Python爬虫入门案例之回车桌面壁纸网美女图片采集
目录
- 知识点
- 环境
- 目标网址:
- 爬虫代码
- 导入模块
- 发送网络请求
- 获取网页源代码
- 提取每个相册的详情页链接地址
- 替换所有的图片链接 换成大图
- 保存图片 图片名字
- 翻页
- 爬取结果
知识点
- requests
- parsel
- re
- os
环境
- python3.8
- pycharm2021
目标网址:
https://mm.enterdesk.com/bizhi/63899-347866.html

【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
注意: 在我们查看网页源代码的时候 (1. 控制台为准 2. 以右键查看网页源代码 3. 元素面板)
- 发送网络请求
- 获取网页源代码
- 提取想要的图片链接 css样式提取 xpath re正则表达式 bs4
- 替换所有的图片链接 换成大图
- 保存图片
爬虫代码
导入模块
import requests # 第三方库 pip install requests import parsel # 第三方库 pip install parsel import os # 新建文件夹
发送网络请求
response = requests.get('https://mm.enterdesk.com/bizhi/64011-348522.html')
获取网页源代码
data_html = response_1.text
提取每个相册的详情页链接地址
selector_1 = parsel.Selector(data_html)
photo_url_list = selector_1.css('.egeli_pic_dl dd a::attr(href)').getall()
title_list = selector_1.css('.egeli_pic_dl dd a img::attr(title)').getall()
for photo_url, title in zip(photo_url_list, title_list):
print(f'*****************正在爬取{title}*****************')
response = requests.get(photo_url)
# <Response [200]>: 请求成功的标识
selector = parsel.Selector(response.text)
# 提取想要的图片链接[第一个链接, 第二个链接,....]
img_src_list = selector.css('.swiper-wrapper a img::attr(src)').getall()
# 新建一个文件夹
if not os.path.exists('img/' + title):
os.mkdir('img/' + title)
替换所有的图片链接 换成大图
for img_src in img_src_list:
# 字符串的替换
img_url = img_src.replace('_360_360', '_source')
保存图片 图片名字
# 图片 音频 视频 二进制数据content
img_data = requests.get(img_url).content
# 图片名称 字符串分割
# 分割完之后 会给我们返回一个列表
img_title = img_url.split('/')[-1]
with open(f'img/{title}/{img_title}', mode='wb') as f:
f.write(img_data)
print(img_title, '保存成功!!!')
翻页
page_html = requests.get('https://mm.enterdesk.com/').text
counts = parsel.Selector(page_html).css('.wrap.no_a::attr(href)').get().split('/')[-1].split('.')[0]
for page in range(1, int(counts) + 1):
print(f'------------------------------------正在爬取第{page}页------------------------------------')
发送网络请求
response_1 = requests.get(f'https://mm.enterdesk.com/{page}.html')
爬取结果

