Python爬虫必备之Xpath简介及实例讲解
目录
- 前言
- 一、Xpath简介
- 二、Xpath语法规则
- 语法规则
- 标签定位
- 属性定位
- 索引定位
- 取文本内容
- 三、语法规则练习
- 总结
前言
网上已经有很多大佬发过Xpath,而且讲的都很好,我是因为刚开始学习网络爬虫,对这些基础重要知识不太了解,所以写一下来加深印象,本篇文章只是简单介绍一下Xpath及使用,总体来说比较基础。
一、Xpath简介
XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言。
Xpath以XML为基础,提供用户在数据结构树中寻找节点的能力,Xpath被很多开发者亲切的称为小型查询语言。
二、Xpath语法规则
xpath可以使用路径表达式在XML上选取节点,从而达到确认元素的目的,我们先来介绍以下语法规则。
语法规则
| 表达式 | 作用 |
|---|---|
| nodename | 选取此层级节点下的所有子节点 |
| / | 代表从根节点进行选取 |
| // | 可以理解为匹配,就是在所有节点中选取此节点,直到匹配为止 |
| . | 选取当前节点 |
| … | 选取当前节点上一层(上一级目录) |
| @ | 选取属性(也是匹配) |
标签定位
| 方式 | 效果 |
|---|---|
| /html/body/div | 表示从根节点开始寻找,标签与标签之间/表示一个层级 |
| /html//div | 表示多个层级 作用于两个标签之间(也可以理解为在html下进行匹配寻找标签div) |
| //div | 从任意节点开始寻找,也就是查找所有的div标签 |
| ./div | 表示从当前的标签开始寻找div |
属性定位
| 需求 | 格式 |
|---|---|
| 定位div中属性名为href,属性值为‘www.baidu.com’的div标签 | @属性名=属性值 |
| href为属性名 'www.baidu.com’为属性值 | /html/body/div[href=‘www.baidu.com’] |
索引定位
| 需求 | 格式 |
|---|---|
| 定位ul下第二个li标签(下图) | //ul/li[2] |
| 索引值开始位置为 | 1 |
取文本内容
| 方法 | 效果 |
|---|---|
| /text() | 获取标签下直系的标签内容 |
| //text() | 获取标签中所有的文本内容 |
| string() | 获取标签中所有的文本内容 |
在网页上获取Xpath其实很容易,直接找到标签后,右键复制就好了。
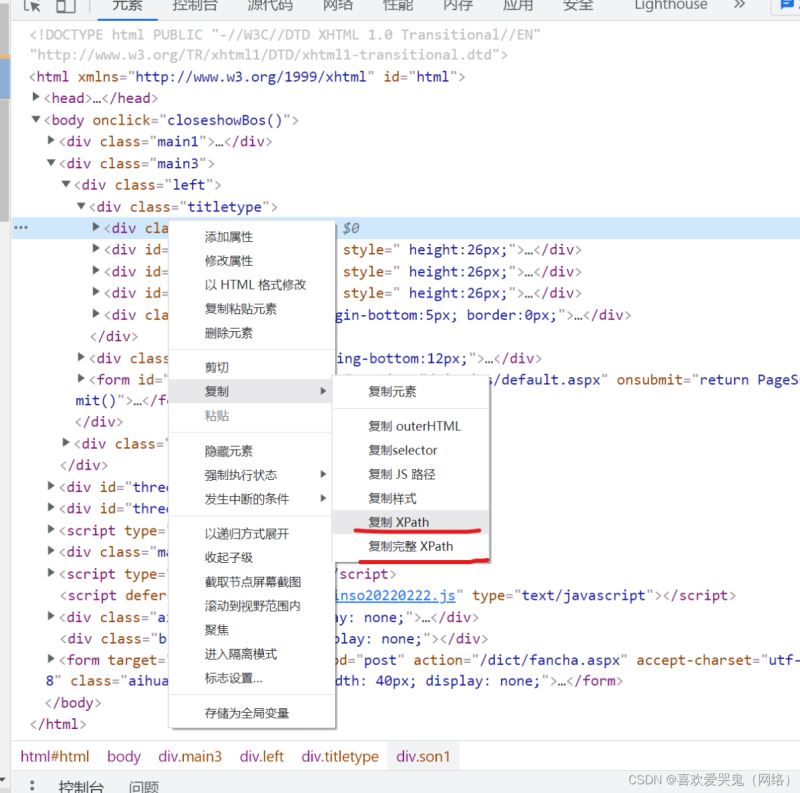
三、语法规则练习
接下来我们开始练习一下本地导入,加深一下理解,这个是一个比较简单的网页结构,我们先学会用法即可。
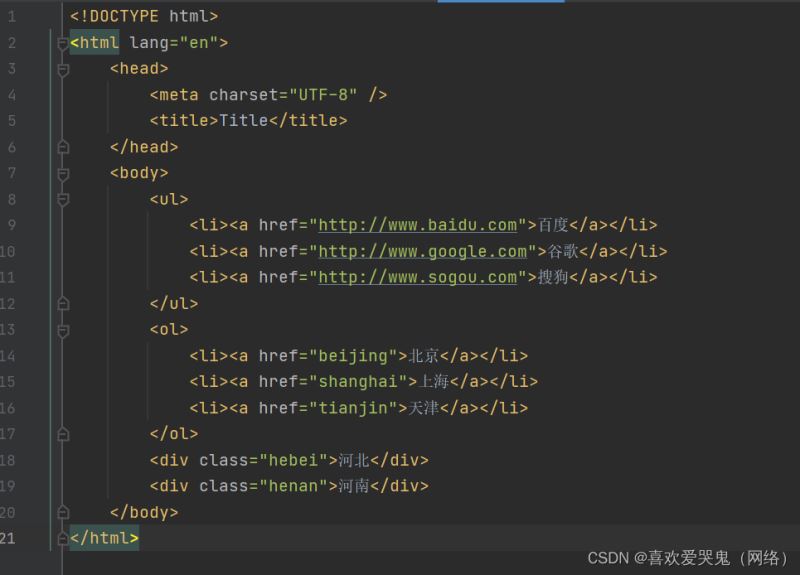
任务要求: 可以达到随心所欲的定位每一个元素
准备工作
#导入所需要的包
from lxml import etree
#采用本地源码获取方式并加载到etree内
tree = etree.parse('test.html')
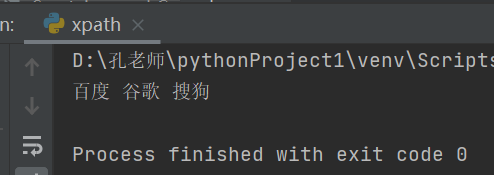
1.获取百度、谷歌、搜狗文本内容
#引用xpath方法并进行标签定位
#''.join是取字符串内的内容
text = ' '.join(tree.xpath('/html/body/ul/li/a/text()'))
