springcloud结合bytetcc实现数据强一致性原理解析
1 使用背景和约束
公司使用的是springcloud,面临分布式事务的场景的时候,可以使用对springcloud支持比较好的byte-tcc框架,git目前2600星,使用起来也非常方便,原理也很清晰,非常适合学习。 https://github.com/liuyangmin... ,结合cloud有几个重点约束如下,
(1)一个业务接口,需要有三种实现类,分别是try,confirm,cancel,符合tcc的思路。实现方法必须加Transactional,且propagation必须是Required, RequiresNew, Mandatory中的一种。
(2)服务提供方Controller必须添加@Compensable注解,不允许对Feign/Ribbon/RestTemplate等HTTP请求自行进行封装。想想看为什么?
(3)在每个参与tcc事务的数据库中创建bytejta表。
配置上也非常简单,@Import(SpringCloudConfiguration.class),服务提供方,try上面加上
@Service("accountService")
@Compensable(
interfaceClass = IAccountService.class
, confirmableKey = "accountServiceConfirm"
, cancellableKey = "accountServiceCancel"
)
confirm和cancel对应的
@Service("accountServiceConfirm")
@Service("accountServiceCancel"),
try confirm cancel 对应业务可以理解为 冻结库存/真正扣减库存/恢复库存,或者冻结优惠券/核销优惠券/恢复优惠券这种实际业务场景。
0.5以后datasource自动使用LocalXADataSource,之前需要手动配置
@Bean(name = "dataSource")
public DataSource getDataSource() {
LocalXADataSource dataSource = new LocalXADataSource();
dataSource.setDataSource(this.invokeGetDataSource());
return dataSource;
}
所以,从配置上看,bytetcc和springcloud结合,一个应该是通过引入自己的SpringCloudConfiguration封装了feign/ribbon/hystrix调用,一个是提供了自己的datasource管理事务。有了自己的datasource,定制自己的transactionManager,就可以在事务前后动手脚,2pc/3pc对事务的管理,体现在控制不同数据库连接上,微服务为主的tcc,对事务的管理体现在控制各个服务的调用上。
2 业务场景思考
bytetcc的tcc,其实try和cancel是配套的,考虑下业务场景:
(1)如果a服务try成功了,b服务try失败,则a服务需要回滚,调用a的cancel。这是普遍流程。
(2)如果a 和 b都try成功了,然后a confirm成功,b的confirm失败,是没有cancel和confirm配对的。b的confirm会不断调用直到成功为止。
因为bytetcc的设计思路是,通过try做好准备工作(如锁定资源),try如果能成功,那么逻辑上confirm一定要成功。如果confirm不成功,则可能是外部环境问题,如网络问题等,那么环境恢复了迟早应该成功confirm。基于这个思想,try和cancel是互逆的,confirm一旦执行就不可逆。
如果要设计confirm也可逆的,那要么cancel里判断是该回滚try还是回滚try+confirm,不清晰且实现很麻烦,或者做成“tccc”加一个对应confirm的cancel,由事务管理器统一判断调用几个cancel,引入太多不确定。所以业务上可以直接这么设计:try成功,那么confirm是一定要成功的。
3 核心组件SpringCloudConfiguration原理分析
第一步就import的SpringCloudConfiguration是重点,通过它的各种自动装配基本可以实现bytetcc的全逻辑。要想扩展spring,那就得扩展各种BeanFactoryPostProcessor,SpringCloudConfiguration本身就是个BeanFactoryPostProcessor,但是postProcessBeanFactory没干啥,应该是引入了各种其他processor进行扩展。如何扩展面临几个问题
(1) 如何识别核心的@Compensable注解?
在byte-tcc的一堆resource文件里,配置了各种bean。既然都Springcloud了为啥还用这种文件bean,可能是兼容cloud之外的场景,增强通用性。在bytetcc-supports-tcc.xml里,有个bean <bean class="org.bytesoft.bytetcc.supports.spring.CompensableAnnotationConfigValidator" />,通过关键代码
clazz.getAnnotation(Compensable.class);扫描得到所有注解了Compensable的类,同时解析出来cancel,confirm对应的类。同时校验一下有没有加transactional注解。后面很多类似的processor都是用这种注解识别需要的bean
(2)如何改造事务管理器,使之适应分布式微服务环境?
