Python+Appium新手教程
准备
1.电脑系统:win10
2.手机:安卓(没钱买苹果)
3.需要的工具可以从官网下载
- https://appium.io/
- https://www.jetbrains.com/pycharm/
- https://www.python.org/
- https://www.oracle.com/cn/java/technologies/javase-downloads.html
安装
- python
- jdk
- 编辑器PyCharm
- Appium-windows-x.x
- Appium_Python_Client
- Android SDK
安装,迈开腿的第一步
python(它可以用于桌面应用,游戏开发,网络爬虫)
勾选Add Python x.x to PATH(没有勾选的安装成功后可手动在环境变量里配置)
Install Now

安装中…
安装成功

验证是否成功,终端输入‘python',出现以下内容就成功了

暂时没遇到红海,有问题评论留言~
jdk
Java 语言的软件开发工具包
appium server好像只支持1.8的jdk,so有时候太优秀不一定能被认可(狗头保命)



安装成功,需要在环境变量里配置一下

新建一个'JAVA_HOME'

把‘JAVA_HOME'添加到path里,注意是添加不是替换,后果不堪设想

确定确定确定,打开cmd运行测试一下是否安装成功,输入‘java -version',成功

编辑器PyCharm
敲代码的

勾选64-bit launcher 64位启动器
.py那个随意,我这边勾选


成功
安装过程暂时没发现什么错误
Appium-windows-x.x
运行脚本需要,可查看运行日志,可以获取app页面元素


第一次运行可能有点慢,耐心等待就好了

右上角的三个按钮分别是
- “start inspector session(启动检查器会话)”
- “Get Raw log(查看日志)"
- “Stop Server(停止服务)”
通俗一点 “冲啊” “让我看看” “不想搞了”
下面一块是看日志的

最喜欢的来了,菜单栏有个View—语言—中文(我的宝贝啊)

Appium_Python_Client
调用客户端库和 Appium Server 进行通信
pip install Appium-Python-Client
或者去Pypi下载
下载后解压使用cmd进入Appium-Python-Client-x.x
输入
python setup.py install
运行 setup.py文件就好了

Android SDK
手机baiandroid系统的开发发包,用来执行命令设置手机、传送文件、安装应用、查看手机界面等
找个风水宝地解压就好了
所有需要的工具都安装成功了,来个表情包庆祝一下
连接手机
敲黑板,重点来了,做app自动化肯定要用到手机噻,拿usb连接电脑
(1) 拿出你的手机-----打开手机设置------找到关于手机-------一直点击版本号直到出现提示

(2) 打开手机的开发者选项,该开的开,该关的关,特别是USB调试这里一定要打开

还有USB设置需要改一下,暂时只发现这两个比较重要,有兴趣的可以研究一下开发人员选项

(3) 测试是否连接成功,在终端输入‘adb devices -l',查看连接的设备,如果列表为空,检查一下是不是有以上原因。

使用python+appium打开手机app-B站
打开PyCharm and appium,直接Start Server Vx,xx,x
新建一个项目

新建一个.py,输入以下代码(单纯打开app)
# 导入webdriver
from appium import webdriver
# 初始化参数
desired_caps = {
'platformName': 'Android', # 被测手机是安卓
'platformVersion': '10', # 手机安卓版本
'deviceName': 'xxx', # 设备名,安卓手机可以随意填写
'appPackage': 'tv.danmaku.bili', # 启动APP Package名称
'appActivity': '.ui.splash.SplashActivity', # 启动Activity名称
'unicodeKeyboard': True, # 使用自带输入法,输入中文时填True
'resetKeyboard': True, # 执行完程序恢复原来输入法
'noReset': True, # 不要重置App,如果为False的话,执行完脚本后,app的数据会清空,比如你原本登录了,执行完脚本后就退出登录了
'newCommandTimeout': 6000,
'automationName': 'UiAutomator2'
}
# 连接Appium Server,初始化自动化环境
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
# 退出程序,记得之前没敲这段报了一个错误 Error: socket hang up 啥啥啥的忘记了,有兴趣可以try one try
driver.quit()
不同的手机有不同的版本,自己找一下大概就是这个意思
手机安卓版本platformVersion:

每一个app都有appPackage、appActivity,那应该在哪里查看呢
打开终端输入(手机需要连接电脑)
adb shell dumpsys activity recents | find “intent={”
cmp=tv.danmaku.bili/.ui.splash.SplashActivity就是我们需要的appPackage、appActivity了
appPackage = tv.danmaku.bili
appActivity = .ui.splash.SplashActivity

此时我的手机后台是个这样的
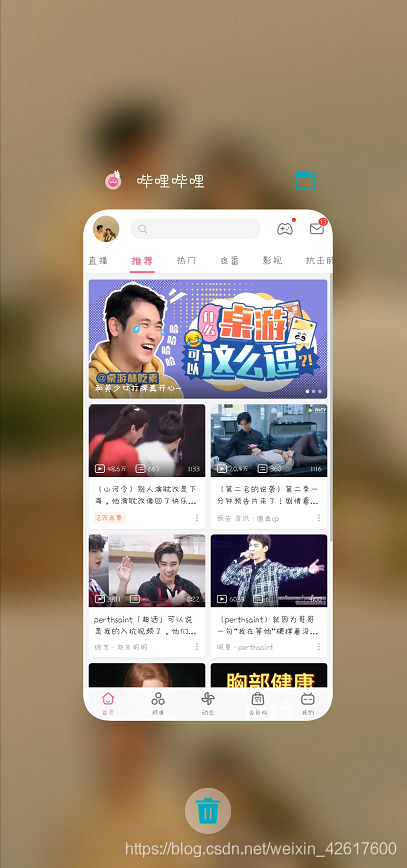
打开成功,运行的时候会在手机上安装东西,需要手动同意安装,或者在开发选项中开权限,听懂鞭炮
获取app元素信息
得到元素才能操控它
两种方法
(1)使用appium
(2)使用uiautomatorviewer(Android SDK自带的元素定位工具)
这两个不可以同时使用,以我现在的技术来看我个人推荐使用appium
-----------------------------这是一条分割线------------------------------------
appium:打开appium,点击Start Inspector Session
输入对应的内容(之前那段代码把参数和值填进去就好了)

打开后我们可以看见这样一个界面,鼠标悬浮在手机界面上可以看到元素,点击可在右侧查看到需要的元素

uiautomatorviewer(Android SDK自带的元素定位工具)
之前下载过的Android SDK,打开路径:androidsdk\tools\bin就可以找到uiautomatorviewer了,double click打开它

会得到这样的一个界面
在点击左上角的device Screenshot(uiautomator dump)获取手机上的屏幕,如果是不同的页面需要重新点击

鼠标悬浮点击可以看到这个元素的信息

有一些人点击uiautomatorviewer.bat会闪退,试试下面这个办法,如果不行百度去吧
开玩笑的啦,我也是百度找方法的,找了好久没啥子用,还是评论区留言一起解决吧(一起百度)
打开环境变量,新建一个 ANDROID_SWT
我的swt是在D:\app\androidsdk\tools\lib\x86_64,输入正确路径即可

确定确定确定,在重新试试double click它
知道元素后就可以操作它了
使用python+appium操作app-B站
目标:使用B站搜索‘泰坦尼克号'
常用的获取元素方法有
find_element_by_id()
find_elements_by_class_name()
find_element_by_xpath()
find_element_by_css_selector()
# 导入webdriver
from appium import webdriver
# 初始化参数
desired_caps = {
'platformName': 'Android', # 被测手机是安卓
'platformVersion': '10', # 手机安卓版本
'deviceName': 'xxx', # 设备名,安卓手机可以随意填写
'appPackage': 'tv.danmaku.bili', # 启动APP Package名称
'appActivity': '.ui.splash.SplashActivity', # 启动Activity名称
'unicodeKeyboard': True, # 使用自带输入法,输入中文时填True
'resetKeyboard': True, # 执行完程序恢复原来输入法
'noReset': True, # 不要重置App,如果为False的话,执行完脚本后,app的数据会清空,比如你原本登录了,执行完脚本后就退出登录了
'newCommandTimeout': 6000,
'automationName': 'UiAutomator2'
}
# 连接Appium Server,初始化自动化环境
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
# 设置等待时间,如果不给时间的话可能会找不到元素
driver.implicitly_wait(5)
# 点击搜索框
driver.find_element_by_id("expand_search").click()
# 输入“泰坦尼克号”
driver.find_element_by_id("search_src_text").send_keys("泰坦尼克号")
# 键盘回车
driver.keyevent(66)
# 因为它搜索完后就直接退出app了,看不到搜索结果页,所以我给了一个让他停下的方法
input('**********')
# 退出程序,记得之前没敲这段报了一个错误 Error: socket hang up 啥啥啥的忘记了,有兴趣可以try one try
driver.quit()
最后就是这样子的

