Python安装spark的详细过程
目录
- 一.配置版本
- 二.配置环境
- 1.配置JDK
- 2.配置Spark
- 3.配置Hadoop
- 三.Pycharm配置spark
- 四.使用anconda中python环境配置spark
- 1.创建虚拟环境
- 2.安装pyspark
- 3.环境配置
- 4.运行
一.配置版本
Java JDK 1.8.0_111
Python 3.9.6
Spark 3.1.2
Hadoop 3.2.2
二.配置环境
1.配置JDK
从官网下载相应JDK的版本安装,并进行环境变量的配置
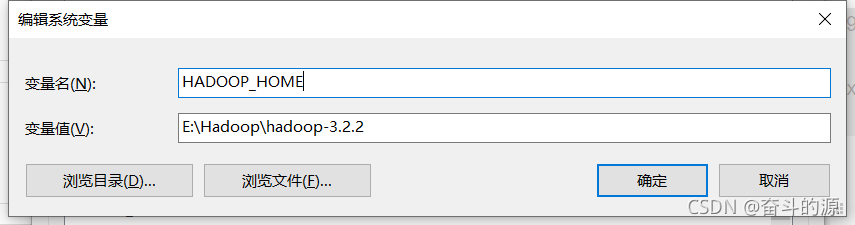
(1)在系统变量新建JAVA_HOME,根据你安装的位置填写变量值
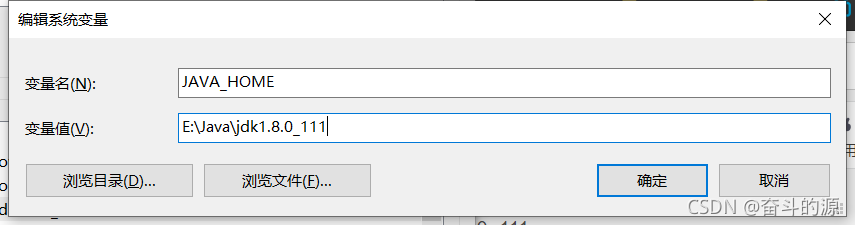
(2)新建CLASSPATH
变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(注意前面所需的符号)
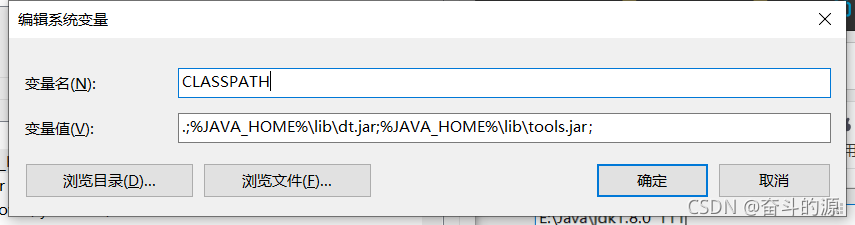
(3)点击Path
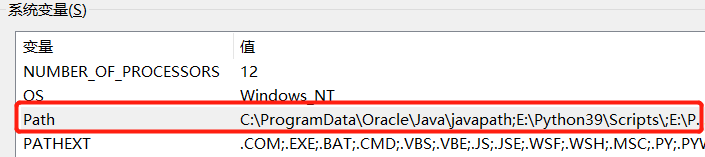
在其中进行新建:%JAVA_HOME%\bin
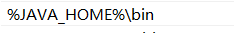
(4)配置好后进行确定
(5)验证,打开cmd,输入java -version和javac进行验证


此上说明jdk环境变量配置成功
2.配置Spark
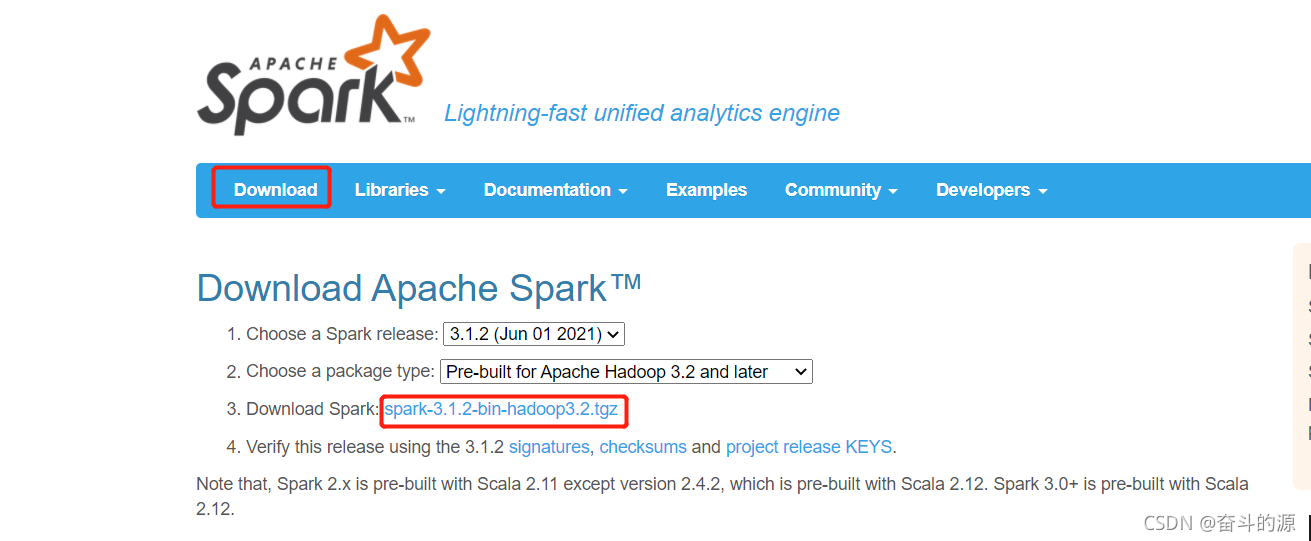
(1)下载安装:
Spark官网:spark-3.1.2-bin-hadoop3.2下载地址
(2)解压,配置环境
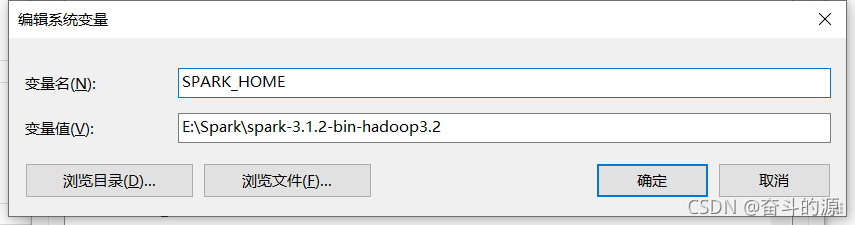
(3)点击Path,进行新建:%SPARK_HOME%\bin,并确认
(4)验证,cmd中输入pyspark
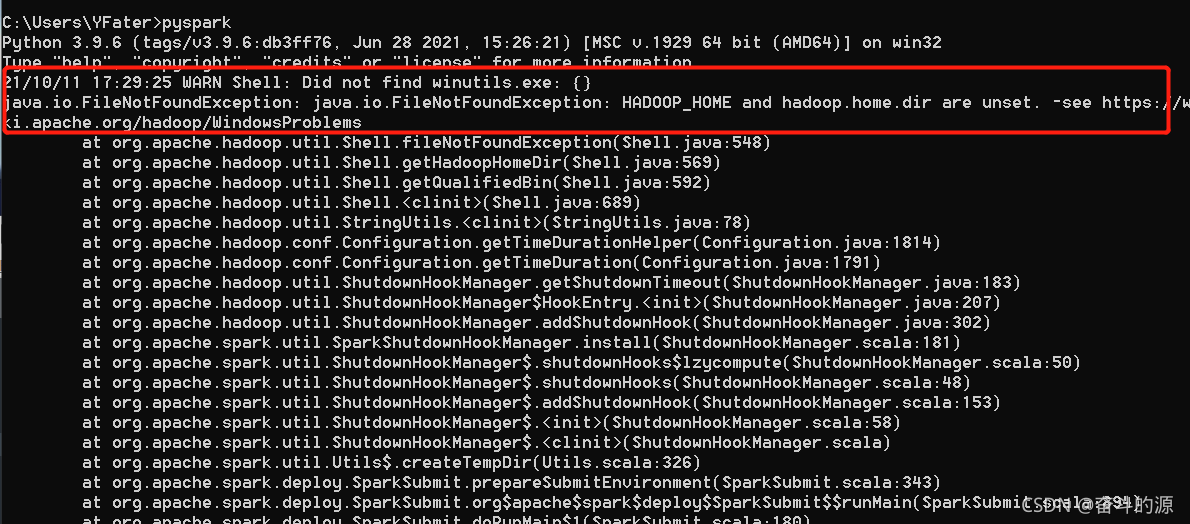
这里提醒我们要安装Hadoop
3.配置Hadoop
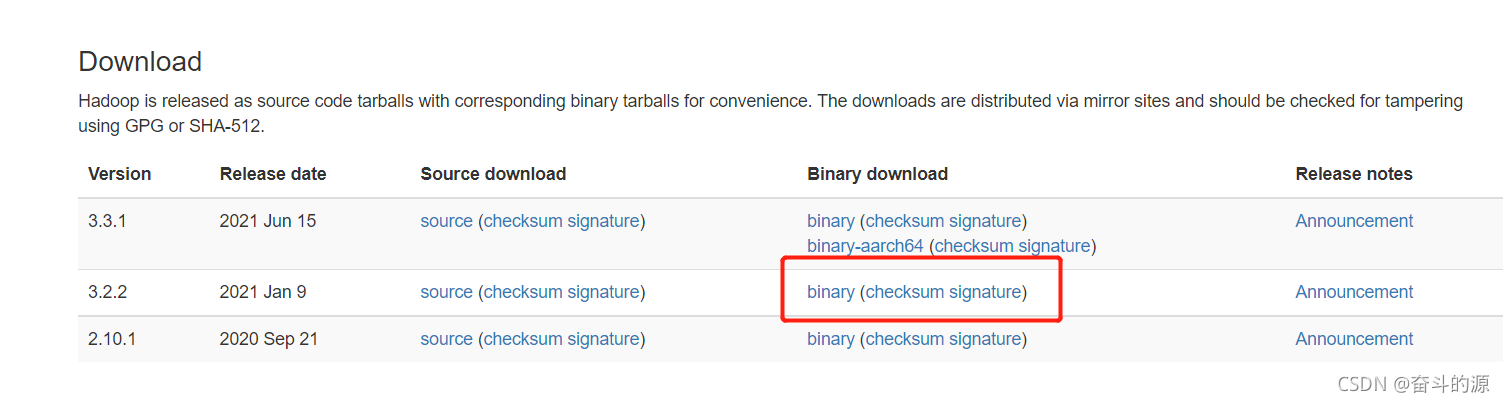