print(text)
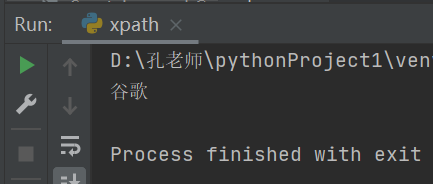
2.获取单个谷歌
text1 = tree.xpath("//ul/li[2]/a/text()")[0]
print(text1)
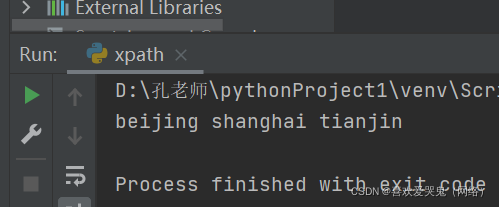
3.获取北京、上海、天津的属性值
text2 = ' '.join(tree.xpath("//ol/li/a/@href"))
print(text2)
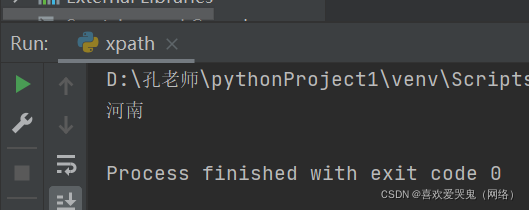
4.获取河南文本
#获取河南文本
text3 = tree.xpath("/html/body/div[2]/text()")[0]
print(text3)
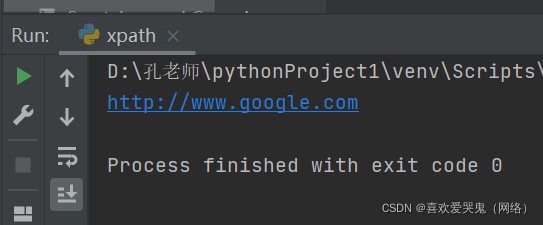
5.获取谷歌属性值
text4 = tree.xpath("//ul/li[2]/a/@href")[0]
print(text4)
至此我们已经可以随心定位任意标签 完成任务 收工
总结
到此这篇关于Python爬虫必备之Xpath简介及实例的文章就介绍到这了,更多相关Python爬虫Xpath实例内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python定位xpath 节点位置的方法
chrome 右键有copy xpath地址 但是有些时候获取的可能不对 可以自己用代码验证一下 如果还是不行 可以考虑从源码当中取出来 趁热打铁,使用前一篇文章中 XPath 节点来定位HTML 页面. HTML文件如下(您可以将其拷贝,保存成html文件,跟我笔者实验): <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title
-
关于python中的xpath解析定位
爬取的网站:http://jbk.39.net/chancegz/ 这里只针对个别属性值: #例如:'别名'下的span标签文本,'发病部位'下的span标签文本以及'挂号科室'下的span标签文本 # def disease(url): text = get_html(url) tree = etree.HTML(text) bm = tree.xpath('//ul[@class="information_ul"]/li/i[text()="别名:"]/foll
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
Python使用xpath实现图片爬取
高性能异步爬虫 目的:在爬虫中使用异步实现高性能的数据爬取操作 异步爬虫的方式: - 多线程.多进程(不建议): 好处:可以为相关阻塞的操作单独开启多线程或进程,阻塞操作就可以异步执行; 弊端:无法无限制的开启多线程或多进程. - 线程池.进程池(适当的使用): 好处:我们可以降低系统对进程或线程创建和销毁的一个频率,从而很好的降低系统的开销: 弊端:池中线程或进程的数据是有上限的. 代码如下 # _*_ coding:utf-8 _*_ """ @FileName :6.4
-

python爬虫之xpath的基本使用详解
一.简介 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上. 二.安装 pip3 install lxml 三.使用 1.导入 from lxml import etree 2.基本使用 from lxml import etree wb_data = """ <div> <u