在bytetcc-supports-tcc.xml中,定义了改造过的transactionManager,
<bean id="transactionManager" class="org.bytesoft.bytetcc.TransactionManagerImpl" />
这里面重写了begin,commit那一套,结合了tcc专用组件CompensableManager,重新包装了事务操作。
同时,通过SpringCloudConfiguration配置的CompensableHandlerInterceptor,达到transactionInterceptor的效果。
(3)事务如何恢复?
在bytetcc-supports-logger-primary.xml中,有个ResourceAdapterImpl,这个是启动bytetcc后台线程的地方,看bean配置就知道,把两个bean compensableWork和bytetccCleanupWork注入到ResourceAdapterImpl中统一管理,字面意思上看是补偿任务和数据清理任务。这里的compensableWork就是补偿和数据恢复专用的job。
<bean id="compensableResourceAdapter" class="org.bytesoft.transaction.adapter.ResourceAdapterImpl">
<property name="workList">
<list>
<ref bean="compensableWork" />
<ref bean="bytetccCleanupWork" />
</list>
</property>
</bean>
追进去看,通过List<Work> workList收集起来work,然后统一用mananger进行start,看work对象本身就继承了Runnable,所以这里是开启了后台线程,进行事务恢复等操作。
(4)具体的请求接口,怎么扩展?
import的SpringCloudConfiguration的代理组件,通过条件注解和配置,根据是否开启hystrix和是否引入HystrixFeign的类,注入针对feign或hystrix的CompensableFeignBeanPostProcessor,如下
@org.springframework.context.annotation.Bean
@ConditionalOnProperty(name = "feign.hystrix.enabled", havingValue = "false", matchIfMissing = true)
public CompensableFeignBeanPostProcessor feignPostProcessor() {
return new CompensableFeignBeanPostProcessor();
}
@org.springframework.context.annotation.Bean
@ConditionalOnProperty(name = "feign.hystrix.enabled")
@ConditionalOnClass(feign.hystrix.HystrixFeign.class)
public CompensableHystrixBeanPostProcessor hystrixPostProcessor() {
return new CompensableHystrixBeanPostProcessor();
}
以CompensableFeignBeanPostProcessor为例,明显这就是为了对feign接口进行代理的PostProcessor,在postProcessAfterInitialization中,果然通过createProxiedObject(),创建了CompensableFeignHandler的代理类,对springcloud自己的FeignInvocationHandler进行了又一次代理。这样所有@FeignClient的接口都会经过这个handler
同理如果是hystrix的代理,CompensableHystrixBeanPostProcessor会创建CompensableHystrixFeignHandler代理,代替原来的CompensableHystrixInvocationHandler。
通过这两种代理,可以对原生的feign/hystrix组件继续代理,在请求前后做些事情。feign/hystrix其实本身也是结合了ribbon的代理,所以很多spring的扩展就是一层层的代理叠加,为我们扩展组件提供了一种思路。那么bytetcc的核心流程肯定就蕴含在这个请求代理中。
(5)如何控制请求哪一种方法?
