利用Python自制网页并实现一键自动生成探索性数据分析报告
目录
- 前言
- 上传文件以及变量的筛选
前言
今天小编带领大家用Python自制一个自动生成探索性数据分析报告这样的一个工具,大家只需要在浏览器中输入url便可以轻松的访问,如下所示:

第一步
首先我们导入所要用到的模块,设置网页的标题、工具栏以及logo的导入,代码如下:
from st_aggrid import AgGrid
import streamlit as st
import pandas as pd
import pandas_profiling
from streamlit_pandas_profiling import st_profile_report
from pandas_profiling import ProfileReport
from PIL import Image
st.set_page_config(layout='wide') #Choose wide mode as the default setting
#Add a logo (optional) in the sidebar
logo = Image.open(r'wechat_logo.jpg')
st.sidebar.image(logo, width=120)
#Add the expander to provide some information about the app
with st.sidebar.expander("关于这个项目"):
st.write("""
该项目是将streamlit和pandas_profiling相结合,在您上传数据集之后自动生成相关的数据分析报告,当然该项目提供了两种模式 全量分析还是部分少量分析,这里推荐用部分少量分析,因为计算量更少,所需要的时间更短,效率更高
""")
#Add an app title. Use css to style the title
st.markdown(""" <style> .font {
font-size:30px ; font-family: 'Cooper Black'; color: #FF9633;}
</style> """, unsafe_allow_html=True)
st.markdown('<p class="font">请上传您的数据集,该应用会自动生成相关的数据分析报告</p>', unsafe_allow_html=True)
output:
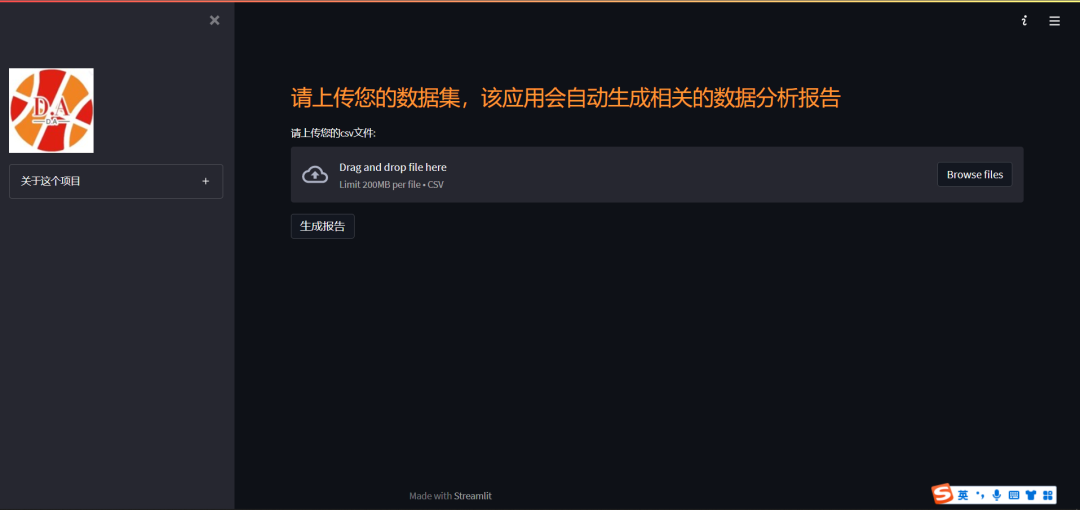
上传文件以及变量的筛选
紧接的是我们需要上传csv文件,代码如下:
uploaded_file = st.file_uploader("请上传您的csv文件: ", type=['csv'])
我们可以选择针对数据集当中所有的特征进行一个统计分析,或者只是针对部分的变量来一个数据分析,
代码如下:
if uploaded_file is not None:
df = pd.read_csv(uploaded_file)
option1 = st.sidebar.radio(
'您希望您的数据分析报告中包含哪些变量呢',
('所有变量', '部分变量'))
if option1 == '所有变量':
df = df
elif option1 == '部分变量':
var_list = list(df.columns)
要是用户勾选的是部分变量,只是针对部分变量来进行一个分析的话,就会弹出来一个多选框来供用户选择,
代码如下:
var_list = list(df.columns) option3 = st.sidebar.multiselect( '筛选出您希望在数据分析报告中包含的变量', var_list) df = df[option3]
用户可以挑选到底是“简单分析”或者是“完整分析”,要是勾选的是“完整分析”的话,会跳出相应的提示,提示“完整分析”由于涉及到更加复杂的计算操作,耗时更加地长,要是遇到大型的数据集,还会有计算失败的情况出现
option2 = st.sidebar.selectbox(