-
python Xpath语法的使用
一.XMl简介 (一)什么是 XML XML 指可扩展标记语言(EXtensible) XML 是一种标记语言,很类似 HTML. XML 的设计宗旨是传输数据,而非显示数据. XML 的标签需要我们自行定义. XML 被设计为具有自我描述性. XML 是 W3C 的推荐标准. W3School 官方文档:http://www.w3school.com.cn/xml/index.asp (二)XML 和 HTML 的区别 他们两者都是用于操作数据或者结构数据,在结构上大致相同的,但他们在本质上却
-
Python中利用xpath解析HTML的方法
在进行网页抓取的时候,分析定位html节点是获取抓取信息的关键,目前我用的是lxml模块(用来分析XML文档结构的,当然也能分析html结构), 利用其lxml.html的xpath对html进行分析,获取抓取信息. 首先,我们需要安装一个支持xpath的python库.目前在libxml2的网站上被推荐的python binding是lxml,也有beautifulsoup,不嫌麻烦的话还可以自己用正则表达式去构建,本文以lxml为例讲解. 假设有如下的HTML文档: <html> <
-
Python爬虫必备之Xpath简介及实例讲解
目录 前言 一.Xpath简介 二.Xpath语法规则 语法规则 标签定位 属性定位 索引定位 取文本内容 三.语法规则练习 总结 前言 网上已经有很多大佬发过Xpath,而且讲的都很好,我是因为刚开始学习网络爬虫,对这些基础重要知识不太了解,所以写一下来加深印象,本篇文章只是简单介绍一下Xpath及使用,总体来说比较基础. 一.Xpath简介 XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言. Xpath以XML为基础,提供用户
-
Python爬虫必备之XPath解析库
一.简介 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上. Xpath解析库介绍:数据解析的过程中使用过正则表达式, 但正则表达式想要进准匹配难度较高, 一旦正则表达式书写错误, 匹配的数据也会出错. 网页由三部分组成: HTML, Css, JavaScript, HTML页面标签存在层级关系, 即DOM树,
-
python爬虫中抓取指数的实例讲解
有一些数据我们是没法直观的查看的,需要通过抓取去获得.听到指数这个词,有的小伙伴们觉得很复杂,似乎只在股票的时候才听说的,比如一些数据的涨跌分析都是比较棘手的问题.不过指数对于我们的数据分析还是很有帮助的,今天小编就python爬虫中抓取指数得方法给大家带来讲解. 刚好这几天需要用到这个爬虫,结果发现baidu指数的请求有点变化,所以就改了改: import requests import sys import time word_url = 'http://index.baidu.com/ap
-
Python爬虫UA伪装爬取的实例讲解
在使用python爬取网站信息时,查看爬取完后的数据发现,数据并没有被爬取下来,这是因为网站中有UA这种请求载体的身份标识,如果不是基于某一款浏览器爬取则是不正常的请求,所以会爬取失败.本文介绍Python爬虫采用UA伪装爬取实例. 一.python爬取失败原因如下: UA检测是门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求.如果检测到请求的载体身份标识不是基于某一款浏览器的.则表示该请求为不正常的请求,则服务器端就很有可能会
