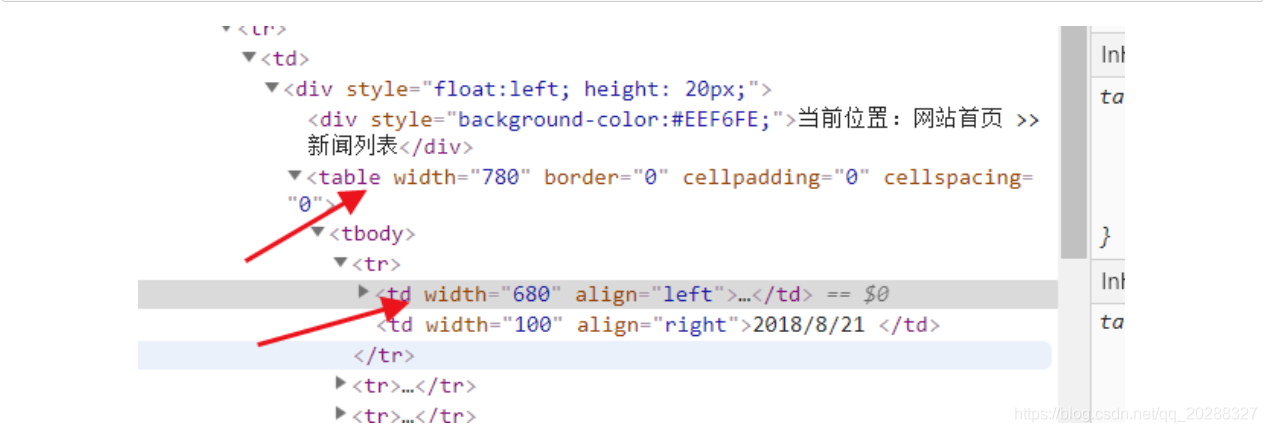
#通过页面解析得到结构数据进行处理
from bs4 import BeautifulSoup
soup=BeautifulSoup(html.text,"lxml")
#定位
lptable = soup.find('table',width='780')
# 解析
for i in lptable.find_all("td",width="680"):
title = i.b.strong.a.text
href = "http://www.cwestc.com"+i.find('a')['href']
# href = i.find('a')['href']
date = href.split("/")[4]
print (title,href,date)

4.Xpath 应用举例
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
四种标签的使用方法
- // 双斜杠 定位根节点,会对全文进行扫描,在文档中选取所有符合条件的内容,以列表的形式返回。
- / 单斜杠 寻找当前标签路径的下一层路径标签或者对当前路标签内容进行操作
- /text() 获取当前路径下的文本内容
- /@xxxx 提取当前路径下标签的属性值
- | 可选符 使用|可选取若干个路径 如//p | //div 即在当前路径下选取所有符合条件的p标签和div标签。
- . 点 用来选取当前节点
- … 双点 选取当前节点的父节点
from lxml import etree
html="""
<!DOCTYPE html>
<html>
<head lang="en">
<title>test</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
</head>
<body>
<div id="content">
<ul id="ul">
<li>NO.1</li>
<li>NO.2</li>
<li>NO.3</li>
</ul>
<ul id="ul2">
<li>one</li>
<li>two</li>
</ul>
</div>
<div id="url">
<a href="http://www.crossgate.com" rel="external nofollow" title="crossgate">crossgate</a>
<a href="http://www.pinggu.org" rel="external nofollow" title="pinggu">pinggu</a>
</div>
</body>
</html>
"""
#这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容
selector=etree.HTML(html)
content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
for i in content:
print (i)

#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值
con=selector.xpath('//a/@href')
for i in con:
print (i)

#使用绝对路径 #使用相对路径定位 两者效果是一样的
con=selector.xpath('/html/body/div/a/@title')
print (len(con))
print (con[0],con[1])

