python神经网络pytorch中BN运算操作自实现
BN 想必大家都很熟悉,来自论文:
《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》
也是面试常考察的内容,虽然一行代码就能搞定,但是还是很有必要用代码自己实现一下,也可以加深一下对其内部机制的理解。
通用公式:
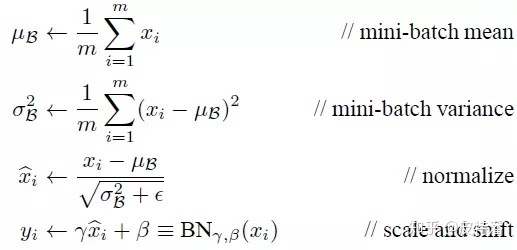
直奔代码:
首先是定义一个函数,实现BN的运算操作:
def batch_norm(is_training, x, gamma, beta, moving_mean, moving_var, eps=1e-5, momentum=0.9):
# 判断当前模式是训练模式还是预测模式
if not is_training:
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
x_hat = (x - moving_mean) / torch.sqrt(moving_var + eps)
else:
if len(x.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = x.mean(dim=0)
var = ((x - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
# x的形状以便后面可以做广播运算
mean = x.mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
var = ((x - mean) ** 2).mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
# 训练模式下用当前的均值和方差做标准化
x_hat = (x - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
x = gamma * x_hat + beta # 拉伸和偏移
return Y, moving_mean, moving_var
然后再定义一个类,就是常用的集成nn.Module的类了。
这里说明三点:
- 在卷积上的BN实现,是在 Batch,W,H上进行归一化操作的,也就是BWH拉成一个维度求均值和方差,均值和方差以及beta和gamma的尺寸为channel。当然其他各种N,包括IN,LN,GN都是包含WH维度的。
- 不需要计算梯度和参与梯度更新的参数,可以用self.register_buffer直接注册就可以了;注册的变量同样使用;
- 被包成nn.Parameter的参数,需要求梯度,但是不能加cuda(),否则会报错。 如果想在gpu上运算,可以将整个类的实例加.cuda()。例如 bn = BatchNorm(**param),bn=bn.cuda().
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super(BatchNorm, self).__init__()
if num_dims == 2: # 同样是判断是全连层还是卷积层
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成0和1
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 不参与求梯度和迭代的变量,全初始化成0
self.register_buffer('moving_mean', torch.zeros(shape))
self.register_buffer('moving_var', torch.ones(shape))
def forward(self, x):
# 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
if self.moving_mean.device != x.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var, Module实例的traning属性默认为true, 调用.eval()后设成false
y, self.moving_mean, self.moving_var = batch_norm(self.training,
x, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return x
以上就是python神经网络pytorch中BN运算操作自实现的详细内容,更多关于pytorch BN运算的资料请关注我们其它相关文章!
相关推荐
-
pytorch的batch normalize使用详解
torch.nn.BatchNorm1d() 1.BatchNorm1d(num_features, eps = 1e-05, momentum=0.1, affine=True) 对于2d或3d输入进行BN.在训练时,该层计算每次输入的均值和方差,并进行平行移动.移动平均默认的动量为0.1.在验证时,训练求得的均值/方差将用于标准化验证数据. num_features:表示输入的特征数.该期望输入的大小为'batch_size x num_features [x width]' Shape:
-

解决Pytorch中Batch Normalization layer踩过的坑
1. 注意momentum的定义 Pytorch中的BN层的动量平滑和常见的动量法计算方式是相反的,默认的momentum=0.1 BN层里的表达式为: 其中γ和β是可以学习的参数.在Pytorch中,BN层的类的参数有: CLASS torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 每个参数具体含义参见文档,需要注意的是,affine定义了BN层的
-
pytorch之添加BN的实现
pytorch之添加BN层 批标准化 模型训练并不容易,特别是一些非常复杂的模型,并不能非常好的训练得到收敛的结果,所以对数据增加一些预处理,同时使用批标准化能够得到非常好的收敛结果,这也是卷积网络能够训练到非常深的层的一个重要原因. 数据预处理 目前数据预处理最常见的方法就是中心化和标准化,中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征.标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准
-
TensorFlow实现Batch Normalization