-
python爬虫指南之xpath实例解析(附实战)
目录 前言 环境的安装 属性定位 索引定位 取文本 取属性 总结 前言 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索 XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串.数值.时间的匹配以及节点.序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择 xpath解析原理: 1.实现标签的定位:实例
-
python爬虫用scrapy获取影片的实例分析
我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情.周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题.那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧. 1. 创建项目 运行命令: scrapy startproject myfrist(your_project_name) 文件说明: 名称 | 作用 --|-- scrapy.cfg | 项目的配置信息
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
-
Python 网络爬虫--关于简单的模拟登录实例讲解
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号.密码等等. 模拟登录一个网站大致分为这么几步: 1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存) 2.将信息进行提交 3.获取登录后的信息 先给上源码 <span style="font-size: 14px;"># -*- coding: utf-8 -*- import requests def login(): sessi
-
python爬虫之模拟登陆csdn的实例代码
python模拟登陆网页主要使用到urllib.urllib2.cookielib及BeautifulSoup等基本模块,当然进阶阶段我们还可以使用像requests等更高级一点的模块.其中BeautifulSoup模块在匹配html方面,可以很好的代替re,使用起来更方便,对于不会使用正则的人来说是福音. 本文使用python2.7 原理 模拟登陆前,我们需要先知道csdn是如何登陆的.我们通过google chrome浏览器先来分析下: 1.chrome浏览器用F12或ctrl+shift+
-
python 爬虫 批量获取代理ip的实例代码
实例如下所示: import urllib.request import os, re,sys,time try: from StringIO import StringIO except ImportError: from io import StringIO loca = re.compile(r"""ion":"\D+", "ti""") #伪装成浏览器 header = {'User-Agent':