(1)下载:
Hadoop官网:Hadoop 3.2.2下载地址
(2)解压,配置环境
注意:解压文件后,bin文件夹中可能没有以下两个文件:

下载地址:https://github.com/cdarlint/winutils
配置环境变量CLASSPATH:%HADOOP_HOME%\bin\winutils.exe
(3)点击Path,进行新建:%HADOOP_HOME%\bin,并确认
(4)验证,cmd中输入pyspark
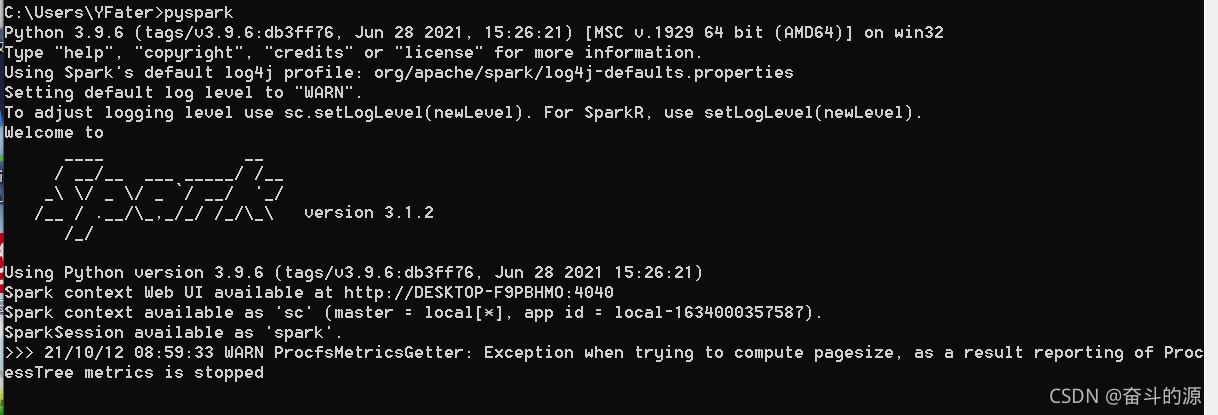
由上可以看出spark能运行成功,但是会出现如下警告:
WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped
这里因为spark为3.x版本有相关改动,使用spar2.4.6版本不会出现这样的问题。
不改版本解决方式(因是警告,未尝试):
方式一:解决方法一
方式二:解决方法二
三.Pycharm配置spark
(1)Run–>Edit Configurations
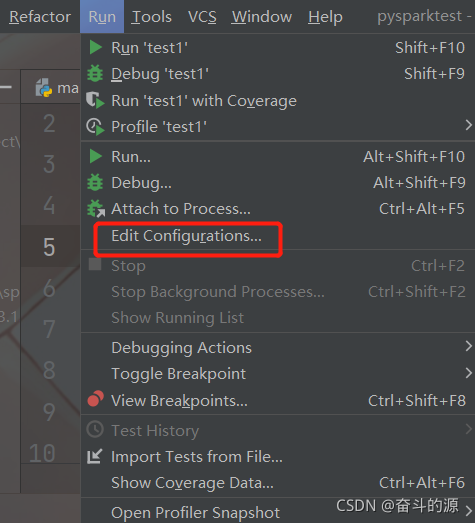
(2)对Environment Variables进行配置

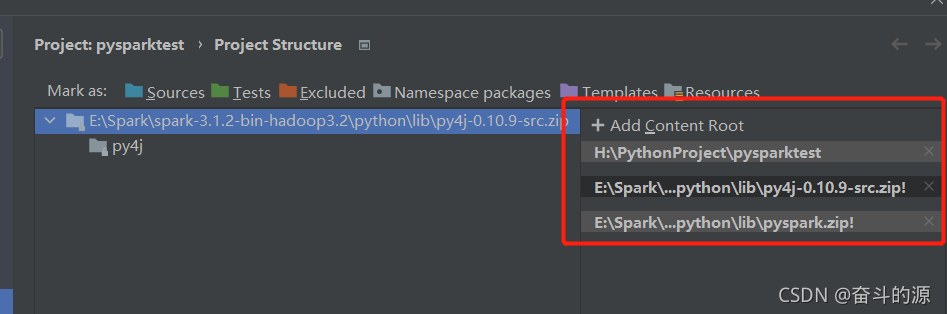
(3)File–>Settings–>Project Structure–>Add Content Root
找到spark-3.1.2-bin-hadoop3.2\python\lib下两个包进行添加
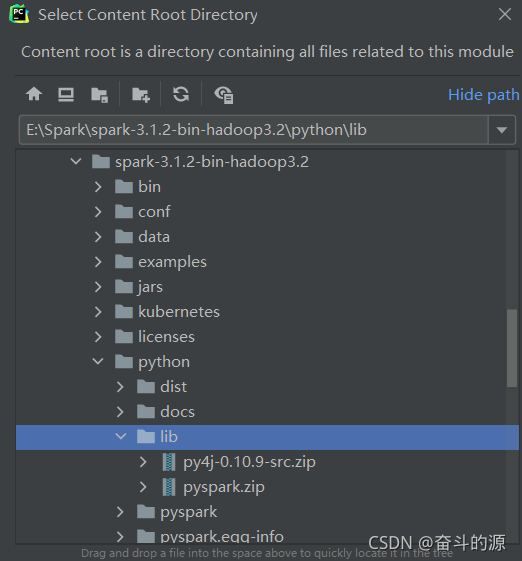
选择结果:
(4)测试
# 添加此代码,进行spark初始化
import findspark
findspark.init()
from datetime import datetime, date
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
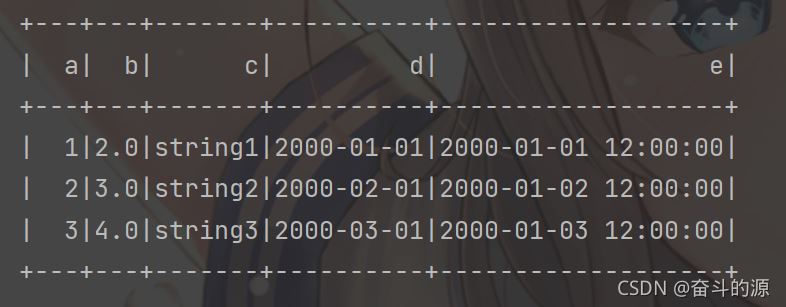
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
df.show()
运行结果:
四.使用anconda中python环境配置spark
1.创建虚拟环境
conda create -n pyspark_env python==3.9.6
查看环境:
conda env list
运行结果:

2.安装pyspark
切换到pyspark_env并进行安装pyspark
pip install pyspark

3.环境配置
运行上面的实例,会出现以下错误:

这说明我们需要配置py4j,SPARK_HOME
SPARK_HOME:

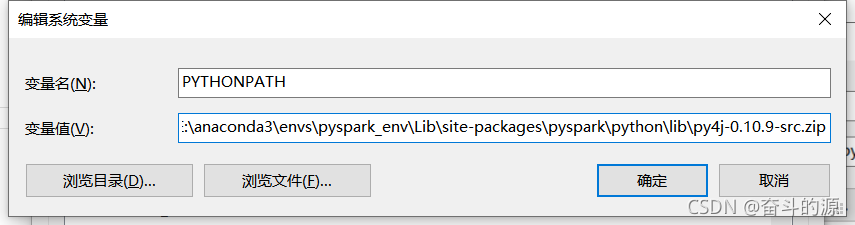
PYTHONPATH设置:
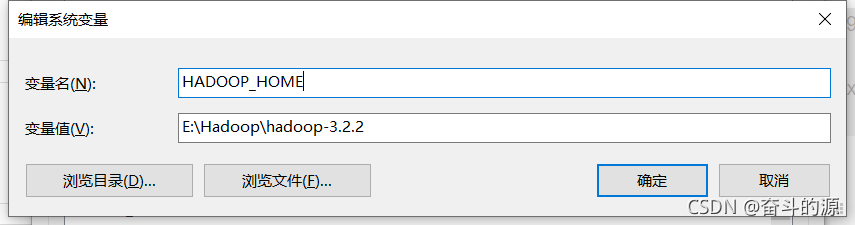
HADOOP_HOME设置:
path中设置:

4.运行

# 添加此代码,进行spark初始化
import findspark
findspark.init()
from datetime import datetime, date
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
df.show()
运行结果同上
到此这篇关于Python安装spark的文章就介绍到这了,更多相关Python安装spark内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何将PySpark导入Python的放实现(2种)
方法一 使用findspark 使用pip安装findspark: pip install findspark 在py文件中引入findspark: >>> import findspark >>> findspark.init() 导入你要使用的pyspark库 >>> from pyspark import * 优点:简单快捷 缺点:治标不治本,每次写一个新的Application都要加载一遍findspark 方法二 把预编译包中的Python库
-

Python搭建Spark分布式集群环境