bytetcc-supports-springcloud-primary.xml中,有个controller,CompensableCoordinatorController,可以看到里面封装了几种方法,prepare,commit,rollback,额外还有recover,forget,名字上可以看出是恢复,删除事务。结合第四点,原来的feign调用被代理一层,请求的真实url应该被改过,改成了请求这一个controller的方法,通过这个controller再决定后面做什么。
@RequestMapping(value = "/org/bytesoft/bytetcc/prepare/{xid}", method = RequestMethod.POST)
@RequestMapping(value = "/org/bytesoft/bytetcc/commit/{xid}/{opc}", method = RequestMethod.POST)
@RequestMapping(value = "/org/bytesoft/bytetcc/rollback/{xid}", method = RequestMethod.POST)
@RequestMapping(value = "/org/bytesoft/bytetcc/recover/{flag}", method = RequestMethod.GET)
@RequestMapping(value = "/org/bytesoft/bytetcc/forget/{xid}", method = RequestMethod.POST)
综上所述,通过新的分布式事务管理器的封装,feign/hystrix请求的代理,controller的控制,后台补偿任务的执行,基本上可以实现强一致性的分布式事务。
4 事务启动-try过程
(1)产生事务
接到用户一个请求时, CompensableHandlerInterceptor会先拦截,这是用户刚发的请求,在这里没找到事务信息什么都不干就返回true了,如果是被调用者,无论是try/confirm/cancel,都会有个事务上下文信息,解析出事务。
CompensableMethodInterceptor->excute(),获得了@transactional和@composable注解,包括 confirm/cancel方法信息,封装到invocation,保存本次调用的一些信息。
transactionInterceptor,调用bytetcc提供的TransactionManagerImpl,提供了新的begin,启动tcc事务。注意这里,如果没有事务上下文,没有compensable注解,那就走一般的begin,就是一般的本地事务。
有了compensable注解,begin就是上面说到的CompensableManager的compensableBegin方法,初始化了事务上下文环境transanctionContext,还生成了个事务id-xid。
(2)方法执行,CompensableFeignInterceptor,把上面生成的事物上下文环境transactionContext,通过序列化生成字符串,放入request的header中,这样发起事务无论调用什么服务,事务的上下文信息就保存在request的header里了。
后面根据feign的代理CompensableFeignHandler发出请求,return this.delegate.invoke(proxy, method, args) delegate就是feign,本质上也是使用原生的feign发请求。
既然本质也是feign调用,思考一下为啥还费事代理一次?事务上下文环境在interceptor里面已经设置到request里了,还代理干啥?
往后看,我认为关键在这里,
beanRegistry.setLoadBalancerInterceptor(new CompensableLoadBalancerInterceptor(this.statefully)
大家知道,feign通过ribbon组件进行的复杂均衡,即chooseInstance,选择请求往哪个实例上发,如果还是轮训或随机,第一次try请求发到某实例,第二次confirm/cancel发到其他实例,别的实例上没有try带来的的事务信息,会非常不方便,也不知道try到底什么情况,
所以这里要多次请求粘滞到一个实例上。所以bytetcc实现了ribbon算法CompensableLoadBalancerRuleImpl,不支持自定义rule
(3)服务接收方接受,首先经过CompensableHandlerInterceptor的preHandle,解析出事务上下文transactionContext,封装成TransactionRequestImpl,并在response里加上一些header信息。这在发起者那里因为没有header的上下文,所以在(1)是什么都不做的
再到 CompensableMethodInterceptor, 解析方法。
再到 TransactionManager,即bytetcc的TransactionManagerImpl,到这里的begin,由于刚接到请求的时候,这时候已经有事务了,所以调用的是一般的本地事务compensableManager.begin(),最后开启一个本地事务,然后执行本地方法,执行commit。
下图可以简单介绍这个过程。
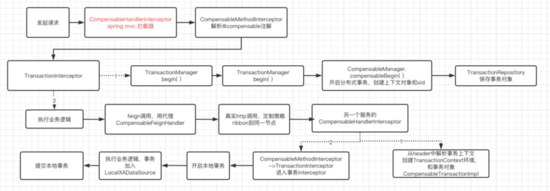