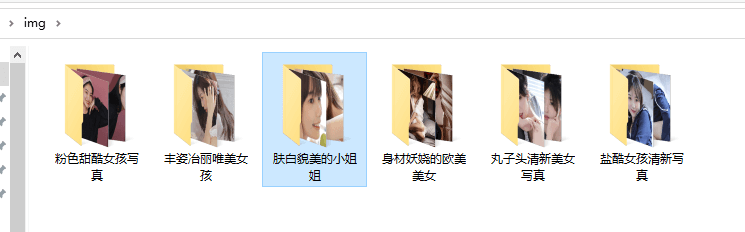

到此这篇关于Python爬虫入门案例之回车桌面壁纸网美女图片采集的文章就介绍到这了,更多相关Python 图片采集内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫入门案例之爬取二手房源数据
本文重点 系统分析网页性质 结构化的数据解析 csv数据保存 环境介绍 python 3.8 pycharm 专业版 >>> 激活码 #模块使用 requests >>> pip install requests parsel >>> pip install parsel csv [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 爬虫代码实现步骤: 发送请求 >>> 获取数据 &g
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
Python爬虫实战之批量下载快手平台视频数据
知识点 requests json re pprint 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 案例实现步骤: 一. 数据来源分析 (只有当你找到数据来源的时候, 才能通过代码实现) 1.确定需求 (要爬取的内容是什么?) 爬取某个关键词对应的视频 保存mp4 2.通过开发者工具进行抓包分析 分析数据从哪里来的(找出真正的数据来源)? 静态加载页面 笔趣阁为例 动态加载页面 开发者工具抓数据包 [付费VIP完整版]只要看了就能学会的教程,
-
Python爬虫入门案例之爬取去哪儿旅游景点攻略以及可视化分析
目录 知识点 第三方库 开发环境: 爬虫程序 导入模块 发送请求 获取数据(网页源代码) 解析网页(re正则表达式,css选择器,xpath,bs4/六年没更新了,json) 向详情页网站发送请求(get,post) 解析网页 保存数据 数据可视化 导入模块 导入数据 旅游胜地Top10及对应费用 出游方式分析 出游时间分析 出游玩法分析 知识点 requests 发送网络请求 parsel 解析数据 csv 保存数据 第三方库 requests >>> pip install requ
-
详解Python 爬取13个旅游城市,告诉你五一大家最爱去哪玩?
今年五一放了四天假,很多人不再只是选择周边游,因为时间充裕,选择了稍微远一点的景区,甚至出国游.各个景点成了人山人海,拥挤的人群,甚至去卫生间都要排队半天,那一刻我突然有点理解灭霸的行为了. 今天通过分析去哪儿网部分城市门票售卖情况,简单的分析一下哪些景点比较受欢迎,等下次假期可以做个参考. 抓取数据 通过请求https://piao.qunar.com/ticket/list.htm?keyword=北京,获取北京地区热门景区信息,再通过BeautifulSoup去分析提取出我们需要的信息.
-
Python爬虫入门案例之回车桌面壁纸网美女图片采集
目录 知识点 环境 目标网址: 爬虫代码 导入模块 发送网络请求 获取网页源代码 提取每个相册的详情页链接地址 替换所有的图片链接 换成大图 保存图片 图片名字 翻页 爬取结果 知识点 requests parsel re os 环境 python3.8 pycharm2021 目标网址: https://mm.enterdesk.com/bizhi/63899-347866.html [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 注意:
-
趣味Python实战练习之自动更换桌面壁纸脚本附源码
目录 前言 目标地址 先是爬虫代码 导入数据 请求数据 解析数据 保存数据 运行代码,查看结果 自动跟换桌面壁纸代码 最后实现效果 前言 发现一个不错的壁纸网站,里面都是超高清的图片,而且还是免费为的. 所以,我打算把这些壁纸都爬取下来,然后在做一个自动跟换桌面壁纸的脚本,这样基本上你一年都可以每天都有不重复桌面了 目标地址 先来看看我们这次的受害者:https://wallhaven.cc/ [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看
-
python爬虫入门教程--优雅的HTTP库requests(二)
前言 urllib.urllib2.urllib3.httplib.httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反人类,更糟糕的是这些模块在 Python2 与 Python3 中有很大的差异,如果业务代码要同时兼容 2 和 3,写起来会让人崩溃. 好在,还有一个非常惊艳的 HTTP 库叫 requests,它是 GitHUb 关注数最多的 Python 项目之一,requests 的作者是 Kenneth Reitz 大神. requests 实现了 HTTP
-
Python爬虫实现使用beautifulSoup4爬取名言网功能案例
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能.分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,作者,标签) #! /usr/bin/python3 # -*- coding:utf-8 -*- from urllib.request import urlopen as open from bs4 import BeautifulSoup import re import pymysql def find_
-
Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. 比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据.这样,整个连在一起的大网对这之蜘蛛来说触手可及,分分钟爬下来不是事儿. 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.bai
-
10个python爬虫入门实例(小结)
昨天带伙伴萌学习python爬虫,准备了几个简单的入门实例 涉及主要知识点: web是如何交互的 requests库的get.post函数的应用 response对象的相关函数,属性 python文件的打开,保存 代码中给出了注释,并且可以直接运行哦 如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境) windows用户,Linux用户几乎一样: 打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
10个python爬虫入门基础代码实例 + 1个简单的python爬虫完整实例
本文主要涉及python爬虫知识点: web是如何交互的 requests库的get.post函数的应用 response对象的相关函数,属性 python文件的打开,保存 代码中给出了注释,并且可以直接运行哦 如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境) windows用户,Linux用户几乎一样: 打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式运行cmd窗口 pip install