python实现K折交叉验证
本文实例为大家分享了python实现K折交叉验证的具体代码,供大家参考,具体内容如下
用KNN算法训练iris数据,并使用K折交叉验证方法找出最优的K值
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold # 主要用于K折交叉验证
# 导入iris数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
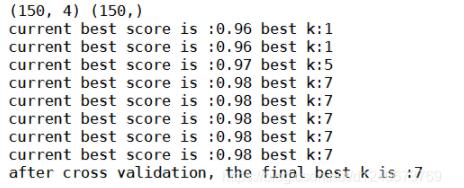
print(X.shape,y.shape)
# 定义想要搜索的K值,这里定义8个不同的值
ks = [1,3,5,7,9,11,13,15]
# 进行5折交叉验证,KFold返回的是每一折中训练数据和验证数据的index
# 假设数据样本为:[1,3,5,6,11,12,43,12,44,2],总共10个样本
# 则返回的kf的格式为(前面的是训练数据,后面的验证集):
# [0,1,3,5,6,7,8,9],[2,4]
# [0,1,2,4,6,7,8,9],[3,5]
# [1,2,3,4,5,6,7,8],[0,9]
# [0,1,2,3,4,5,7,9],[6,8]
# [0,2,3,4,5,6,8,9],[1,7]
kf = KFold(n_splits = 5, random_state=2001, shuffle=True)
# 保存当前最好的k值和对应的准确率
best_k = ks[0]
best_score = 0
# 循环每一个k值
for k in ks:
curr_score = 0
for train_index,valid_index in kf.split(X):
# 每一折的训练以及计算准确率
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(X[train_index],y[train_index])
curr_score = curr_score + clf.score(X[valid_index],y[valid_index])
# 求一下5折的平均准确率
avg_score = curr_score/5
if avg_score > best_score:
best_k = k
best_score = avg_score
print("current best score is :%.2f" % best_score,"best k:%d" %best_k)
print("after cross validation, the final best k is :%d" %best_k)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python实现K折交叉验证法的方法步骤
学习器在测试集上的误差我们通常称作"泛化误差".要想得到"泛化误差"首先得将数据集划分为训练集和测试集.那么怎么划分呢?常用的方法有两种,k折交叉验证法和自助法.介绍这两种方法的资料有很多.下面是k折交叉验证法的python实现. ##一个简单的2折交叉验证 from sklearn.model_selection import KFold import numpy as np X=np.array([[1,2],[3,4],[1,3],[3,5]]) Y=np.a
-

详解python实现交叉验证法与留出法
在机器学习中,我们经常在训练集上训练模型,在测试集上测试模型.最终的目标是希望我们的模型在测试集上有最好的表现. 但是,我们往往只有一个包含m个观测的数据集D,我们既要用它进行训练,又要对它进行测试.此时,我们就需要对数据集D进行划分. 对于数据集D的划分,我们尽量需要满足三个要求: 训练集样本量充足 训练模型时的计算量可以忍受 不同的划分方式会得出不同的训练集和测试集,从而得出不同的结果,我们需要消除这种影响 我们将分别介绍留出法.交叉验证法,以及各自的python实现.自助法(bootstr
-
Python sklearn KFold 生成交叉验证数据集的方法
源起: 1.我要做交叉验证,需要每个训练集和测试集都保持相同的样本分布比例,直接用sklearn提供的KFold并不能满足这个需求. 2.将生成的交叉验证数据集保存成CSV文件,而不是直接用sklearn训练分类模型. 3.在编码过程中有一的误区需要注意: 这个sklearn官方给出的文档 >>> import numpy as np >>> from sklearn.model_selection import KFold >>> X = [&quo
-
python实现K折交叉验证