5 try调用失败,cancel过程
(1)如果有任意一个try失败,那么要把已经成功的try给回滚掉,spring通用的transactionInterceptor的处理过程,invokeWithinTransaction方法,如果有异常,catch住执行
completeTransactionAfterThrowing(),然后到transactionManagerImpl的rollback,继续到CompensableManager的collback
(2)CompensableTransanctionImpl中,fireRemoteParticipantCancel是真正的rollback,里面维护了一个resourcelist,按顺序记录了其他各个服务在try的时候调用的服务,在这里循环这个list调用SpringCloudCoordinator,拼接cancel地址,带着事务id发送请求过去。
(3)接收方,CompensableCoordinatorController的rollback,核心是从CompensableTransactionImpl到SpringContainerContextImpl 的 cancel,得到请求的controller的对应的cancel方法,封装到cancellableKey,然后拿到处理cancel的真实的bean,
Object instance = this.applicationContext.getBean(cancellableKey); this.cancelComplicated(method, instance, args);
进而执行cancel对应的bean的方法。整个过程可以如下概括
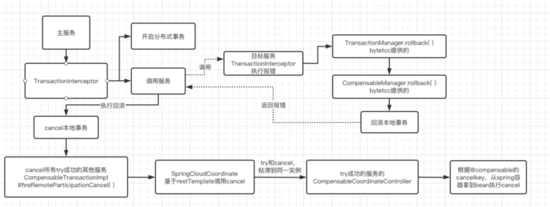
6 try成功,confirm过程
同理,transactionManagerImpl的commit,最终到达CompensableTransactionImp进行fireCommit,先提交本地事务,然后fireRemoteParticipantConfirm,和cancel一模一样,读取resourceList,遍历list发送请求到各个服务端。
各个服务方CompensableCoordinatorController的commit,拿到confirmablekey,找到confirm的bean进行confirm。
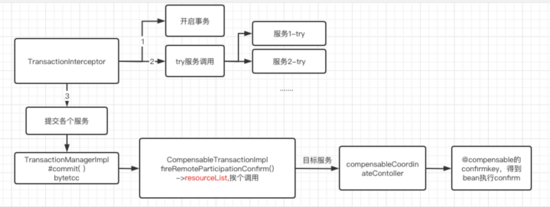
7 “compensable”的补偿
(1)如果cancel,commit有失败(失败包含runtimeexception和自定义的一些异常),那么如何进行补偿,上面提到的一开始就启动的CompensableWork线程的run里面,其实有个while(true),每隔100秒循环一次,调用组件TransactionRecovery(看名字就知道恢复事务用的)的timingRecover,就是定时回复,会调用到CompensableTransactionImpl的recoveryRollback/recoveryCommit,还是SpringCloudCoordinator发送的请求。
(2)如果出现宕机,重启后也是通过CompensableWork线程的run,第一步是init,尝试恢复现有的事务。
a 如果try没有执行完就down机,恢复时把已执行的try给cancel掉。因为事务一般是业务请求触发的,down机就请求失败了,没必要重启后还恢复刚才的请求。
b 如果是confirm/cancel有没成功的,会一直定时进行confirm/cancel。
到此这篇关于springcloud结合bytetcc实现数据强一致性原理剖析的文章就介绍到这了,更多相关springcloud实现数据强一致性内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Spring Cloud Gateway 数据库存储路由信息的扩展方案
动态路由背景 无论你在使用Zuul还是Spring Cloud Gateway 的时候,官方文档提供的方案总是基于配置文件配置的方式 例如: # zuul 的配置形式 routes: pig-auth: path: /auth/** serviceId: pig-auth stripPrefix: true # gateway 的配置形式 routes: - id: pigx-auth uri: lb://pigx-auth predicates: - Path=/auth/** filte
-
详解Spring Cloud 跨服务数据聚合框架
AG-Merge Spring Cloud 跨服务数据聚合框架 解决问题 解决Spring Cloud服务拆分后分页数据的属性或单个对象的属性拆分之痛, 支持对静态数据属性(数据字典).动态主键数据进行自动注入和转化, 其中聚合的静态数据会进行 一级混存 (guava). 举个栗子: 两个服务,A服务的某张表用到了B服务的某张表的值,我们在对A服务那张表查询的时候,把B服务某张表的值聚合在A服务的那次查询过程中 示例 具体示例代码可以看 ace-merge-demo 模块 |------- ac
-

springcloud结合bytetcc实现数据强一致性原理解析