前言 Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象.Spark 最大的特点就是快,可比 Hadoop MapReduce 的处理速度快 100 倍.本文没有使用一台电脑上构建多个虚拟机的方法来模拟集群,而是使用三台电脑来搭建一个小型分布式集群环境安装. 本教程采用Spark2.0以上版本(比如Spark2.0.2.Spark2.1.0等)搭建集群,同样适用于搭建Spark1.6.2集群. 安装Hadoop并搭建好Hadoop集群环境 Spark分布式集群的安装
-
Python安装spark的详细过程
目录 一.配置版本 二.配置环境 1.配置JDK 2.配置Spark 3.配置Hadoop 三.Pycharm配置spark 四.使用anconda中python环境配置spark 1.创建虚拟环境 2.安装pyspark 3.环境配置 4.运行 一.配置版本 Java JDK 1.8.0_111 Python 3.9.6 Spark 3.1.2 Hadoop 3.2.2 二.配置环境 1.配置JDK 从官网下载相应JDK的版本安装,并进行环境变量的配置 (1)在系统变量新建JAVA_HOME,
-
Python中用Spark模块的使用教程
在日常的编程中,我经常需要标识存在于文本文档中的部件和结构,这些文档包括:日志文件.配置文件.定界的数据以及格式更自由的(但还是半结构化的)报表格式.所有这些文档都拥有它们自己的"小语言",用于规定什么能够出现在文档内.我编写这些非正式解析任务的程序的方法总是有点象大杂烩,其中包括定制状态机.正则表达式以及上下文驱动的字符串测试.这些程序中的模式大概总是这样:"读一些文本,弄清是否可以用它来做些什么,然后可能再多读一些文本,一直尝试下去." 解析器将文档中部件和结构
-
Linux下搭建Spark 的 Python 编程环境的方法
Spark编程环境 Spark 可以独立安装使用,也可以和Hadoop 一起安装使用.在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本. Spark 安装 访问 Spark 下载页面 ,并选择最新版本的 Spark 直接下载,当前的最新版本是 2.4.2 .下载好之后需要解压缩到安装文件夹中,看自己的喜好,我们是安装到了 /opt 目录下. tar -xzf spark-2.4.2-bin-hadoop2.7.tgz mv spark-2.4.2-bin-ha
-
