python中的标准库html
目录
- python之标准库html
- __init__.py文件提供两个函数:
- html库中的 entities 模块
- html库中的 parser 模块
python之标准库html
html库是用于解析HTML的一个工具,是python自带的标准库之一。
html库位置:

__init__.py文件提供两个函数:
__all__ = ['escape', 'unescape']
介绍 escape 和 unescape:
escape(s, quote=True) #用来将特殊字符进行转义成实体字符 """ 参数介绍: s 指定要转义的特殊字符 quote 默认为True,表示要将 " 或者 ' 也要转义成实体字符,False反之不用转义成实体字符 """ unescape(s) #用来将实体字符进行还原到特殊字符
escape 和 unescape 的使用:
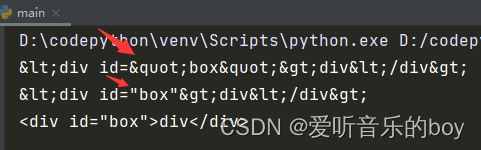
import html s = '<div id="box">div</div>' res = html.escape(s) print(res) print(html.escape(s,quote=False)) print(html.unescape(res)) #理解还原即可
输出结果:
escape源码的实现:

html库中的 entities 模块
该模块定义: HTML字符实体引用。
该模块提供四个字典对象:
__all__ = ['html5', 'name2codepoint', 'codepoint2name', 'entitydefs']
导入:
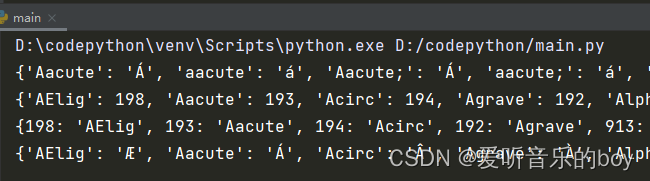
from html import entities html = entities.html5 name2codep = entities.name2codepoint codep = entities.codepoint2name ent = entities.entitydefs print(html) print(name2codep) print(codep) print(ent)
输出结果:
html库中的 parser 模块
该模块是HTML和XHTML的解析器。
该模块提供一个类:
__all__ = ['HTMLParser']
导入:
from html import parser htmlParser=parser.HTMLParser()
介绍该类的常用属性和常用方法:
常用属性:
lasttag #保存上一个解析的标签名,返回字符串。
已实现的常用方法:
feed(data) #将数据馈送到解析器。无返回值 unescape(s) #往上看,前面有介绍的 get_starttag_text() #返回开始标记的完整来源 close() #关闭
未实现的常用方法:
注意:这些方法在源码中都没有具体实现,需要我们定义一个子类继承自HTMLParser类,在子类中重写这些方法,实现自己逻辑
handle_starttag(tag, attrs) #处理开始标签,如 <div>;这里的attrs获取到的是属性列表,属性以元组的方式展示 handle_endtag(tag) #处理结束标签, 如 </div> handle_data(data) #处理数据,标签之间的文本 handle_comment(data) #处理注释,<!-- - -> 之间的文本 handle_startendtag(tag, attrs) #处理自己结束的标签,如 <img />
以上方法在源码中是这样的:



到此这篇关于python之标准库html的文章就介绍到这了,更多相关python标准库html内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
200个Python 标准库总结
目录 1.文本 2.数学 3.函数式编程 4.文件与目录 5.持久化 6.压缩 7.加密 8.操作系统工具 9.并发 10.进程间通信 11.互联网 12.互联网协议与支持 13.多媒体 14.国际化 15.编程框架 16.Tk图形用户接口 17.开发工具 18.调试 19.运行时 20.解释器 21.导入模块 22.Python语言 23.其他 24.Windows相关 25.Unix相关 1.文本 string:通用字符串操作 re:正则表达式操作 difflib:差异计算工具 textwr
-
python 标准库原理与用法详解之os.path篇
os中的path 查看源码会看到,在os.py中有这样几行 if 'posix' in _names: name = 'posix' linesep = '\n' from posix import * #省略若干代码 elif 'nt' in _names: from nt import * try: from nt import _exit __all__.append('_exit') except ImportError: pass import ntpath as path #...
-
Python标准库calendar的使用方法
目录 Calendar calendar.Calendar(firstweekday=0)类 calendar.TextCalendar(firstweekday=0) calendar.HTMLCalendar(firstweekday=0) 此模块允许你输出类似Unix cal程序的日历,并提供与日历相关的其他有用功能.值得注意的是,默认情况下,这些日历将星期一作为一周的第一天,将星期日作为一周的最后一天(欧洲惯例).不过,我们可以使用setfirstweekday()方法来设置一周的第一
-
Python标准库中的sys你了解吗
目录 sys作用 常用变量 sys.version sys.maxsize sys.maxunicode sys.path sys.platform sys.argv sys.executable sys.byteorder sys.version_info sys.api_version sys.stdin/sys.stdout/sys.stderr 常用方法 sys.exit() sys.modules sys.modules.keys() sys.getdefaultencoding()
-

