python文件读取和导包的绝对路径、相对路径详解
目录
- 一、文件读取的绝对路径和相对路径
- 二、package的绝对路径及相对路径导入
- 2.1 导包以绝对路径导入
- 2.2 导包以相对路径导入
- 三、运行脚本的当前工作路径和绝对路径
- 总结
文件目录层级
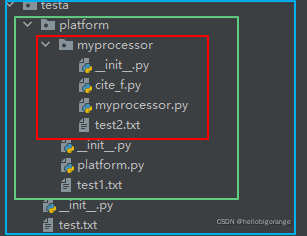
一、文件读取的绝对路径和相对路径
用相对路径和绝对路径读取上一层目录的文件、下一层目录的文件及读取同层级的文件。
# @File : platform.py.py
"""1、绝对路径读取文件"""
with open(r"C:\Users\chengjingd\PycharmProjects\pythonProject13\testa\platform\myprocessor\test2.txt", 'r') as f:
print(f.read())
"""2、相对路径读取文件"""
# 读取下一层目录的test2.txt文件
with open("myprocessor/test2.txt", 'r') as f:
print(f.read())
# 读取同层目录的test1.txt
with open("test1.txt", 'r') as f:
print(f.read())
# 读取上一层目录的test.txt文件
with open("../test.txt", 'r') as f:
print(f.read())
..表示进入上一层目录。
若在cite_f.py里读取 test.txt即上上层目录,只要将路径替换为"../../test2.txt"即可。
二、package的绝对路径及相对路径导入
绝对导入的格式为 import A.B 或 from A import B,相对导入格式为 from . import B 或 from ..A import B,.代表当前模块,..代表上层模块,...代表上上层模块,依次类推。
相对导入可以避免硬编码带来的维护问题,例如我们改了某一顶层包的名,那么其子包所有的导入就都不能用了。但是 存在相对导入语句的模块,不能直接运行,否则会有异常:
相对路径运行注意事项:
在没有明确指定包结构的情况下,Python 是根据
__name__来决定一个模块在包中的结构的,如果是__main__则它本身是顶层模块,没有包结构,如果是A.B.C 结构,那么顶层模块是 A。基本上遵循这样的原则:如果是绝对导入,一个模块只能导入自身的子模块或和它的顶层模块同级别的模块及其子模块
如果是相对导入,一个模块必须有包结构且只能导入它的顶层模块内部的模块

2.1 导包以绝对路径导入
# @File : platform1.py.py from testa.platform.myprocessor.myprocessor import * # 引用同级目录的模块 from a import * # 引用下一级目录的模块 from myprocessor.myprocessor import * # 引用上一级目录的模块 from testa.main import *
2.2 导包以相对路径导入
"""在myprocessor.py内导入同等级目录的cite_f""" # @File : myprocessor.py.py from .cite_f import f """在上一层目录里的platform1.py调用myprocessor.py""" # @File : platform1.py.py from myprocessor.myprocessor import *
"""在myprocessor.py内导入同等级目录的cite_f及上层目录的platform1.py""" # @File : myprocessor.py.py from .cite_f import f from ..platform1 import * """在上上一层目录里的main.py调用myprocessor.py""" # @File : main.py.py from testa.platform.myprocessor.myprocessor import *
参考引用:python的包相关的知识
模块:一组功能的组合,任何以.py结尾的都可以称作模块
包块的组合,py2要求必须有__init__.py,py3不需要
三、运行脚本的当前工作路径和绝对路径
脚本所在位置的目录为当前工作路径,无论后续调用哪个模块(子目录模块、父目录模块),当前工作路径不会变os.getcwd(),但在哪个模块写os.path.abspath(__file__)就会打印那个模块所在的工作目录。
# @File : myprocessor.py.py
import os
print("当前工作路径:",os.getcwd())
print("绝对路径:",os.path.abspath(__file__))
# @File : platform1.py.py
from myprocessor.myprocessor import *
运行脚本platform1.py会显示
当前工作路径: C:\Users\PycharmProjects\pythonProject13\testa\platform
绝对路径: C:\Users\PycharmProjects\pythonProject13\testa\platform\myprocessor\myprocessor.py
在脚本中运行示例