在python中使用pyspark读写Hive数据操作
1.读Hive表数据 pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下: from pyspark.sql import HiveContext,SparkSession _SPARK_HOST = "spark://spark-master:7077" _APP_NAME = "test" spa
-
Python如何把Spark数据写入ElasticSearch
这里以将Apache的日志写入到ElasticSearch为例,来演示一下如何使用Python将Spark数据导入到ES中. 实际工作中,由于数据与使用框架或技术的复杂性,数据的写入变得比较复杂,在这里我们简单演示一下. 如果使用Scala或Java的话,Spark提供自带了支持写入ES的支持库,但Python不支持.所以首先你需要去这里下载依赖的ES官方开发的依赖包包. 下载完成后,放在本地目录,以下面命令方式启动pyspark: pyspark --jars elasticsearch-ha
-
Python安装selenium包详细过程
Python安装selenium包 打开命令行窗口,进入python交互环境 python 尝试导入selenium包,报错,说明尚未安装selenium import selenium 退出python交互环境 exit() 使用pip安装selenium包 pip install selenium 下载对应版本的webdirver,这里用的是某歌的,因为本机安装的某歌浏览器,网页有对应版本说明及下载地址,这里不写了,注意的是下载的dirver一定要在环境变量里path配有的路径,这里放在了p
-
在vmware虚拟机安装dpdk的详细过程
1. 打开vmware,选择centos7.6镜像,开始安装操作系统 2. 安装完毕后,关机,点击“编辑虚拟机设置”按钮,点击“处理器”,在右侧勾选第三个“虚拟化IOMMU”.由于我的宿主机是win11,已经支持了Intel VT-x,所以第一个选项就不必勾选了,win7和win10可能需要勾选. 另外,我多添加了几个网络适配器,便于测试. 注意,如果勾选了第一个选项: 启动虚拟机时报错:. 则需要取消勾选第一个. 3. 编辑本虚拟机配置文件CentOS 7 64 位.vmx(使用记事本打开),
