Python3 filecmp模块测试比较文件原理解析
1.filecmp比较文件
filecmp模块提供了一些函数和一个类来比较文件系统上的文件和目录。
1.1 示例数据
使用下面代码创建一组测试文件。
import os
def mkfile(filename, body=None):
with open(filename, 'w') as f:
f.write(body or filename)
return
def make_example_dir(top):
if not os.path.exists(top):
os.mkdir(top)
curdir = os.getcwd()
os.chdir(top)
os.mkdir('dir1')
os.mkdir('dir2')
mkfile('dir1/file_only_in_dir1')
mkfile('dir2/file_only_in_dir2')
os.mkdir('dir1/dir_only_in_dir1')
os.mkdir('dir2/dir_only_in_dir2')
os.mkdir('dir1/common_dir')
os.mkdir('dir2/common_dir')
mkfile('dir1/common_file', 'this file is the same')
os.link('dir1/common_file', 'dir2/common_file')
mkfile('dir1/contents_differ')
mkfile('dir2/contents_differ')
# Update the access and modification times so most of the stat
# results will match.
st = os.stat('dir1/contents_differ')
os.utime('dir2/contents_differ', (st.st_atime, st.st_mtime))
mkfile('dir1/file_in_dir1', 'This is a file in dir1')
os.mkdir('dir2/file_in_dir1')
os.chdir(curdir)
return
if __name__ == '__main__':
os.chdir(os.path.dirname(__file__) or os.getcwd())
make_example_dir('example')
make_example_dir('example/dir1/common_dir')
make_example_dir('example/dir2/common_dir')
运行这个脚本会在axample目录下生成一个文件树。
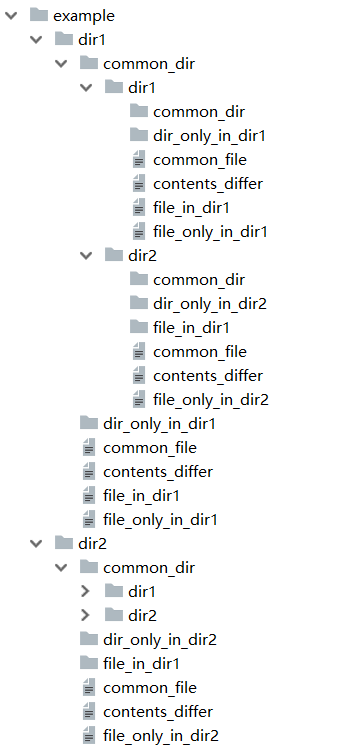
common_dir目录下也有同样的目录结构,以提供有意思的递归比较选择。
1.2 比较文件
cmp()用于比较文件系统上的两个文件。
import filecmp
print('common_file :', end=' ')
print(filecmp.cmp('example/dir1/common_file',
'example/dir2/common_file',
shallow=True),
end=' ')
print(filecmp.cmp('example/dir1/common_file',
'example/dir2/common_file',
shallow=False))
print('contents_differ:', end=' ')
print(filecmp.cmp('example/dir1/contents_differ',
'example/dir2/contents_differ',
shallow=True),
end=' ')
print(filecmp.cmp('example/dir1/contents_differ',
'example/dir2/contents_differ',
shallow=False))
print('identical :', end=' ')
print(filecmp.cmp('example/dir1/file_only_in_dir1',
'example/dir1/file_only_in_dir1',
shallow=True),
end=' ')
print(filecmp.cmp('example/dir1/file_only_in_dir1',
'example/dir1/file_only_in_dir1',
shallow=False))
shallo参数告诉cmp()除了文件的元数据外,是否还要查看文件的内容。默认情况下,会使用由os.stat()得到的信息来完成一个浅比较。如果结果是一样的,则认为文件相同。因此,对于同时创建的相同大小的文件,即使他们的内容不同,也会报告为是相同的文件。当shallow为False时,则要比较文件的内容。