到此这篇Python+Appium新手教程的文章就介绍到这了,更多相关Python+Appium教程内容请搜索我们以前的文章或继续浏览下面的相关文章,希望大家以后多多支持我们!
相关推荐
-
用Python实现Newton插值法
1. n阶差商实现 def diff(xi,yi,n): """ param xi:插值节点xi param yi:插值节点yi param n: 求几阶差商 return: n阶差商 """ if len(xi) != len(yi): #xi和yi必须保证长度一致 return else: diff_quot = [[] for i in range(n)] for j in range(1,n+1): if j == 1: for i in
-
python matplotlib绘图实现删除重复冗余图例的操作
问题: 由于自己做项目的时候,需要循环的绘制数据,假设有100个样本,每个样本包含两个坐标点(A, B),我需要对这两个点标上不同的颜色,同时还要画出两点间的连线. 显然这个问题中图例我只需要3个(A点,B点,AB的连线),而不是300个,因为每个样本的A点都是同样的颜色,B点也都是一样的颜色,AB的连线也是. 但是单纯的在画完图之后用plt.legend(), 它会给你画出所有300个图例来,这肯定不是我想要的. 探索过程: 如何解决呢? 当然有一种很强制的方法,就是只在画第一个样本,或最后一
-

python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
用Python的绘图库(matplotlib)绘制小波能量谱
时间小波能量谱 反映信号的小波能量沿时间轴的分布. 由于小波变换具有等距效应,所以有: 式中 表示信号强度,对于式①在平移因子b方向上进行加权积分 式中 代表时间-小能量谱 尺度小波能量谱 反映信号的小波能量随尺度的变化情况. 同理,对式①在尺度方向上进行加权积分: 式中 连续小波变换 连续小波变换的结果是一个小波系数矩阵,随着尺度因子和位移因子变化.然后将系数平方后得到小波能量,把每个尺度因子对应的所有小波能量进行叠加,那么就可以得到随尺度因子变换的小波能量谱曲线.把尺度换算成频率后,这条曲线
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
python爬虫之教你如何爬取地理数据
一.shapely模块 1.shapely shapely是python中开源的针对空间几何进行处理的模块,支持点.线.面等基本几何对象类型以及相关空间操作. 2.point→Point类 curve→LineString和LinearRing类: surface→Polygon类 集合方法分别对应MultiPoint.MultiLineString.MultiPolygon 3.导入所需模块 # 导入所需模块 from shapely import geometry as geo from s
-
在python代码中加入环境变量的语句操作
以GraphViz为例: 下载安装好的路径名字为C:/Program Files (x86)/Graphviz2.38 import os os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径 os.environ['path']返回的是所有环境变量的所在的位置,我们这里是为了添加,所以再重新造一个. os.pathsep返回的是分隔符";" 补
-
Python requests timeout的设置
背景 最近在搞爬虫,很多小组件里面都使用了 Python 的 requests 库,很好用,很强大. 但最近发现很多任务总是莫名其妙的卡住,不报错,但是就是不继续执行. 排查了一圈,最后把问题锁定在 requests 的 timeout 机制上. 注:本文讨论的是 Python 的第三方模块 requests,并不是 Python 内建模块 urllib 中的 request 模块,请注意区分. 如何设置超时时间 requests 设置超时时间有两种方式. 一种是设置单一值作为 timeout,
-
Python+Appium新手教程
准备 1.电脑系统:win10 2.手机:安卓(没钱买苹果) 3.需要的工具可以从官网下载 https://appium.io/ https://www.jetbrains.com/pycharm/ https://www.python.org/ https://www.oracle.com/cn/java/technologies/javase-downloads.html 安装 python jdk 编辑器PyCharm Appium-windows-x.x Appium_Python_Cl
-
Python完全新手教程
Python入门教程FROM:http://www.cnblogs.com/taowen/articles/11239.aspx作者:taowen, billrice Lesson 1 准备好学习Python的环境 下载的地址是: www.python.org linux版本的我就不说了,因为如果你能够使用linux并安装好说明你可以一切自己搞定的. 运行环境可以是linux或者是windows: 1.linux redhat的linux安装上去之后一定会有python的(必须的组件),在命令行