Python标准库之time库的使用教程详解
目录 1.时间戳 2.结构化时间对象 3.格式化时间字符串 4.三种格式之间的转换 time模块中的三种时间表示方式: 时间戳 结构化时间对象 格式化时间字符串 1.时间戳 时间戳1970.1.1到指定时间到间隔,单位是秒 import time print(time.time()) 输出: 1649834054.98593 计算一个小时之前的时间戳 #计算一个小时之前的时间戳 print(time.time() - 3600) 输出: 1649830637.5699048 2.结构化时间对象
-
python中的标准库html
目录 python之标准库html __init__.py文件提供两个函数: html库中的 entities 模块 html库中的 parser 模块 python之标准库html html库是用于解析HTML的一个工具,是python自带的标准库之一.html库位置: __init__.py文件提供两个函数: __all__ = ['escape', 'unescape'] 介绍 escape 和 unescape: escape(s, quote=True) #用来将特殊字符进行转义成实体
-
利用Python中的mock库对Python代码进行模拟测试
如何不靠耐心测试 通常,我们编写的软件会直接与那些我们称之为"肮脏的"服务交互.通俗地说,服务对我们的应用来说是至关重要的,它们之间的交互是我们设计好的,但这会带来我们不希望的副作用--就是那些在我们自己测试的时候不希望的功能. 比如,可能我们正在写一个社交软件并且想测试一下"发布到Facebook的功能",但是我们不希望每次运行测试集的时候都发布到Facebook上. Python的unittest库中有一个子包叫unittest.mock--或者你把它声明成一
-
Python新手学习标准库模块命名
与Python标准库模块命名冲突 Python的一个优秀的地方在于它提供了丰富的库模块.但是这样的结果是,如果你不下意识的避免,很容易你会遇到你自己的模块的名字与某个随Python附带的标准库的名字冲突的情况(比如,你的代码中可能有一个叫做email.py的模块,它就会与标准库中同名的模块冲突). 这会导致一些很粗糙的问题,例如当你想加载某个库,这个库需要加载Python标准库里的某个模块,结果呢,因为你有一个与标准库里的模块同名的模块,这个包错误的将你的模块加载了进去,而不是加载Python标
-
Python基础之标准库和常用的第三方库案例教程
Python基础:标准库和常用的第三方库 Python的标准库有: 名称 作用 datetime 为日期和时间处理同时提供了简单和复杂的方法. zlib 直接支持通用的数据打包和压缩格式:zlib,gzip,bz2,zipfile,以及 tarfile. random 提供了生成随机数的工具. math 为浮点运算提供了对底层C函数库的访问. sys 工具脚本经常调用命令行参数.这些命令行参数以链表形式存储于 sys 模块的 argv 变量. glob 提供了一个函数用于从目录通配符搜索中生成文
-
python深度学习标准库使用argparse调参
目录 前言 使用步骤: 常见规则 使用config文件传入超参数 argparse中action的可选参数store_true 前言 argparse是深度学习项目调参时常用的python标准库,使用argparse后,我们在命令行输入的参数就可以以这种形式python filename.py --lr 1e-4 --batch_size 32来完成对常见超参数的设置.,一般使用时可以归纳为以下三个步骤 使用步骤: 创建ArgumentParser()对象 调用add_argument()方法添
-
python进阶collections标准库使用示例详解
目录 前言 namedtuple namedtuple的由来 namedtuple的格式 namedtuple声明以及实例化 namedtuple的方法和属性 OrderedDict popitem(last=True) move_to_end(key, last=True) 支持reversed 相等测试敏感 defaultdict 小例子1 小例子2 小例子3 Counter对象 创建方式 elements() most_common([n]) 应用场景 deque([iterable[,
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
对python中的xlsxwriter库简单分析
一.xlsxwriter 基本用法,创建 xlsx 文件并添加数据 官方文档:http://xlsxwriter.readthedocs.org/ xlsxwriter 可以操作 xls 格式文件 注意:xlsxwriter 只能创建新文件,不可以修改原有文件.如果创建新文件时与原有文件同名,则会覆盖原有文件 Linux 下安装: sudo pip install XlsxWriter Windows 下安装: pip install XlsxWriter # coding=utf-8 from
-
Python中logging日志库实例详解
logging的简单使用 用作记录日志,默认分为六种日志级别(括号为级别对应的数值) NOTSET(0) DEBUG(10) INFO(20) WARNING(30) ERROR(40) CRITICAL(50) special 在自定义日志级别时注意不要和默认的日志级别数值相同 logging 执行时输出大于等于设置的日志级别的日志信息,如设置日志级别是 INFO,则 INFO.WARNING.ERROR.CRITICAL 级别的日志都会输出. |2logging常见对象 Logger:日志,
-
Python中的wordcloud库安装问题及解决方法
今天下载wordcloud的时候出现了很多问题,在此总结总结 1.问题一:You are using pip version 19.0.3, however version 20.0.2 is available-问题 解决方法: 打开cmd输入如下命令 python -m pip install -U pip 2.问题二:error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual 解决方法: 方法1(不