如果非递归的比较两个目录中的一组文件,则可以使用cmpfiles()。参数是目录名和两个位置上要检查的我就爱你列表。传入的公共文件列表应当只包含文件名(目录会导致匹配不成功),而且这些文件在两个位置上都应当出现。下一个例子显示了构造公共列表的一种简单方法。与cmp()一样,这个比较也有一个shallow标志。
import filecmp
import os
# Determine the items that exist in both directories
d1_contents = set(os.listdir('example/dir1'))
d2_contents = set(os.listdir('example/dir2'))
common = list(d1_contents & d2_contents)
common_files = [
f
for f in common
if os.path.isfile(os.path.join('example/dir1', f))
]
print('Common files:', common_files)
# Compare the directories
match, mismatch, errors = filecmp.cmpfiles(
'example/dir1',
'example/dir2',
common_files,
)
print('Match :', match)
print('Mismatch :', mismatch)
print('Errors :', errors)
cmpfiles()返回3个文件名列表,分别包含匹配的文件、不匹配的文件和不能比较的文件(由于权限问题或出于其他原因)。

1.3 比较目录
前面介绍的函数适合完成相对简单的比较。对于大目录树的递归比较或者更完整的分析,dircmp类很更有用。在最简单的用例中,report()会打印比较两个目录的报告。
import filecmp
dc = filecmp.dircmp('example/dir1', 'example/dir2')
dc.report()
输出是一个纯文本报告,显示的结果只包括给定目录的内容,而不会递归比较其子目录。在这里,认为文件not_the_same是相同的,因为这里没有比较内容。无法让dircmp像cmp()那样比较文件的内容。

为了更多的细节,也为了完成一个递归比较,可以使用report_full_closure()。
import filecmp
dc = filecmp.dircmp('example/dir1', 'example/dir2')
dc.report_full_closure()
输出将包括所有同级子目录的比较。

1.4 在程序中使用差异
除了生成打印报告,dircmp还能计算文件列表,可以在程序中直接使用。以下各个属性只在请求时才计算,所以对于未用的数据,创建dircmp实例不会带来开销。
import filecmp
import pprint
dc = filecmp.dircmp('example/dir1', 'example/dir2')
print('Left:')
pprint.pprint(dc.left_list)
print('\nRight:')
pprint.pprint(dc.right_list)
所比较目录中包含的文件和子目录分别列在left_list和right_list中。

可以向构造函数传入一个要忽略的名字列表(该列表中指定的名字将被忽略)来对输入进行过滤。默认的,RCS、CVS和tags等名字会被忽略。
import filecmp
import pprint
dc = filecmp.dircmp('example/dir1', 'example/dir2',
ignore=['common_file'])
print('Left:')
pprint.pprint(dc.left_list)
print('\nRight:')
pprint.pprint(dc.right_list)
在这里,将common_file从要比较的文件列表中去除。

两个输入目录中共有的文件名会保存在common内,各目录独有的文件会列在left_only和right_only中。
import filecmp
import pprint
dc = filecmp.dircmp('example/dir1', 'example/dir2')
print('Common:')
pprint.pprint(dc.common)
print('\nLeft:')
pprint.pprint(dc.left_only)
print('\nRight:')
pprint.pprint(dc.right_only)
"左"目录是dircmp()的第一个参数,"右"目录是第二个参数。

公共成员可以被进一步分解为文件、目录和“有趣”元素(两个目录中类型不同的内容,或者os.stat()指出的有错误的地方)。
import filecmp
import pprint
dc = filecmp.dircmp('example/dir1', 'example/dir2')
print('Common:')
pprint.pprint(dc.common)
print('\nDirectories:')
pprint.pprint(dc.common_dirs)
print('\nFiles:')
pprint.pprint(dc.common_files)
print('\nFunny:')
pprint.pprint(dc.common_funny)
在示例数据中,file_in_dir1元素在一个目录中是一个文件,而在另一个目录中是一个子目录,所以它会出现在“有趣”列表中。

文件之间的差别也可以做类似的划分。
import filecmp
dc = filecmp.dircmp('example/dir1', 'example/dir2')
print('Same :', dc.same_files)
print('Different :', dc.diff_files)
print('Funny :', dc.funny_files)
文件not_the_same通过os.stat()比较,并且不检查内容,所以它包含在same_files列表中。