-
超详细Python解释器新手安装教程
Step1:确定操作系统 Python 解释器的下载地址为:https://www.python.org/ ,点击 "Downloads"选项如下图所示: 可以看到最新版为 Python3.8.2,接下来根据自己的情况选择相应的电脑系统,如点击"Windows"选项进入详细的下载列表: 上图中可以看到一共有 7 个下载链接,第 1 个为帮助文档,其余 6 个根据操作系统位数不同分为 3 类,以 64 位操作系统为例 3 类安装包描述如下图: Step2:下载离线安装
-
Python pygame新手入门基础教程
目录 pygame简介 pygame实现窗口 设置屏幕背景色 添加文字 绘制多边形 绘制直线 绘制圆形 绘制椭圆 绘制矩形 总结 pygame简介 pygame可以实现python游戏的一个基础包. pygame实现窗口 初始化pygame,init()类似于java类的初始化方法,用于pygame初始化. pygame.init() 设置屏幕,(500,400)设置屏幕初始大小为500 * 400的大小, 0和32 是比较高级的用法.这样我们便设置了一个500*400的屏幕. surface
-
Python爬虫新手入门之初学lxml库
1.爬虫是什么 所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本.万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息. 2.爬虫三要素 抓取 分析 存储 3.爬虫的过程分析 当人类去访问一个网页时,是如何进行的? ①打开浏览器,输入要访问的网址,发起请求. ②等待服务器返回数据,通过浏览器加载网页. ③从网页中找到自己需要的数据(文本.图片.文件等等). ④保存自己需要的数据. 对于爬虫,也是类似的.它模仿人类请求网页的过程,但是又稍有不同.
-
Python简明入门教程
本文实例讲述了Python简明入门教程.分享给大家供大家参考.具体如下: 一.基本概念 1.数 在Python中有4种类型的数--整数.长整数.浮点数和复数. (1)2是一个整数的例子. (2)长整数不过是大一些的整数. (2)3.23和52.3E-4是浮点数的例子.E标记表示10的幂.在这里,52.3E-4表示52.3 * 10-4. (4)(-5+4j)和(2.3-4.6j)是复数的例子. 2.字符串 (1)使用单引号(') (2)使用双引号(") (3)使用三引号('''或"&q
-
python爬虫入门教程--优雅的HTTP库requests(二)
前言 urllib.urllib2.urllib3.httplib.httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反人类,更糟糕的是这些模块在 Python2 与 Python3 中有很大的差异,如果业务代码要同时兼容 2 和 3,写起来会让人崩溃. 好在,还有一个非常惊艳的 HTTP 库叫 requests,它是 GitHUb 关注数最多的 Python 项目之一,requests 的作者是 Kenneth Reitz 大神. requests 实现了 HTTP
-
Python Flask基础教程示例代码
本文研究的主要是Python Flask基础教程,具体介绍如下. 安装:pip install flask即可 一个简单的Flask from flask import Flask #导入Flask app = Flask(__name__) #创建一个Flask实例 #设置路由,即url @app.route('/') #url对应的函数 def hello_world(): #返回的页面 return 'Hello World!' #这个不是作为模块导入的时候运行,比如这个文件为aa.py,
-
python MySQLdb使用教程详解
本文主要内容python MySQLdb数据库批量插入insert,更新update的: 1.python MySQLdb的使用,写了一个基类让其他的sqldb继承这样比较方便,数据库的ip, port等信息使用json配置文件 2.常见的查找,批量插入更新 下面贴出基类代码: # _*_ coding:utf-8 _*_ import MySQLdb import json import codecs # 这个自己改一下啊 from utils.JsonUtil import get_json
-
selenium+python环境配置教程详解
一.安装Python 1)官网下载安装 2)配置环境变量(未勾选自动配置需要手动配置) 3)检查是否安装成功(交互窗口中输入Python -v) 二.Selenium 3.X +FireFox 驱动 +geckodriver 1.安装selenium: 1)W+r输入cmd,然后输入pip install selenium 2)安装FireFox,添加附加组件selenium IDE.FireBUG 3) https://github.com/mozilla/geckodriver/releas