-
在麒麟V10服务器上编译安装Storm的详细过程
1 简介 Apache Storm是一个免费开源.分布式.高容错的实时计算系统,可以用来处理大量的数据,类似于Hadoop.Apache Storm是用Java和Clojure写的. 2 准备工作 源码下载地址: https://github.com/apache/storm 这里下载了1.1.0版本进行验证: 1.1.0 https://archive.apache.org/dist/storm/apache-storm-1.1.0/apache-storm-1.1.0.tar.gz 验证环境
-
使用vmware测试PXE批量安装服务器的详细过程
目录 一.准备阶段 1.准备环境 2.安装方式 3.网卡配置 二.安装阶段 1.安装httpd 2.安装tftp-server 3.复制pxe文件 4.安装dhcp服务 三.安装kickstart自动安装工具 四.在客户主机上测试 五.相关服务 一.准备阶段 1.准备环境 Vmware workstation Centos7一台做pxe-server 地址:192.168.138.5 子网掩码:255.255.255.0 网关:192.168.138.2 关闭selinux和防火墙 2.安装方式
-
亲手教你Docker Compose安装DOClever的详细过程
目录 一.Docker Compose是什么以及Docker Compose安装和使用 二.DOClever是什么 三.使用Docker Compose安装DOClever步骤 一.Docker Compose是什么以及Docker Compose安装和使用 点击查看我的另外一篇:<Docker Compose的安装和使用> 二.DOClever是什么 DOClever是一个可视化免费开源的接口管理工具 ,可以分析接口结构,校验接口正确性, 围绕接口定义文档,通过一系列自动化工具提升我们的协作
-
win10环境安装kettle与linux环境安装kettle的详细过程