三、动态网页和静态网页的区分
来源百度:
静态网页的基本概述
静态网页的网址形式通常是以.htm、.html、.shtml、.xml等为后后缀的。静态网页,一般来说是最简单的HTML网页,服务器端和客户端是一样的,而且没有脚本和小程序,所以它不能动。在HTML格式的网页上,也可以出现各种动态的效果,如.GIF格式的动画、FLASH、滚动字母等,这些“动态效果”只是视觉上的,与下面将要介绍的动态网页是不同的概念。
静态网页的特点
- 静态网页每个网页都有一个固定的URL,且网页URL以.htm、.html、.shtml等常见形式为后缀,而不含有“?”。
- 网页内容一经发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都是保存在网站服务器上的,也就是说,静态网页是实实在在保存在服务器上的文件,每个网页都是一个独立的文件。
- 静态网页的内容相对稳定,因此容易被搜索引擎检索。
- 静态网页没有数据库的支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作方式比较困难。
- 静态网页的交互性交叉,在功能方面有较大的限制。
动态网页的基本概述
动态网页是以.asp、.jsp、.php、.perl、.cgi等形式为后缀,并且在动态网页网址中有一个标志性的符号——“?”。动态网页与网页上的各种动画、滚动字幕等视觉上的“动态效果”没有直接关系,动态网页也可以是纯文字内容的,也可以是包含各种动画的内容,这些只是网页具体内容的表现形式,无论网页是否具有动态效果,采用动态网站技术生成的网页都称为动态网页.动态网站也可以采用静动结合的原则,适合采用动态网页的地方用动态网页,如果必要使用静态网页,则可以考虑用静态网页的方法来实现,在同一个网站上,动态网页内容和静态网页内容同时存在也是很常见的事情。
动态网页应该具有以下几点特色:
- 交互性:即网页会根据用户的要求和选择而动态改变和响应。例如访问者在网页填写表单信息并提交,服务器经过处理将信息自动存储到后台数据库中,并打开相应提示页面。
- 自动更新:即无需手动操作,便会自动生成新的页面,可以大大节省工作量。例如,在论坛中发布信息,后台服务器将自动生成新的网页。
- 随机性:即当不问的时间、不问的人访问同一网址时会产生不同的页面效果。例如,登录界面自动循环功能。
- 动态网页中的“?”对搜索引擎检索存在一定的问题,搜索引擎一般不可能从一个网站的数据库中访问全部网页,或者出于技术方面的考虑,搜索蜘蛛不去抓取网址中“?”后面的内容,因此采用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理才能适应搜索引擎的要求。
总结来说:页面内容变了网址也会跟着变基本都是静态网页,反之是动态网页。
四、动态网页和静态网页的抓取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]

import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]