本文实例为大家分享了python实现K折交叉验证的具体代码,供大家参考,具体内容如下 用KNN算法训练iris数据,并使用K折交叉验证方法找出最优的K值 import numpy as np from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import KFold # 主要用于K折交叉验证 # 导入iris数据集 iris =
-
pytorch K折交叉验证过程说明及实现方式
目录 K折交叉交叉验证的过程如下 交叉验证区分k折代码分析 总结 K折交叉交叉验证的过程如下 以200条数据,十折交叉验证为例子,十折也就是将数据分成10组,进行10组训练,每组用于测试的数据为:数据总条数/组数,即每组20条用于valid,180条用于train,每次valid的都是不同的. (1)将200条数据,分成按照 数据总条数/组数(折数),进行切分.然后取出第i份作为第i次的valid,剩下的作为train (2)将每组中的train数据利用DataLoader和Dataset,进行
-
R语言逻辑回归、ROC曲线与十折交叉验证详解
自己整理编写的逻辑回归模板,作为学习笔记记录分享.数据集用的是14个自变量Xi,一个因变量Y的australian数据集. 1. 测试集和训练集3.7分组 australian <- read.csv("australian.csv",as.is = T,sep=",",header=TRUE) #读取行数 N = length(australian$Y) #ind=1的是0.7概率出现的行,ind=2是0.3概率出现的行 ind=sample(2,N,rep
-
分享Python 中的 7 种交叉验证方法
目录 一.什么是交叉验证? 二.它是如何解决过拟合问题的? 1.HoldOut交叉验证 2.K折交叉验证 3.分层K折交叉验证 4.LeavePOut交叉验证 5.留一交叉验证 6.蒙特卡罗交叉验证(ShuffleSplit) 7.时间序列交叉验证 在任何有监督机器学习项目的模型构建阶段,我们训练模型的目的是从标记的示例中学习所有权重和偏差的最佳值. 如果我们使用相同的标记示例来测试我们的模型,那么这将是一个方法论错误,因为一个只会重复刚刚看到的样本标签的模型将获得完美的分数,但无法预测任何有用
-
python 留一交叉验证的实例
目录 python 留一交叉验证 基本原理 代码实现 留一法交叉验证 Leave-One-Out Cross Validation 我们用SKlearn库来实现一下LOO python 留一交叉验证 基本原理 K折交叉验证 简单来说,K折交叉验证就是: 把数据集划分成K份,取出其中一份作为测试集,另外的K - 1份作为训练集. 通过训练集得到回归方程,再把测试集带入该回归方程,得到预测值. 计算预测值与真实值的差值的平方,得到平方损失函数(或其他的损失函数). 重复以上过程,总共得到K个回归方程
-
sklearn中的交叉验证的实现(Cross-Validation)
sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好.今天主要记录一下sklearn中关于交叉验证的各种用法,主要是对sklearn官方文档 Cross-validation: evaluating estimator performance进行讲解,英文水平好的建议读官方文档,里面的知识点很详细. 先导入需要的库及数据集 In [1]: import numpy as np In [2]: from sklearn.model_selection impor
-
sklearn和keras的数据切分与交叉验证的实例详解
在训练深度学习模型的时候,通常将数据集切分为训练集和验证集.Keras提供了两种评估模型性能的方法: 使用自动切分的验证集 使用手动切分的验证集 一.自动切分 在Keras中,可以从数据集中切分出一部分作为验证集,并且在每次迭代(epoch)时在验证集中评估模型的性能. 具体地,调用model.fit()训练模型时,可通过validation_split参数来指定从数据集中切分出验证集的比例. # MLP with automatic validation set from keras.mode
-
R语言交叉验证的实现代码
k-折交叉验证 k-折交叉验证(K-fold cross-validation)是交叉验证方法里一种.它是指将样本集分为k份,其中k-1份作为训练数据集,而另外的1份作为验证数据集.用验证集来验证所得分类器或者模型的错误率.一般需要循环k次,直到所有k份数据全部被选择一遍为止. 有关交叉验证的介绍可参考作者另一博文: http://blog.csdn.net/yawei_liu1688/article/details/79138202 R语言实现 K折交叉验证,随机分组 数据打折-数据分组自编译