总结
到此这篇关于python文件读取和导包的绝对路径、相对路径的文章就介绍到这了,更多相关python文件读取和导包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3实现从文件中读取指定行的方法
本文实例讲述了Python3实现从文件中读取指定行的方法.分享给大家供大家参考.具体实现方法如下: # Python的标准库linecache模块非常适合这个任务 import linecache the_line = linecache.getline('d:/FreakOut.cpp', 222) print (the_line) # linecache读取并缓存文件中所有的文本, # 若文件很大,而只读一行,则效率低下. # 可显示使用循环, 注意enumerate从0开始计数,而line
-
使用Python读取二进制文件的实例讲解
目标:目标文件为一个float32型存储的二进制文件,按列优先方式存储.本文使用Python读取该二进制文件并使用matplotlib.pyplot相关工具画出图像 工具:Python3, matplotlib,os,struct,numpy 1. 读取二进制文件 首先使用open函数打开文件,打开模式选择二进制读取"rb". f = open(filename, "rb") 第二步,需要打开按照行列读取文件,由于是纯二进制文件,内部不含邮任何的数据结构信息,因此我
-
Python 读取某个目录下所有的文件实例
在处理数据的时候,因为没有及时的去重,所以需要重新对生成txt进行去重. 可是一个文件夹下有很多txt,总不可能一个一个去操作,这样效率太低了.这里我们需要用到 os 这个包 关键的代码 <span style="font-size:14px;"># coding=utf-8 #出现了中文乱码的问题,于是我无脑utf-8 .希望后期的学习可以能理解 import os import os.path import re import sys import codecs rel
-
Python按行读取文件的简单实现方法
1:readline() file = open("sample.txt") while 1: line = file.readline() if not line: break pass # do something file.close() 一行一行得从文件读数据,显然比较慢: 不过很省内存: 测试读10M的sample.txt文件,每秒大约读32000行: 2:fileinput import fileinput for line in fileinput.input("
-
python导包的几种方法(自定义包的生成以及导入详解)
python是一门灵活的语言,也可以说python是一门胶水语言,顾名思义,就是其可以导入各类的包,python的包可以说是所有语言中最多的.当然导入包大部分是为了更快捷,更方便,效率更高.对于刚入门的python爱好者来说最初接触的应该是import直接导入包的方式,例如 import time,就是导入了python的time包,这个包中的方法可以处理大部分我们项目中遇到的关于时间的问题. 下面我会详细介绍几种导入包的方式(在开发过程中绝对够用)以及怎样把其他文件夹中的python模块生成我
-
python进阶教程之文本文件的读取和写入
Python具有基本的文本文件读写功能.Python的标准库提供有更丰富的读写功能. 文本文件的读写主要通过open()所构建的文件对象来实现. 创建文件对象 我们打开一个文件,并使用一个对象来表示该文件: 复制代码 代码如下: f = open(文件名,模式) 最常用的模式有: 复制代码 代码如下: "r" # 只读 "w" # 写入 比如 复制代码 代码如下: >>>f = open("test.txt",&
-
Python读取一个目录下所有目录和文件的方法
本文实例讲述了Python读取一个目录下所有目录和文件的方法.分享给大家供大家参考,具体如下: 这里介绍的是刚学python时的一个读取目录的列子,给大家分享下: #!/usr/bin/python # -*- coding:utf8 -*- import os allFileNum = 0 def printPath(level, path): global allFileNum ''' 打印一个目录下的所有文件夹和文件 ''' # 所有文件夹,第一个字段是次目录的级别 dirList = [
-

python文件读取和导包的绝对路径、相对路径详解
目录 一.文件读取的绝对路径和相对路径 二.package的绝对路径及相对路径导入 2.1 导包以绝对路径导入 2.2 导包以相对路径导入 三.运行脚本的当前工作路径和绝对路径 总结 文件目录层级 一.文件读取的绝对路径和相对路径 用相对路径和绝对路径读取上一层目录的文件.下一层目录的文件及读取同层级的文件. # @File : platform.py.py """1.绝对路径读取文件""" with open(r"C:\Users\c
-
关于Python 中的时间处理包datetime和arrow的方法详解
在获取贝壳分的时候用到了时间处理函数,想要获取上个月时间包括年.月.日等 # 方法一: today = datetime.date.today() # 1. 获取「今天」 first = today.replace(day=1) # 2. 获取当前月的第一天 last_month = first - datetime.timedelta(days=1) # 3. 减一天,得到上个月的最后一天 print(last_month.strftime("%Y%m")) # 4. 格式化成指定形
-
浅谈python编译pyc工程--导包问题解决
利用python 编译工程,生产pyc文件 pyc文件好处:是一种二进制机器码,并且隐藏了源文件代码,但是有和py文件一样的功能(可以理解为效果一样) 所以可以将代码隐藏,便于商业价值,保护代码隐私还能和py文件一样可运行 import compileall compileall.compile_dir(r'/path') 所以在一些情况下,需将源文件工程批量生成pyc文件来隐藏代码. 上面代码即为 批量生成pyc的脚本更改path路径为根目录即可(根目录为最顶层目录需包括所有用到的文件) 运行
-
浅谈Python脚本开头及导包注释自动添加方法
1.开头:#!/usr/bin/python和# -*- coding: utf-8 -*-的作用 – 指定 #!/usr/bin/python 是用来说明脚本语言是python的 是要用/usr/bin下面的程序(工具)python,这个解释器,来解释python脚本,来运行python脚本的. #!/usr/bin/python:是告诉操作系统执行这个脚本的时候,调用 /usr/bin 下的 python 解释器: #!/usr/bin/env python(推荐):这种用法是为了防止操作系
-
python文件读取失败怎么处理
在读取文件时候比如读取 xxx.csv 时候 可能报编码错误 类似于 'xxx' codec can't decode byte 0xac in position 211: illegal multibyte sequen id_list = [] with open('E:/work_spider/xxx/xx.csv', "r", encoding="utf-8") as csvfile: csvReader = csv.reader(csvfile) for
-
python文件读取read及readlines两种方法使用详解
目录 引言 .read([size])方法 .readlines()方法 引言 with open() as 和open()都是打开,还没有读入文件 假设test.fa的内容如下图所示: ACGACGTAGCGTAGCTACGATCAGCGACGAGCTAGCGACGA .read([size])方法 read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它返回字符串对象. with open('test.fa') as fa: f = fa
-
python 中不同包 类 方法 之间的调用详解
目录结构如下: 在hello.py中导入ORM.py这个文件的时候,采用 import ORMPackage.ORM 或者 import ORM u = User(id = 123, name='codiy', email='codiy_huang@163.com', password='123456') 两种方式均报错 错误提示: name '***' is not defined 或者 No module named ORM 解决办法: 方法一 将包所在的目录添加到sys.path路径 im
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
-
Python中打包和解包(*和**)的使用详解
目录 一.打包参数 二.解包参数 三.几点注意 *和**在函数的定义和调用阶段,有着不同的功能,并且,*和**不能离开函数使用! 一.打包参数 * 的作用:在函数定义中,收集所有位置参数到一个新的元组,并将整个元组赋值给变量args >>> def f(*args): # * 在函数定义中使用 print(args) >>> f() () >>> f(1) (1,) >>> f(1, 2, 3, 4) (1, 2, 3, 4) 我们可