Python插件机制实现详解
插件机制是代码/功能反向依赖注入到主体程序的一种方法,编译型语言通过动态加载动态库实现插件。对于Python这样的脚本语言,实现插件机制更简单。
机制
Python的__import__方法可以动态地加载Python文件,即以某个py脚本的文件名作为__import__的参数,在程序运行的时候加载py脚本程序模块。对应的import关键字则是静态加载依赖的py模块。
描述
__import__() 函数用于动态加载类和函数 。
如果一个模块经常变化就可以使用 __import__() 来动态载入。
语法
__import__ 语法:
__import__(name[, globals[, locals[, fromlist[, level]]]])
参数说明:
name -- 模块名
需要动态加载的py脚本若存放在任意的目录下,则需要首先需要增加脚本查找路径:
sys.path.append(modulePath)
应用示例
# 增加查找路径 sys.path.append(modulePath) # 加载脚本 module = __import__(moduleName) # 保存脚本对象,否则会被析构 self.modules[moduleName] = module # 调用插件中的方法初始化 module.InitModule(self)
总结
使用插件机制可以实现高内聚低耦合的程序。
在实践中,我们处理的任务有若干的可执行程序配合完成,可执行程序可以是C++,.Net , Java,甚至其他脚本程序,这时候我们使用Python作为粘合剂,定义了主体的任务流程框架,使用插件机制动态的注入需要执行的任务。
另外当在不同的情况下,需要使用不同的exe配合的时候,我们只需要用json定义需要的exe组合,主程序不需要做任何的更改就可以满足变换的业务需求。
补充知识:Kusto使用python plugin
整个流程为kusto的数据进入python脚本时自动转化为pandas DataFrame,
python 脚本的输出自动转化为kusto table,其中列名和变量都保持不变。
Python 脚本紧接着Kusto的输出

注意以下几点
1.typeof为python脚本输出的参数
2.typeof 中的数据类型跟python脚本输出pandas DataFrame列是完全一致的,包括变量名,变量类型,前后不一致的话会报错
3.typeof 中*表示复用输入的数据类型, 比如( *,age:int) 表示输入在输出的基础上多个了age属性
4. python脚本的输入是转化为DataFrame 的kusto table, 其在python脚本里的变量名为df(会自动匹配上), 同时我们要让输出的DataFrame 命名为result, 程序会自动输出
5. python 中可以接受外界参数,通过 kargs["topK"]这样的形式,kargs是系统默认的传递参数的变量, 同时kusto在python脚本的最后通过pack("topK", 10)这样的形式往python脚本中传递参数
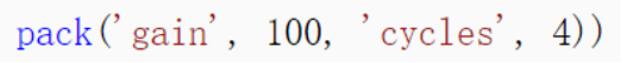
6 .python脚本可以直接写在kusto代码中,也可以以链接的形式访问

7. kusto 中的python运行企业版的anaconda上,个人没法轻易安装自己想要的包,所以如果要使用某些包,最好是将其功能用最基本的包写好。kusto 运行镜像的沙盒支持 numpy ,pd, 以及tensorflow ,keras ,torch hdbscan, xgboost 这些比较大众的包
以上这篇Python插件机制实现详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现简单加密解密机制
本文使用python实现一个简单的加密解密机制. 描述:结合26个字母.以一个单词作为秘钥,使用python实现简单的加密解密机制 秘钥:大写的英文字符串 明文:包含空格.大小写字母.数字等的字符串 代码实现: # -*- coding: utf-8 -*- import os,sys reload(sys) sys.setdefaultencoding('utf8') import string def suanfa(key): alp = 'ABCDEFGHIJKLMNOPQRSTUVWXY
-
python实现异步回调机制代码分享
1 将下面代码拷贝到一个文件,命名为asyncore.py 复制代码 代码如下: import socketimport selectimport sys def ds_asyncore(addr,callback,timeout=5): s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(addr) r,w,e = select.select([s],[],[],timeout) if r:
-
python轮询机制控制led实例
我就废话不多说了,大家还是直接看代码吧! # -*- coding:utf-8 -*- # File: ceshitianqi import urllib2 import json import time import datetime import serial import random import os import sys APIKEY = 'ZPdLyl***=' #改成你的APIKEY ser=serial.Serial("/dev/ttyUSB2",9600,timeo
-