目录 前言 一.Kettle下载 : 1.kettle源代码下载地址 : 2.官网下载 3.JDK安装 二.win10环境安装kettle 1.解压kettle 2.双击spoon启动 3.启动界面如下: 三.linux环境安装kettle 1.上传kettle压缩包到linux 2.解压安装包 3.linux下启动kettle 总结 前言 kettle是一款免费开源的.可视化的.国际上比较流行的.功能强大的ETL必备工具,在ETL这一方面做的还不错,下面介绍一下基于win10操作系统安装ket
-
Centos8安装mysql8的详细过程(免安装版/或者二进制包方式安装)
目录 二进制包方式安装 一.首先检查服务器上是否安装有mysql: 二.开始安装配置mysql 在Navicat上测试连接 二进制包方式安装 一.首先检查服务器上是否安装有mysql: 第一步:查看mysql安装版本rpm -qa|grep -i mysql 第二步:卸载Mysqlrpm -ev --nodeps [上一步查询到的mysql版本名称] 最后删除关于mysql相关的文件夹:查找根目录下所有者是mysql和有mysql名称的文件find / -user mysqlfind / -na
-
Centos7安装JDK1.8详细过程实战记录
目录 前言 一.OpenJDK1.8 详细步骤 1.检查当前机器是否有自带的JDK 2.如果没有 则跳至安装步骤,有的话 进行卸载 3.更新yum源 4.搜索yum中的软件包 5.安装OpenJDK 6.验证是否安装成功 7.其它常见问题: 二.OracleJDK1.8 详细步骤 1.查看java版本: 2.查看java相关: 3.删除openjdk—xxxx: 4.检查java版本: 5.下载jdk安装包: 6.切换到目录下解压 7.配置JDK 8.让环境变量生效: 9.检查是否配置成功 总结
-
Python安装Graphviz 超详细图文教程
目录 Python 安装Graphviz 详细教程 Python安装Graphviz画图器 1.下载 2 .下载好了以后开始安装 3.安装成功以后可以检查一下是否安装成功 4.安装graphviz包 5.测试 Python 安装Graphviz 详细教程 Python安装Graphviz画图器 首先,要明确他是一个独立的软件,如果大家用pip的方法装了graphviz可以先卸载 pip uninstall graphviz 1.下载 https://graphviz.org/download/