elasticsearch分布式及数据的功能源码分析
从功能上说,可以分为两部分,分布式功能和数据功能。分布式功能主要是节点集群及集群附属功能如restful借口、集群性能检测功能等,数据功能主要是索引和搜索。代码上这些功能并不是完全独立,而是由相互交叉部分。当然分布式功能是为数据功能服务,数据功能肯定也难以完全独立于分布式功能。
它的源码有以下几个特点:
模块化:
每个功能都以模块化的方式实现,最后以一个借口向外暴露,最终通过guice(google轻量级DI框架)进行管理。整个系统有30多个模块(version1.5)。
接口解耦:
es代码中使用了大量的接口进行代码解耦,刚开始看的感觉是非常难以找到相关功能的实现,但是也正是这些接口使得代码实现的非常优雅。
异步通信:
作为一个高效的分布式系统,es中异步通信实现非常之多,从集群通信到搜索功能,使用了异步通信框架netty作为节点间的通信框架。
以上的这些特点在后面的代码分析中会一一体现。概述的结尾以es的启动过程来结束,es的启动类是Bootstrap,启动脚本调研这个类的main方法开始启动node。它的类图如下所示:
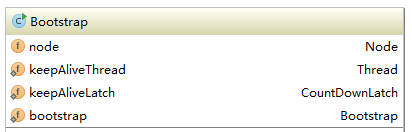
上图仅仅显示了它的field,其中node是要启动的节点。keepAliveThread线程保证节点运行期间Bootstrap会一直存在,可以接收关机命令进行从而优雅关闭。下面是启动前的属性设置,代码如下:
private void setup(boolean addShutdownHook, Tuple<Settings, Environment> tuple) throws Exception {
if (tuple.v1().getAsBoolean("bootstrap.mlockall", false)) {//尝试锁定内存
Natives.tryMlockall();
}
tuple = setupJmx(tuple);
NodeBuilder nodeBuilder = NodeBuilder.nodeBuilder().settings(tuple.v1()).loadConfigSettings(false);
node = nodeBuilder.build();//初始化node
if (addShutdownHook) {//添加关闭node的hook
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
node.close();
}
});
}
}
尝试锁定内存左右是保证节点运行期间的内存不变动,以防因为内存变得带来性能上的波动,这里调用的是c方法。最后来看一下main方法:
public static void main(String[] args) {
....
String stage = "Initialization";//标明启动阶段用于构造错误信息。
try {
if (!foreground) {
Loggers.disableConsoleLogging();
System.out.close();
}
bootstrap.setup(true, tuple);
stage = "Startup";
bootstrap.start();//bootstrap的启动过程也就是node的启动过程
if (!foreground) {
System.err.close();
}
//构造一个线程,保证bootstrap不退出,仍然可以接收命令。
keepAliveLatch = new CountDownLatch(1);
// keep this thread alive (non daemon thread) until we shutdown/
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
keepAliveLatch.countDown();
}
});
keepAliveThread = new Thread(new Runnable() {
@Override
public void run() {
try {
keepAliveLatch.await();
} catch (InterruptedException e) {
// bail out
}
}
}, "elasticsearch[keepAlive/" + Version.CURRENT + "]");
keepAliveThread.setDaemon(false);
keepAliveThread.start();
} catch (Throwable e) {
ESLogger logger = Loggers.getLogger(Bootstrap.class);
if (bootstrap.node != null) {
logger = Loggers.getLogger(Bootstrap.class, bootstrap.node.settings().get("name"));
}
String errorMessage = buildErrorMessage(stage, e);
if (foreground) {
System.err.println(errorMessage);
System.err.flush();
} else {
logger.error(errorMessage);
}
Loggers.disableConsoleLogging();
if (logger.isDebugEnabled()) {
logger.debug("Exception", e);
}
System.exit(3);
}
main函数有省略,这里start函数调用node的start函数,node的start函数中将各个模块加载启动,从而启动整个系统。这一过程将在接下来进行分析。node启动后会注入hook,同时启动keepAliveThread,至此整个node就启动起来。
以上就是elasticsearch分布式及数据功能源码分析的详细内容,更多关于elasticsearch分布式及数据功能的资料请关注我们其它相关文章!