基于Python开发chrome插件的方法分析
本文实例讲述了基于Python开发chrome插件的方法.分享给大家供大家参考,具体如下: 谷歌Chrome插件是使用HTML.JavaScript和CSS编写的.如果你之前从来没有写过Chrome插件,我建议你读一下这个.在这篇教程中,我们将教你如何使用Python代替JavaScript. 创建一个谷歌Chrome插件 首先,我们必须创建一个清单文件:manifest.json. { "manifest_version": 2, "name": "Py
-
Python插件机制实现详解
插件机制是代码/功能反向依赖注入到主体程序的一种方法,编译型语言通过动态加载动态库实现插件.对于Python这样的脚本语言,实现插件机制更简单. 机制 Python的__import__方法可以动态地加载Python文件,即以某个py脚本的文件名作为__import__的参数,在程序运行的时候加载py脚本程序模块.对应的import关键字则是静态加载依赖的py模块. 描述 __import__() 函数用于动态加载类和函数 . 如果一个模块经常变化就可以使用 __import__() 来动态载入
-
Python多进程机制实例详解
本文实例讲述了Python多进程机制.分享给大家供大家参考.具体如下: 在以前只是接触过PYTHON的多线程机制,今天搜了一下多进程,相关文章好像不是特别多.看了几篇,小试了一把.程序如下,主要内容就是通过PRODUCER读一个本地文件,一行一行的放到队列中去.然后会有相应的WORKER从队列中取出这些行. import multiprocessing import os import sys import Queue import time def writeQ(q,obj): q.put(o
-
mybatis的插件机制示例详解
前言 Mybatis作为一个应用广泛的优秀的ORM框架,已经成了JavaWeb世界近乎标配的部分,这个框架具有强大的灵活性,在四大组件(Executor.StatementHandler.ParameterHandler.ResultSetHandler)处提供了简单易用的插件扩展机制.Mybatis对持久层的操作就是借助于四大核心对象.MyBatis支持用插件对四大核心对象进行拦截,对mybatis来说插件就是拦截器,用来增强核心对象的功能,增强功能本质上是借助于底层的动态代理实现的,换句话说
-
Python代码块及缓存机制原理详解
这篇文章主要介绍了Python代码块及缓存机制原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.相同的字符串在Python中地址相同 s1 = 'panda' s2 = 'panda' print(s1 == s2) #True print(id(s1) == id (s2)) #True 2.代码块: 所有的代码都需要依赖代码块执行. 一个模块,一个函数,一个类,一个文件等都是一个代码块 交互式命令中, 一行就是一个代码块
-
Python进阶之import导入机制原理详解
目录 前言 1. Module组成 1.1 Module 内置全局变量 2. 包package 2.1 实战案例 3.sys.modules.命名空间 3.1 sys.modules 3.2 命名空间 4. 导入 4.1 绝对导入 4.2 相对导入 4.3 单独导入包 5. import运行机制 5.1 标准import,顶部导入 5.2 嵌套import 前言 在Python中,一个.py文件代表一个Module.在Module中可以是任何的符合Python文件格式的Python脚本.了解Mo
-
Java的SPI机制实例详解
Java的SPI机制实例详解 SPI的全名为Service Provider Interface.普通开发人员可能不熟悉,因为这个是针对厂商或者插件的.在java.util.ServiceLoader的文档里有比较详细的介绍.究其思想,其实是和"Callback"差不多."Callback"的思想是在我们调用API的时候,我们可以自己写一段逻辑代码,传入到API里面,API内部在合适的时候会调用它,从而实现某种程度的"定制". 典型的是Colle
-
Python爬虫天气预报实例详解(小白入门)
本文研究的主要是Python爬虫天气预报的相关内容,具体介绍如下. 这次要爬的站点是这个:http://www.weather.com.cn/forecast/ 要求是把你所在城市过去一年的历史数据爬出来. 分析网站 首先来到目标数据的网页 http://www.weather.com.cn/weather40d/101280701.shtml 我们可以看到,我们需要的天气数据都是放在图表上的,在切换月份的时候,发现只有部分页面刷新了,就是天气数据的那块,而URL没有变化. 这是因为网页前端使用
-
python 错误处理 assert详解
assert是断言的意思,解释为:我断定这个程序执行之后或者之前会有这样的结果,如果不是,那就扔出一个错误. 语法: assert expression [, arguments] assert 表达式 [, 参数] 举例: def foo(s): n = int(s) assert n != 0, 'n is zero!' return 10 / n def main(): foo('0') >Traceback (most recent call last): ... AssertionEr
-
python多线程超详细详解
python中的多线程是一个非常重要的知识点,今天为大家对多线程进行详细的说明,代码中的注释有多线程的知识点还有测试用的实例. import threading from threading import Lock,Thread import time,os ''' python多线程详解 什么是线程? 线程也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位. 线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其他线程
-
Python Tkinter之事件处理详解
目录 事件绑定方法 常用事件类型 Event事件对象 事件处理,是 GUI 程序中不可或缺的重要组成部分,相比来说,控件只是组成一台机器的零部件, 而事件处理则是驱动这台机器“正常”运转的关键所在,它能够将零部件之间“优雅”的贯穿起来,因此“事件处理”可谓是 GUI 程序的“灵魂”,同时它也是实现人机交互的关键. 对于“事件”这一名词,在讲解控件时也偶尔提及过,在本节我们将对 Tkinter 中的事件处理机制做更为详细的介绍. 在一款 GUI 程序中,我们将用户对软件的操作统称为“事件”,比如鼠