一.BN(Batch Normalization)算法 1. 对数据进行归一化处理的重要性 神经网络学习过程的本质就是学习数据分布,在训练数据与测试数据分布不同情况下,模型的泛化能力就大大降低:另一方面,若训练过程中每批batch的数据分布也各不相同,那么网络每批迭代学习过程也会出现较大波动,使之更难趋于收敛,降低训练收敛速度.对于深层网络,网络前几层的微小变化都会被网络累积放大,则训练数据的分布变化问题会被放大,更加影响训练速度. 2. BN算法的强大之处 1)为了加速梯度下降算法的训练,我们
-
pytorch固定BN层参数的操作
背景: 基于PyTorch的模型,想固定主分支参数,只训练子分支,结果发现在不同epoch相同的测试数据经过主分支输出的结果不同. 原因: 未固定主分支BN层中的running_mean和running_var. 解决方法: 将需要固定的BN层状态设置为eval. 问题示例: 环境:torch:1.7.0 # -*- coding:utf-8 -*- import torch import torch.nn as nn import torch.nn.functional as F class
-
python神经网络pytorch中BN运算操作自实现
BN 想必大家都很熟悉,来自论文: <Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift> 也是面试常考察的内容,虽然一行代码就能搞定,但是还是很有必要用代码自己实现一下,也可以加深一下对其内部机制的理解. 通用公式: 直奔代码: 首先是定义一个函数,实现BN的运算操作: def batch_norm(is_training, x, gamma, beta, mo
-
python神经网络Pytorch中Tensorboard函数使用
目录 所需库的安装 常用函数功能 1.SummaryWriter() 2.writer.add_graph() 3.writer.add_scalar() 4.tensorboard --logdir= 示例代码 所需库的安装 很多人问Pytorch要怎么可视化,于是决定搞一篇. tensorboardX==2.0 tensorflow==1.13.2 由于tensorboard原本是在tensorflow里面用的,所以需要装一个tensorflow.会自带一个tensorboard. 也可以不
-
Python复数属性和方法运算操作示例
本文实例讲述了Python复数属性和方法运算操作.分享给大家供大家参考,具体如下: #coding=utf8 ''''' 复数是由一个实数和一个虚数组合构成,表示为:x+yj 一个负数时一对有序浮点数(x,y),其中x是实数部分,y是虚数部分. Python语言中有关负数的概念: 1.虚数不能单独存在,它们总是和一个值为0.0的实数部分一起构成一个复数 2.复数由实数部分和虚数部分构成 3.表示虚数的语法:real+imagej 4.实数部分和虚数部分都是浮点数 5.虚数部分必须有后缀j或J 复
-
基于python及pytorch中乘法的使用详解
numpy中的乘法 A = np.array([[1, 2, 3], [2, 3, 4]]) B = np.array([[1, 0, 1], [2, 1, -1]]) C = np.array([[1, 0], [0, 1], [-1, 0]]) A * B : # 对应位置相乘 np.array([[ 1, 0, 3], [ 4, 3, -4]]) A.dot(B) : # 矩阵乘法 ValueError: shapes (2,3) and (2,3) not aligned: 3 (dim
-
python神经网络学习利用PyTorch进行回归运算
目录 学习前言 PyTorch中的重要基础函数 1.class Net(torch.nn.Module)神经网络的构建: 2.optimizer优化器 3.loss损失函数定义 4.训练过程 全部代码 学习前言 我发现不仅有很多的Keras模型,还有很多的PyTorch模型,还是学学Pytorch吧,我也想了解以下tensor到底是个啥. PyTorch中的重要基础函数 1.class Net(torch.nn.Module)神经网络的构建: PyTorch中神经网络的构建和Tensorflow
-
浅谈pytorch中的BN层的注意事项
最近修改一个代码的时候,当使用网络进行推理的时候,发现每次更改测试集的batch size大小竟然会导致推理结果不同,甚至产生错误结果,后来发现在网络中定义了BN层,BN层在训练过程中,会将一个Batch的中的数据转变成正太分布,在推理过程中使用训练过程中的参数对数据进行处理,然而网络并不知道你是在训练还是测试阶段,因此,需要手动的加上,需要在测试和训练阶段使用如下函数. model.train() or model.eval() BN类的定义见pytorch中文参考文档 补充知识:关于pyto
-
详谈Python2.6和Python3.0中对除法操作的异同
Python中除法有两种运算符:'/'和'//':有三种类型的除法:传统除法.Floor除法和真除法. X / Y类型: 在Python2.6或者之前,这个操作对于整数运算会省去小数部分,而对于浮点数运算会保持小数部分:在Python3.0中变成真除法(无论任何类型都会保持小数部分,即使整除也会表示为浮点数形式). 示例代码: Python 2.7版本中结果: >>> 3/2 1 >>> 3/2.0 1.5 >>> 4/2 2 >>>
-
PyTorch中的拷贝与就地操作详解
前言 PyTroch中我们经常使用到Numpy进行数据的处理,然后再转为Tensor,但是关系到数据的更改时我们要注意方法是否是共享地址,这关系到整个网络的更新.本篇就In-palce操作,拷贝操作中的注意点进行总结. In-place操作 pytorch中原地操作的后缀为_,如.add_()或.scatter_(),就地操作是直接更改给定Tensor的内容而不进行复制的操作,即不会为变量分配新的内存.Python操作类似+=或*=也是就地操作.(我加了我自己~) 为什么in-place操作可以
-
Python实现的概率分布运算操作示例
本文实例讲述了Python实现的概率分布运算操作.分享给大家供大家参考,具体如下: 1. 二项分布(离散) import numpy as np from scipy import stats import matplotlib.pyplot as plt ''' # 二项分布 (binomial distribution) # 前提:独立重复试验.有放回.只有两个结果 # 二项分布指出,随机一次试验出现事件A的概率如果为p,那么在重复n次试验中出现k次事件A的概率为: # f(n,k,p) =