最后一点,子目录也会被保存,以便容易地完成递归比较。
import filecmp
dc = filecmp.dircmp('example/dir1', 'example/dir2')
print('Subdirectories:')
print(dc.subdirs)
属性subdirs是一个字典,它将目录名映射到新的dircmp对象。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
通过Python模块filecmp 对文件比较的实现方法
filecmp定义了两个函数,用于方便地比较文件与文件夹: filecmp.cmp(f1, f2[, shallow]): 比较两个文件的内容是否匹配.参数f1, f2指定要比较的文件的路径.可选参数shallow指定比较文件时是否需要考虑文件本身的属性(通过 os.stat函数可以获得文件属性).如果文件内容匹配,函数返回True,否则返回False, import filecmp s = filecmp.cmp("qin.txt", "jian.txt&quo
-
Python模块学习 filecmp 文件比较
filecmp定义了两个函数,用于方便地比较文件与文件夹: filecmp.cmp(f1, f2[, shallow]): 比较两个文件的内容是否匹配.参数f1, f2指定要比较的文件的路径.可选参数shallow指定比较文件时是否需要考虑文件本身的属性(通过os.stat函数可以获得文件属性).如果文件内容匹配,函数返回True,否则返回False. filecmp.cmpfiles(dir1, dir2, common[, shallow]): 比较两个文件夹内指定文件是否相等.参数dir1
-
python实现拼接图片
最近在写一篇卷积神经网络的论文,有好多实验结果需要整理,本来是用美图秀秀进行图像的拼接,但是发现重复操作太多,而且拼接效果不好,想到用python写个脚本实现,看一个简单的例子: 横向拼接 首先我需要将同一张图片的变形拼接为一行,代码如下: import os from PIL import Image UNIT_SIZE = 229 # 单个图像的大小为229*229 TARGET_WIDTH = 6 * UNIT_SIZE # 拼接完后的横向长度为6*229 path = "C:/Users
-
python实现遍历文件夹图片并重命名
在做深度学习相关项目时,需要标注图片,筛选过后图片名字带有括号,显得比较乱,因此利用python进行统一规范重命名操作 实现方法是利用python的os模块对文件夹进行遍历(listdir),然后使用rename进行改名操作 代码如下 # -*- coding:utf8 -*- import os class BatchRename(): ''' 批量重命名文件夹中的图片文件 ''' def __init__(self): self.path = 'C:/Users/lenovo/Desktop
-
python实现横向拼接图片
本文实例为大家分享了python实现横向拼接图片的具体代码,供大家参考,具体内容如下 import os from PIL import Image #单个图片的大小为150*150 UNIT_SIZE = 150 TARGET_WIDTH = 5 * UNIT_SIZE path = "存储图片的文件夹地址" images = [] imagefile = [] #存储所有图片文件名称 for root, dirs, files in os.walk(path): for f in
-
Python3 mmap内存映射文件示例解析
1. mmap内存映射文件 建立一个文件的内存映射将使用操作系统虚拟内存来直接访问文件系统上的数据,而不是使用常规的I/O函数访问数据.内存映射通常可以提供I/O性能,因为使用内存映射是,不需要对每个访问都建立一个单独的系统调用,也不需要在缓冲区之间复制数据:实际上,内核和用户应用都能直接访问内存. 内存映射文件可以看作是可修改的字符串或类似文件的对象,这取决于具体的需要.映射文件支持一般的文件API方法,如close().flush().read().readline().seek().tel
-
Python3 io文本及原始流I/O工具用法详解
io模块在解释器的内置open()之上实现了一些类来完成基于文件的输入和输出操作.这些类得到了适当的分解,从而可以针对不同的用途重新组合--例如,支持向一个网络套接字写Unicode数据. 1.1 内存中的流 StringIO提供了一种很便利的方式,可以使用文件API(如read().write()等)处理内存中的文本.有些情况下,与其他一些字符串连接技术相比,使用StringIO构造大字符串可以提供更好的性能.内存中的流缓冲区对测试也很有用,写入磁盘上真正的文件并不会减慢测试套件的速度. 下面
-
Python3 filecmp模块测试比较文件原理解析
1.filecmp比较文件 filecmp模块提供了一些函数和一个类来比较文件系统上的文件和目录. 1.1 示例数据 使用下面代码创建一组测试文件. import os def mkfile(filename, body=None): with open(filename, 'w') as f: f.write(body or filename) return def make_example_dir(top): if not os.path.exists(top): os.mkdir(top)
-
java多线程下载文件原理解析
原理解析:利用RandomAccessFile在本地创建一个随机访问文件,文件大小和服务器要下载的文件大小相同.根据线程的数量(假设有三个线程),服务器的文件三等分,并把我们在本地创建的文件同样三等分,每个线程下载自己负责的部分,到相应的位置即可. 示例图: 示例demo import java.io.InputStream; import java.io.RandomAccessFile; import java.net.HttpURLConnection; import java.net.U
-
C++将模板实现放入头文件原理解析
目录 写在前面 例子 原因 分析 解决方案 方案一 方案二 参考 写在后面 写在前面 本文通过实例分析与讲解,解释了为什么C++一般将模板实现放在头文件中.这主要与C/C++的编译机制以及C++模板的实现原理相关,详情见正文.同时,本文给出了不将模板实现放在头文件中的解决方案. 例子 现有如下3个文件: // add.h template <typename T> T Add(const T &a, const T &b); // add.cpp #include "
-