总结:上面2个url差别在最后一个数字,在原网页上每点下一页网址和内容同时变化,我们判断:该网页为静态网页。
2.动态网页
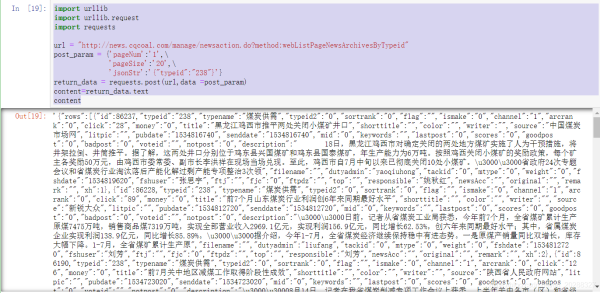
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
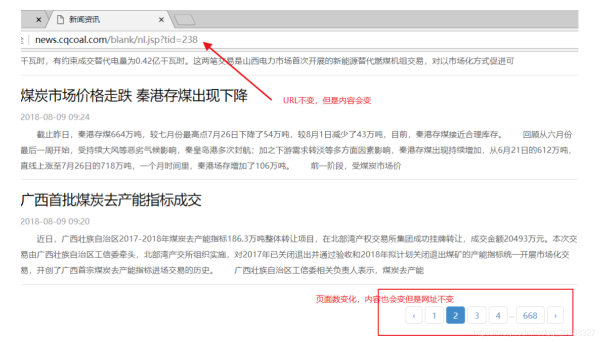
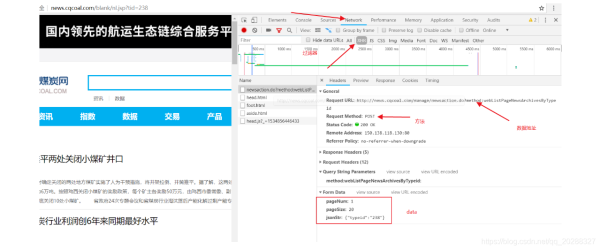
抓取该网页看不到任何的信息证明是动态网页,正确抓取方法如下。
import urllib
import urllib.request
import requests
url = "http://news.cqcoal.com/manage/newsaction.do?method:webListPageNewsArchivesByTypeid"
post_param = {'pageNum':'1',\
'pageSize':'20',\
'jsonStr':'{"typeid":"238"}'}
return_data = requests.post(url,data =post_param)
content=return_data.text
content
到此这篇关于教你如何使用Python快速爬取需要的数据的文章就介绍到这了,更多相关Python爬取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python手拉手教你爬取贝壳房源数据的实战教程
一.爬虫是什么? 在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大.此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而进行更深层次的数据分析,并获得更多有价值的信息. 在使用爬虫前首先要了解爬虫所需的库(requests)或者( urllib.request ),该库
-
Python数据分析之Python和Selenium爬取BOSS直聘岗位
一.数据爬取的代码 #encoding='utf-8' from selenium import webdriver import time import re import pandas as pd import os def close_windows(): #如果有登录弹窗,就关闭 try: time.sleep(0.5) if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("c
-
python爬取分析超级大乐透历史开奖数据第1/2页
博主作为爬虫初学者,本次使用了requests和beautifulsoup库进行数据的爬取 爬取网站:http://datachart.500.com/dlt/history/history.shtml -500彩票网 (分析后发现网站源代码并非是通过页面跳转来查找不同的数据,故可通过F12查找network栏找到真正储存所有历史开奖结果的网页) 如图: 爬虫部分: from bs4 import BeautifulSoup #引用BeautifulSoup库 import requests #
-
python爬取豆瓣电影TOP250数据
在执行程序前,先在MySQL中创建一个数据库"pachong". import pymysql import requests import re #获取资源并下载 def resp(listURL): #连接数据库 conn = pymysql.connect( host = '127.0.0.1', port = 3306, user = 'root', password = '******', #数据库密码请根据自身实际密码输入 database = 'pachong', cha
-
python爬虫之爬取谷歌趋势数据
一.前言 爬取谷歌趋势数据需要科学上网~ 二.思路 谷歌数据的爬取很简单,就是代码有点长.主要分下面几个就行了 爬取的三个界面返回的都是json数据.主要获取对应的token值和req,然后构造url请求数据就行 token值和req值都在这个链接的返回数据里.解析后得到token和req就行 socks5代理不太懂,抄网上的作业,假如了当前程序的全局代理后就可以跑了.全部代码如下 import socket import socks import requests import json im
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
教你如何使用Python快速爬取需要的数据
一.基础第三方库使用 1.基本使用方法 """例""" from urllib import request response = request.urlopen(r'http://bbs.pinggu.org/') #返回状态 200证明访问成功 print("返回状态码: "+str(response.status)) #读取页面信息转换文本并进行解码,如果本身是UTF-8就不要,具体看页面格式 #搜索"char
-
python requests爬取高德地图数据的实例
如下所示: 1.pip install requests 2.pip install lxml 3.pip install xlsxwriter import requests #想要爬必须引 from lxml import html #这个是用于页面爬取 import xlsxwriter#操作Excel表格库 workbook = xlsxwriter.Workbook('E:/test/test.xlsx')# 新建的Excel表格文档路径 worksheet = workbook.ad
-
Python爬虫爬取、解析数据操作示例
本文实例讲述了Python爬虫爬取.解析数据操作.分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不同解析方式和存储方式 引用相关库 import requests import re import csv import pymysql from bs4 import BeautifulSoup from lxml import e
-
Python爬虫爬取电影票房数据及图表展示操作示例
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作.分享给大家供大家参考,具体如下: 爬虫电影历史票房排行榜 http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0 Python爬取历史电影票房纪录 解析Json数据 横向条形图展示 面向对象思想 导入相关库 import requests import re from matplotlib import pyplot as plt from matplotlib import font
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
Python自动化爬取天眼查数据的实现
首先要注册一个账号密码,通过账号密码登录,并且滑块验证,自动输入搜索关键词,进行跳转翻页爬取数据,并保存到Excel文件中. 代码运行时,滑块验证经常不通过,被吃掉,但是发现打包成exe运行没有这个问题,100%成功登录.如果大家知道这个问题麻烦请与我分享,谢谢! 废话不多说直接上代码 # coding=utf-8 from selenium import webdriver import time from PIL import Image, ImageGrab from io import
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
用python爬虫爬取CSDN博主信息
一.项目介绍 爬取网址:CSDN首页的Python.Java.前端.架构以及数据库栏目.简单分析其各自的URL不难发现,都是https://www.csdn.net/nav/+栏目名样式,这样我们就可以爬取不同栏目了. 以Python目录页为例,如下图所示: 爬取内容:每篇文章的博主信息,如博主姓名.码龄.原创数.访问量.粉丝数.获赞数.评论数.收藏数 (考虑到周排名.总排名.积分都是根据上述信息综合得到的,对后续分析没实质性的作用,这里暂不爬取.) 不想看代码的朋友可直接跳到第三部分~ 二.S
-
python正则表达式爬取猫眼电影top100
用正则表达式爬取猫眼电影top100,具体内容如下 #!/usr/bin/python # -*- coding: utf-8 -*- import json # 快速导入此模块:鼠标先点到要导入的函数处,再Alt + Enter进行选择 from multiprocessing.pool import Pool #引入进程池 import requests import re import csv from requests.exceptions import RequestException
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的