python DataFrame数据分组统计groupby()函数的使用
目录
- groupby()函数
- 1. groupby基本用法
- 1.1 一级分类_分组求和
- 1.2 二级分类_分组求和
- 1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算)
- 2. 对分组数据进行迭代
- 2.1 对一级分类的DataFrameGroupBy对象进行遍历
- 2.2 对二级分类的DataFrameGroupBy对象进行遍历
- 3. agg()函数
- 3.1一般写法_对目标数据使用同一聚合函数
- 3.2 对不同列使用不同聚合函数
- 3.3 自定义函数写法
- 4. 通过 字典 和 Series 对象进行分组统计
- 4.1通过一个字典
- 4.2通过一个Series
groupby()函数
在python的DataFrame中对数据进行分组统计主要使用groupby()函数。
1. groupby基本用法
1.1 一级分类_分组求和
import pandas as pd
data = [['a', 'A', 109], ['b', 'B', 112], ['c', 'A', 125], ['d', 'C', 120],
['e', 'C', 126], ['f', 'B', 133], ['g', 'A', 124], ['h', 'B', 134],
['i', 'C', 117], ['j', 'C', 128]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
columns = ['name', 'class', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby('class').sum() # 分组统计求和
print(df1)

1.2 二级分类_分组求和
给groupby()传入一个列表,列表中的元素为分类字段,从左到右分类级别增大。(一级分类、二级分类…)
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'B', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'A', '2等', 124], ['h', 'B', '1等', 134],
['i', 'A', '2等', 117], ['j', 'A', '2等', 128], ['h', 'A', '1等', 130], ['i', 'B', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby(['class_1', 'class_2']).sum() # 分组统计求和
print(df1)

1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算)
其中,df.groupby(‘class_1’)得到一个DataFrameGroupBy对象,对该对象可以使用列名进行索引,以对指定的列进行统计。
如:df.groupby(‘class_1’)[‘num’].sum()
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'B', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'A', '2等', 124], ['h', 'B', '1等', 134],
['i', 'A', '2等', 117], ['j', 'A', '2等', 128], ['h', 'A', '1等', 130], ['i', 'B', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("=================================================")
df1 = df.groupby('class_1')['num'].sum()
print(df1)
代码运行结果同上。
2. 对分组数据进行迭代
2.1 对一级分类的DataFrameGroupBy对象进行遍历
for name, group in DataFrameGroupBy_object
其中,name指分类的类名,group指该类的所有数据。
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'C', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'C', '2等', 124], ['h', 'A', '1等', 134],
['i', 'C', '2等', 117], ['j', 'A', '2等', 128], ['h', 'B', '1等', 130], ['i', 'C', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
# 获取目标数据。
df1 = df[['name', 'class_1', 'num']]
for name, group in df1.groupby('class_1'):
print(name)
print("=============================")
print(group)
print("==================================================")


2.2 对二级分类的DataFrameGroupBy对象进行遍历
对二级分类的DataFrameGroupBy对象进行遍历,
以for (key1, key2), group in df.groupby([‘class_1’, ‘class_2’]) 为例
不同于一级分类的是, (key1, key2)是一个由多级类别组成的元组,而group表示该多级分类类别下的数据。
import pandas as pd
data = [['a', 'A', '1等', 109], ['b', 'C', '1等', 112], ['c', 'A', '1等', 125], ['d', 'B', '2等', 120],
['e', 'B', '1等', 126], ['f', 'B', '2等', 133], ['g', 'C', '2等', 124], ['h', 'A', '1等', 134],
['i', 'C', '2等', 117], ['j', 'A', '2等', 128], ['h', 'B', '1等', 130], ['i', 'C', '2等', 122]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
for (key1, key2), group in df.groupby(['class_1', 'class_2']):
print(key1, key2)
print("=============================")
print(group)
print("==================================================")
程序运行结果如下:

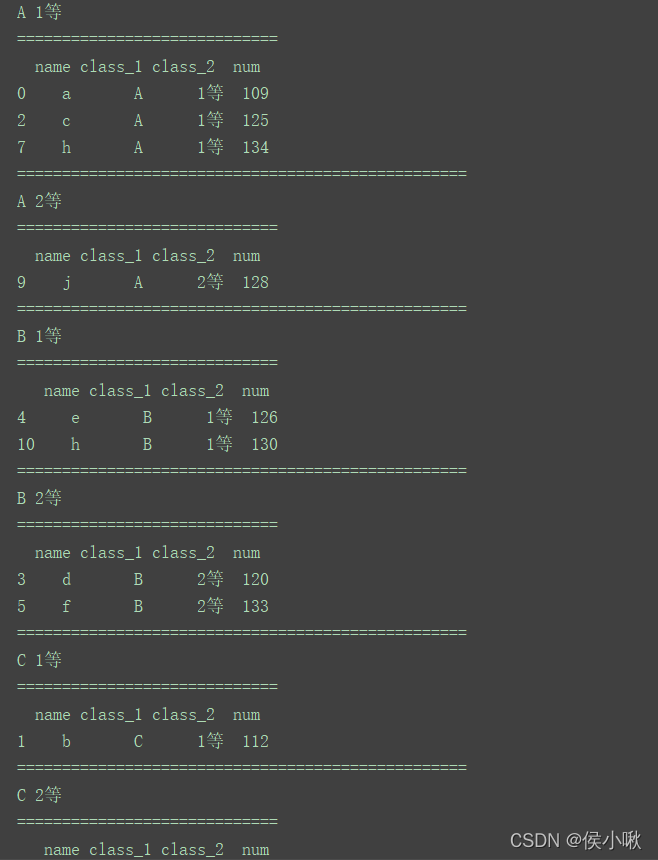
(部分)
3. agg()函数
使用groupby()函数和agg()函数 实现 分组聚合操作运算。
3.1一般写法_对目标数据使用同一聚合函数
以 分组求均值、求和 为例
给agg()传入一个列表
df1.groupby([‘class_1’, ‘class_2’]).agg([‘mean’, ‘sum’])
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
df1 = df[['class_1', 'class_2', 'num1', 'num2']]
print(df1.groupby(['class_1', 'class_2']).agg(['mean', 'sum']))

3.2 对不同列使用不同聚合函数
给agg()方法传入一个字典
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
df1 = df[['class_1', 'num1', 'num2']]
print(df1.groupby('class_1').agg({'num1': ['mean', 'sum'], 'num2': ['sum']}))

3.3 自定义函数写法
也可以自定义一个函数(以名为max1为例)传入agg()中。
import pandas as pd
data = [['a', 'A', '1等', 109, 144], ['b', 'C', '1等', 112, 132], ['c', 'A', '1等', 125, 137], ['d', 'B', '2等', 120, 121],
['e', 'B', '1等', 126, 136], ['f', 'B', '2等', 133, 127], ['g', 'C', '2等', 124, 126], ['h', 'A', '1等', 134, 125],
['i', 'C', '2等', 117, 125], ['j', 'A', '2等', 128, 133], ['h', 'B', '1等', 130, 122], ['i', 'C', '2等', 122, 111]]
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
columns = ['name', 'class_1', 'class_2', 'num1', 'num2']
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================")
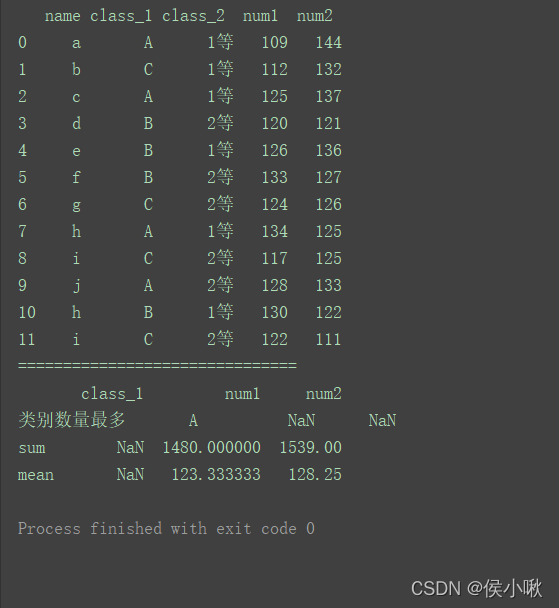
max1 = lambda x: x.value_counts(dropna=False).index[0]
max1.__name__ = "类别数量最多"
df1 = df.agg({'class_1': [max1],
'num1': ['sum', 'mean'],
'num2': ['sum', 'mean']})
print(df1)
4. 通过 字典 和 Series 对象进行分组统计
groupy()不仅仅可以传入单个列,或多个列组成的列表,
也可以传入一个字典或者一个Series来实现分组。
4.1通过一个字典
import pandas as pd
data = [['A', 10000, 20121, 14521, 20, 23, 4, 5000],
['B', 12000, 12541, 11220, 14, 25, 5, 6000],
['C', 21420, 26452, 34215, 25, 24, 4, 5266],
['D', 21025, 23155, 31251, 23, 26, 6, 6452],
['E', 30021, 23512, 21452, 30, 27, 5, 7525],
['F', 32152, 30214, 26321, 32, 30, 7, 6952]]
columns = ['公司', 'a产品产量', 'b产品产量', 'c产品产量', '搬运工数量', '推销员数量', '经理数量', '平均工资']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, columns=columns)
df = df.set_index(['公司'])
print(df)
print("===============================")
mapping = {
'a产品产量': '产品产量', 'b产品产量': '产品产量',
'c产品产量': '产品产量', '搬运工数量': '人员数量',
'推销员数量': '人员数量', '经理数量': '人员数量',
'平均工资': '平均工资'
}
df1 = df.groupby(mapping, axis=1).sum()
print(df1)
程序运行结果:

4.2通过一个Series
import pandas as pd
data = [['A', 10000, 20121, 14521, 20, 23, 4, 5000],
['B', 12000, 12541, 11220, 14, 25, 5, 6000],
['C', 21420, 26452, 34215, 25, 24, 4, 5266],
['D', 21025, 23155, 31251, 23, 26, 6, 6452],
['E', 30021, 23512, 21452, 30, 27, 5, 7525],
['F', 32152, 30214, 26321, 32, 30, 7, 6952]]
columns = ['公司', 'a产品产量', 'b产品产量', 'c产品产量', '搬运工数量', '推销员数量', '经理数量', '平均工资']
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame(data=data, columns=columns)
df = df.set_index(['公司'])
print(df)
print("===============================")
data = {
'a产品产量': '产品产量', 'b产品产量': '产品产量',
'c产品产量': '产品产量', '搬运工数量': '人员数量',
'推销员数量': '人员数量', '经理数量': '人员数量',
'平均工资': '平均工资'
}
s1 = pd.Series(data)
df1 = df.groupby(s1, axis=1).sum()
print(df1)
程序运行结果:

参考资源: python数据分析从入门到精通 明日科技编著 清华大学出版社
到此这篇关于python DataFrame数据分组统计groupby()函数的使用的文章就介绍到这了,更多相关python DataFrame groupby() 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python用dataframe将csv中的0值数据转化为nan缺失值字样
用到这个语句. c[c==0]=np.nan 我们具体来看一下c和np是什么 np就是我引入的pandas库, c呢是我读入csv文件的其中一列,列名为"上行业务量GB" df是整个csv文件的数据,他的类型是dataframe import numpy as np import pandas as pd # 打开文件 FileName= '长期编号.csv' df = pd.read_csv(FileName, encoding='utf-8') c = df[['上行业务量GB']
-