相关推荐
-
关于注解式的分布式Elasticsearch的封装案例
原生的Rest Level Client不好用,构建检索等很多重复操作. 对bboss-elasticsearch进行了部分增强:通过注解配合实体类进行自动构建索引和自动刷入文档,复杂的业务检索需要自己在xml中写Dsl.用法与mybatis-plus如出一辙. 依赖 <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> &
-
分布式全文检索引擎ElasticSearch原理及使用实例
一 什么是 ElasticSearch Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作: 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索. 可实现亿级数据实时查询 实时分析的分布式搜索引擎. 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据. 二 安装(wind
-

Elasticsearches的集群搭建及数据分片过程详解
目录 Elasticsearch高级之集群搭建,数据分片 广播方式 单播方式 选取主节点 什么是脑裂 错误识别 Elasticsearch高级之集群搭建,数据分片 es使用两种不同的方式来发现对方: 广播 单播 也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成 广播方式 当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328.而其他的es实例使用同样的集群名称响应了这个请求. 一般这个默认的集群名称就是上面的cluster_name对应的elastics
-
分布式难题ElasticSearch解决大数据量检索面试
目录 引言 1.面试官: 我看你简历有写项目里有使用了ES,哪些场景用到了ES? 2.面试官: 那使用了ES后结果如何? 3.面试官: 关于ES的一些概念名字你了解多少?如索引,文档,倒排索引这些东西你是怎么理解的? 最重要的倒排索引 总结 关于ES的特性是使用场景概括: 引言 如果你的项目里有超过千万上亿级别的数据,且数据日增量较大需要高性能检索时,如订单数据,你该怎么办? 作为面试官,你需要找一个能解决这个问题的人!为应聘者,你该如何回答面试官这个问题? 你可以了解下使用搜索引擎框架,Ela
-
Elasticsearch映射字段数据类型及管理
目录 Elasticsearch映射管理 一 映射介绍 1.1 字段数据类型 1.2 映射参数 二 创建索引 三 查看索引 Elasticsearch映射管理 在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个mapping type. 在5.x中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x中运行. Mapping types将在Elasticsearch 7.0.0中完全删除 一 映射介绍 在创建索引的时候
-
elasticsearch分布式及数据的功能源码分析
从功能上说,可以分为两部分,分布式功能和数据功能.分布式功能主要是节点集群及集群附属功能如restful借口.集群性能检测功能等,数据功能主要是索引和搜索.代码上这些功能并不是完全独立,而是由相互交叉部分.当然分布式功能是为数据功能服务,数据功能肯定也难以完全独立于分布式功能. 它的源码有以下几个特点: 模块化: 每个功能都以模块化的方式实现,最后以一个借口向外暴露,最终通过guice(google轻量级DI框架)进行管理.整个系统有30多个模块(version1.5). 接口解耦: es代码中
-
Android 截图功能源码的分析
Android 截图功能源码的分析 一般没有修改rom的android原生系统截图功能的组合键是音量减+开机键:今天我们从源码角度来分析截图功能是如何在源码中实现的. 在android系统中,由于我们的每一个Android界面都是一个Activity,而界面的显示都是通过Window对象实现的,每个Window对象实际上都是PhoneWindow的实例,而每个PhoneWindow对象都对应一个PhoneWindowManager对象,当我们在Activity界面执行按键操作的时候,在将按键的处
-
Netty分布式客户端接入流程初始化源码分析
目录 前文概述: 第一节:初始化NioSockectChannelConfig 创建channel 跟到其父类DefaultChannelConfig的构造方法中 再回到AdaptiveRecvByteBufAllocator的构造方法中 继续跟到ChannelMetadata的构造方法中 回到DefaultChannelConfig的构造方法 前文概述: 之前的章节学习了server启动以及eventLoop相关的逻辑, eventLoop轮询到客户端接入事件之后是如何处理的?这一章我们循序渐
-
elasticsearch索引index数据功能源码示例
从本篇开始,对elasticsearch的介绍将进入数据功能部分(index),这一部分包括索引的创建,管理,数据索引及搜索等相关功能.对于这一部分的介绍,首先对各个功能模块的分析,然后详细分析数据索引和搜索的整个流程. 这一部分从代码包结构上可以分为:index, indices及lucene(common)几个部分.index包中的代码主要是各个功能对应于lucene的底层操作,它们的操作对象是index的shard,是elasticsearch对lucene各个功能的扩展和封装.indic
-
PHP+jQuery实现自动补全功能源码
前面手工写了一个下拉自动补全功能,写的简单,只实现了鼠标选择的功能,不支持键盘选择.由于项目很多地方要用到这个功能,所以需要用心做一下.发现select2这个插件的功能可以满足当前需求. 在使用jquery插件select2的过程中遇到了一些疑惑,无论是穿json数据还是通过jsonp方式取数据,都能够正确返回.可是下拉列表中的条目却不能被选中,对鼠标和键盘选择都无效. 后来发现,select2插件在实现选中时是以数据中的id字段为准的.所以不管是json还是jsonp,ajax返回的数据都必须
-
asp下实现代码的“运行代码”“复制代码”“保存代码”功能源码
Function content_Code(Str) dim ary_String,i,n,n_pos ary_String=split(Str,"[ code ]") n=ubound(ary_String) If n<1 then content_Code=Str Exit function End If for i=1 to n n_pos=inStr(ary_String(i),"[/ code ]") If n_pos>0 then ary_S
-
C语言实现的统计php代码行数功能源码(支持文件夹、多目录)
放假在家没事,睡过懒觉,看过电影,就想起来写个小程序. 统计php代码的行数,对于phper还是挺实用的.支持单个文件和目录.下面是代码和演示的例子! /** * @date 2012-12-1 * @author bright * @todo 统计php代码行数 */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #inc
-
elasticsearch元数据构建metadata及routing类源码分析
目录 metadata部分 元数据部分主要包括 shardRouting,继承关系 总结 metadata部分 虽然在刚开始源码概述时把代码分为分布式和数据两部分,但是它们的界限并不明显.之前这几篇可以说是这两部分的衔接.我们在快速接近数据(index)部分.本篇分析一下之前分析cluster遗留下的问题:Metadata与routing,虽然这两部分的代码在cluster中,但是却直接和index相关. metadata部分主要是和索引相关的一些元数据构建和操作. 元数据部分主要包括 别名元数
-
ZooKeeper框架教程Curator分布式锁实现及源码分析
目录 如何使用InterProcessMutex 实现思路 代码实现概述 InterProcessMutex源码分析 实现接口 属性 构造方法 方法 获得锁 释放锁 LockInternals源码分析 获取锁 释放锁 总结 ZooKeeper入门教程一简介与核心概念 ZooKeeper入门教程二在单机和集群环境下的安装搭建及使用 ZooKeeper入门教程三分布式锁实现及完整运行源码 上一篇文章中,我们使用zookeeper的java api实现了分布式排他锁. Curator中有着更为标准.规