Spring Boot 文件上传原理解析
首先我们要知道什么是Spring Boot,这里简单说一下,Spring Boot可以看作是一个框架中的框架--->集成了各种框架,像security.jpa.data.cloud等等,它无须关心配置可以快速启动开发,有兴趣可以了解下自动化配置实现原理,本质上是 spring 4.0的条件化配置实现,深抛下注解,就会看到了. 说Spring Boot 文件上传原理 其实就是Spring MVC,因为这部分工作是Spring MVC做的而不是Spring Boot,那么,SpringMVC又是怎么
-
Python3中configparser模块读写ini文件并解析配置的用法详解
Python3中configparser模块简介 configparser 是 Pyhton 标准库中用来解析配置文件的模块,并且内置方法和字典非常接近.Python2.x 中名为 ConfigParser,3.x 已更名小写,并加入了一些新功能. 配置文件的格式如下: [DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User =
-
Laravel框架源码解析之入口文件原理分析
本文实例讲述了Laravel框架源码解析之入口文件原理.分享给大家供大家参考,具体如下: 前言 提升能力的方法并非使用更多工具,而是解刨自己所使用的工具.今天我们从Laravel启动的第一步开始讲起. 入口文件 laravel是单入口框架,所有请求必将经过index.php define('LARAVEL_START', microtime(true)); // 获取启动时间 使用composer是现代PHP的标志 require __DIR__.'/../vendor/autoload.php
-
Java文件断点续传实现原理解析
一.作用: 随机流(RandomAccessFile)不属于IO流,支持对文件的读取和写入随机访问. 二.随机访问文件原理: 首先把随机访问的文件对象看作存储在文件系统中的一个大型 byte 数组,然后通过指向该 byte 数组的光标或索引(即:文件指针 FilePointer)在该数组任意位置读取或写入任意数据. 三.相关方法说明: 1.对象声明:RandomAccessFile raf = newRandomAccessFile(File file, String mode); 其中参数 m
-
Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args] 本文想要聊聊比较特殊的"-m"选项: 关于它的典型用法.原理解析与发展演变的过程. 首先,让我们用"--help"来看看它的解释: -m mod run library module as a script (ter
-
Python 虚拟环境工作原理解析
目录 简介 使用 激活脚本 工作原理 关于 sys.prefix 总结 其它 Python 的虚拟环境用来创建一个相对独立的执行环境,尤其是一些依赖的三方包,最常见的如不同项目依赖同一个但是不同版本的三方包,而且,在虚拟环境中的安装包不会影响到系统的安装包. 不过,其具体的工作原理是怎样的,这里详细介绍. 简介 几乎每个语言都包含自己的包管理工具,这是一个非常复杂的话题,而不同语言选择的实现又略有区别,都会做一些选择和取舍.而 Python 的包管理解决方案很多,例如 pip.virtualen