python DataFrame数据格式化(设置小数位数,百分比,千分位分隔符)
目录 1.设置小数位数 1.1数据框设置统一小数位数 1.2数据框分别设置不同小数位数 1.3通过Series设置DataFrame小数位数 1.4applymap(自定义函数) 2.设置百分比 3.设置千分位分隔符 1.设置小数位数 1.1 数据框设置统一小数位数 以保留小数点后两位小数为例: import pandas as pd import numpy as np df = pd.DataFrame(np.random.random([5, 5]), columns=['A1', 'A2
-
python pandas分割DataFrame中的字符串及元组的方法实现
目录 1.使用str.split()方法 2.使用join()与split()方法结合 3.使用apply方法分割元组 1.使用str.split()方法 可以使用pandas 内置的 str.split() 方法实现分割字符串类型的数据,并将分割结果写入DataFrame中,以表格形式呈现. 语法: Series.str.split(pat=None, n=-1, expand=False) 其中,pat是字符串或正则表达式,n是一个整数数字,默认为-1.为0或-1时即为最大次数的分割.其他数
-
python将Dataframe格式的数据写入opengauss数据库并查询
目录 一.将数据写入opengauss 二.python条件查询opengauss数据库中文列名的数据 一.将数据写入opengauss 前提准备: 成功opengauss数据库,并创建用户jack,创建数据库datasets. 数据准备: 所用数据以csv格式存在本地,编码格式为GB2312. 数据存入: 开始hello表未存在,那么执行程序后,系统会自动创建一个hello表(这里指定了名字为hello): 若hello表已经存在,那么会增加数据到hello表.列名需要与hello表一一对应.
-
python中Array和DataFrame相互转换的实例讲解
python中,对于array数组中的数据放在DataFrame数据框中可以更好的进行数据分析,但是二者并不是一个数据类型,因此需要将array转dataframe.既然可以array转dataframe,那么可同样dataframe也可以转回array结构.本文介绍python中Array和DataFrame相互转换的方法. 1.array转dataframe:直接用pd.dataframe()进行转化 使用格式 a = pd.DataFrame(a) 具体实例 import pandas a
-
python DataFrame中stack()方法、unstack()方法和pivot()方法浅析
目录 1.stack() 2. unstack() 3. pivot() 总结 1.stack() stack()用于将列索引转换为最内层的行索引,这样叙述比较抽象,看示例就容易理解啦: 准备一组数据,给其设置双索引. import pandas as pd data = [['A类', 'a1', 123, 224, 254], ['A类', 'a2', 234, 135, 444], ['A类', 'a3', 345, 241, 324], ['B类', 'b1', 112, 412, 46
-
python数据分析之DataFrame内存优化
目录 1. pandas查看数据占用大小 2. 对数据进行压缩 3. 参考资料
-
python DataFrame数据分组统计groupby()函数的使用
目录 groupby()函数 1. groupby基本用法 1.1 一级分类_分组求和 1.2 二级分类_分组求和 1.3 对DataFrameGroupBy对象列名索引(对指定列统计计算) 2. 对分组数据进行迭代 2.1 对一级分类的DataFrameGroupBy对象进行遍历 2.2 对二级分类的DataFrameGroupBy对象进行遍历 3. agg()函数 3.1一般写法_对目标数据使用同一聚合函数 3.2 对不同列使用不同聚合函数 3.3 自定义函数写法 4. 通过 字典 和 Se
-
pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
关于python DataFrame的合并方法总结
目录 python DataFrame的合并方法 #concat函数 #merge函数 #append函数 把两个dataframe合并成一个 python DataFrame的合并方法 Python的Pandas针对DataFrame,Series提供了多个合并函数,通过参数的调整可以轻松实现DatafFrame的合并. 首先,定义3个DataFrame df1,df2,df3,进行concat.merge.append函数的实验. df1=pd.DataFrame([[1,2,3],[2,3
-
Python DataFrame.groupby()聚合函数,分组级运算
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个键(可以是函数.数组或DataFrame列名)拆分pandas对象.计算分组摘要统计,如计数.平均值.标准差,或用户自定义函数.对DataFrame的列应用各种各样的函数.应用组内转换或其他运算,如规格化.线性回归.排名或选取子集等.计算透视表或交叉表.执行分位数分析以及其他分组分析. groupby分组函数: 返回值:返回重构格式的DataFrame,特别注意,grou
-
python groupby函数实现分组后选取最值
现在需要将course分组,然后选择出每一组里面的最大值和最小值,并保留下来 实现下面数据结果: 直接使用groupby函数,不能直接达到此效果,需要在groupby函数上添加apply和lambda函数 代码如下: import pandas as pd data = pd.read_excel('group_apply.xlsx') data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min())
-
python groupby函数实现分组选取最大值与最小值
现在需要将course分组,然后选择出每一组里面的最大值和最小值,并保留下来 实现下面数据结果: 直接使用groupby函数,不能直接达到此效果,需要在groupby函数上添加apply和lambda函数 代码如下: import pandas as pd data = pd.read_excel('group_apply.xlsx') data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min())
-
详解Python中的分组函数groupby和itertools)
具体代码如下所示: from operator import itemgetter #itemgetter用来去dict中的key,省去了使用lambda函数 from itertools import groupby #itertool还包含有其他很多函数,比如将多个list联合起来.. d1={'name':'zhangsan','age':20,'country':'China'} d2={'name':'wangwu','age':19,'country':'USA'} d3={'nam
-
详解python中groupby函数通俗易懂
一.groupby 能做什么? python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算! 对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下: df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式--函数名称) 举例如下: print(df["评分"].groupby([df["地区"],df["类
-
Python Pandas实现数据分组求平均值并填充nan的示例
Python实现按某一列关键字分组,并计算各列的平均值,并用该值填充该分类该列的nan值. DataFrame数据格式 fillna方式实现 groupby方式实现 DataFrame数据格式 以下是数据存储形式: fillna方式实现 1.按照industryName1列,筛选出业绩 2.筛选出相同行业的Series 3.计算平均值mean,采用fillna函数填充 4.append到新DataFrame中 5.循环遍历行业名称,完成2,3,4步骤 factordatafillna = pd.