1 使用背景和约束 公司使用的是springcloud,面临分布式事务的场景的时候,可以使用对springcloud支持比较好的byte-tcc框架,git目前2600星,使用起来也非常方便,原理也很清晰,非常适合学习. https://github.com/liuyangmin... ,结合cloud有几个重点约束如下, (1)一个业务接口,需要有三种实现类,分别是try,confirm,cancel,符合tcc的思路.实现方法必须加Transactional,且propagation必须是R
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
JVM运行时数据区原理解析
前言 Java虚拟机定义了若干种程序运行期间会使用的运行时数据区域,其中一些会随着虚拟机启动而创建,随着虚拟机的退出而销毁.另外一些则是和线程一一对应,这些与线程对应的数据区域随着线程开始而创建,线程的结束而销毁. PC寄存器 PC寄存器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器,每条线程都要一个独立的PC寄存器,这个内存也是线程私有的内存.正在执行 java 方法的话,PC寄存器是记录的是虚拟机字节码指令的地址(当前指令的地址).如果还是 Native 方法,则为und
-
分布式监控系统之Zabbix 使用SNMP、JMX信道采集数据的原理解析
前文我们了解了zabbix的被动.主动以及web监控相关话题,回顾请参考https://www.jb51.net/article/200679.htm:今天我们来了解下zabbix使用SNMP和JMX信道采集数据的相关话题: 1.SNMP协议介绍 SNMP是英文"Simple Network Management Protocol"的缩写,中文意思是"简单网络管理协议,SNMP是一种简单网络管理协议,它属于TCP/IP五层协议中的应用层协议,用于网络管理的协议,SNMP主要用
-
SpringCloud Eureka自我保护机制原理解析
这篇文章主要介绍了SpringCloud Eureka自我保护机制原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1. 自我保护机制演示 eureka在频繁修改微服务名称的时候,可以会出现如下现象: 2. 什么是自我保护模式? 默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒).但是当网络分区故障发生时,微服务与EurekaServer之间无法正常通信
-
SpringCloud配置刷新原理解析
我们知道在SpringCloud中,当配置变更时,我们通过访问http://xxxx/refresh,可以在不启动服务的情况下获取最新的配置,那么它是如何做到的呢,当我们更改数据库配置并刷新后,如何能获取最新的数据源对象呢?下面我们看SpringCloud如何做到的. 一.环境变化 1.1.关于ContextRefresher 当我们访问/refresh时,会被RefreshEndpoint类所处理.我们来看源代码: /* * Copyright 2013-2014 the original a
-
Pandas数据离散化原理及实例解析
这篇文章主要介绍了Pandas数据离散化原理及实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具 扔掉一些信息,可以让模型更健壮,泛化能力更强 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值 分箱 案例 1.
-
从云数据迁移服务看MySQL大表抽取模式的原理解析
摘要:MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 小编最近在云上的一个迁移项目中被MySQL抽取模式折磨的很惨.一开始爆内存被客户怼,再后来迁移效率低下再被怼.MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 1.1 Java-JDBC通信原理 JDBC与数据库之间的通信是通过socket完,大致流程如下图所示.Mysql Server ->内核Socket Buffer -> 客户端Socket Buffer ->JDBC所在的JV
-
vue.js数据响应式原理解析
目录 Object.defineProperty() 定义 defineReactive 函数 递归侦测对象的全部属性 流程分析 observe 函数 Observer 类 完善 defineReactive 函数 One More Thing Object.defineProperty() 得力于 Object.defineProperty() 的特性,vue 的数据变化有别于 react 和小程序,是非侵入式的.详细介绍可以看 MDN 文档,这里特别说明几点: get / set 属性是函数
-
ThreadLocal数据存储结构原理解析
目录 一:简述 二:TheadLocal的原理分析 1.ThreadLocal的存储结构 2.源码分析 set()方法 三:源码分析 createMap() 源码: 流程图: expungeStaleEntry() cleanSomeSlots() rehash() resize() get()方法 getEntry() getEntryAfterMiss() remove() 四:总结 一:简述 我们很多时候为了实现数据在线程级别下的隔离,会使用到ThreadLocal,那么TheadLoca