'筛选模式,完整分析还是简单分析',
('简单分析', '完整分析'))
if option2 == '完整分析':
mode = 'complete'
st.sidebar.warning(
'完整分析由于涉及到更加复杂的计算操作,耗时更加地长,要是遇到大型的数据集,还会有计算失败的情况出现,这里推荐使用简单分析')
elif option2 == '简单分析':
mode = 'minimal'
grid_response = AgGrid(
df,
editable=True,
height=300,
width='100%',
)
updated = grid_response['data']
df1 = pd.DataFrame(updated)
当用户点击“生成报告”的时候就会自动生成一份完整的数据分析报告了,代码如下:
if st.button('生成报告'):
if mode=='complete':
profile=ProfileReport(df,
title="User uploaded table",
progress_bar=True,
dataset={
})
st_profile_report(profile)
elif mode=='minimal':
profile=ProfileReport(df1,
minimal=True,
title="User uploaded table",
progress_bar=True,
dataset={
})
st_profile_report(profile)
最后出来的结果如下:
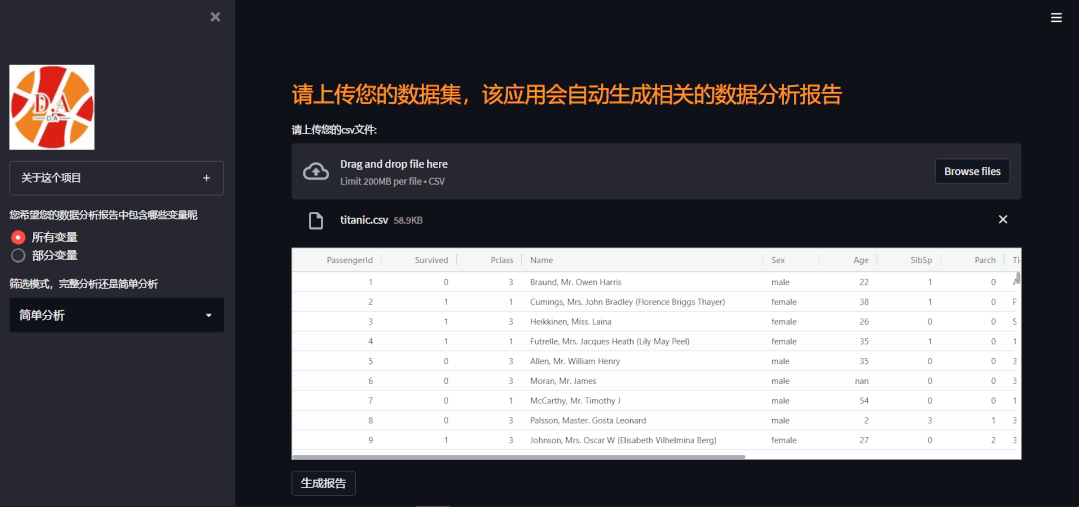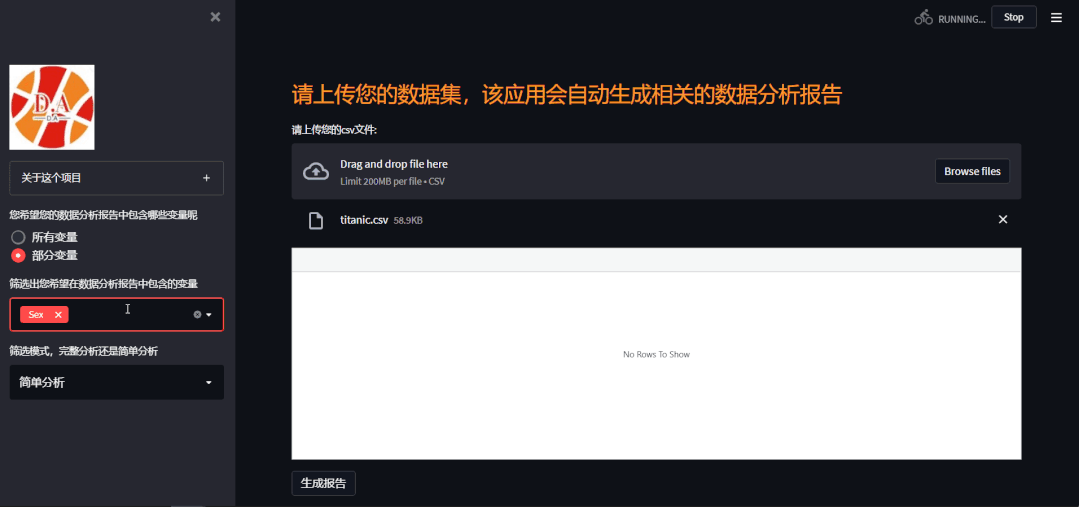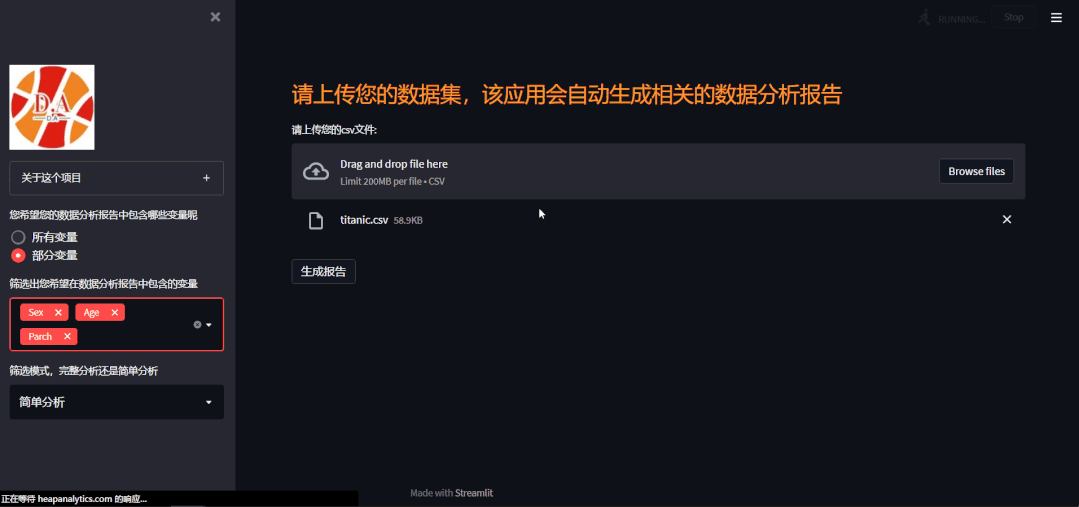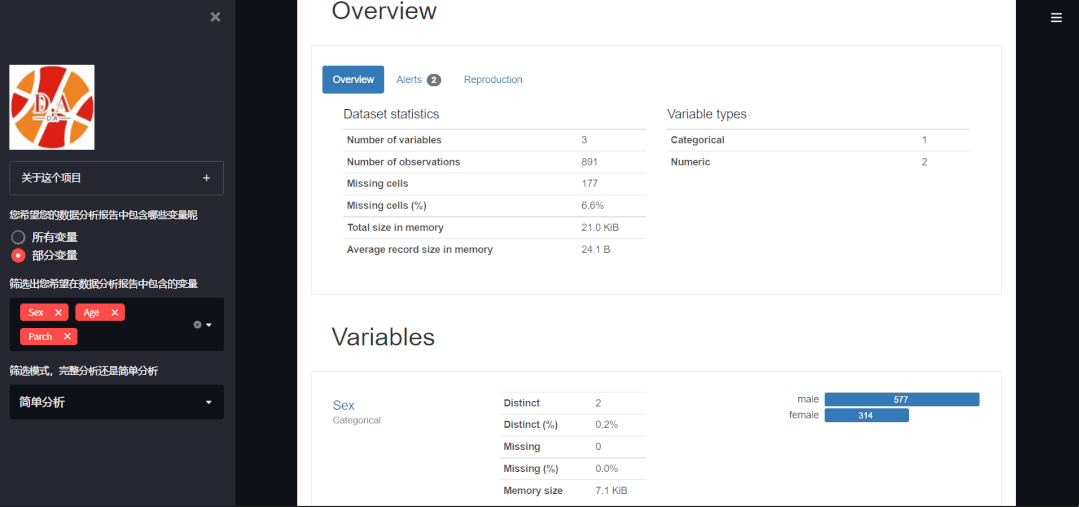
到此这篇关于利用Python自制了网页并实现一键自动生成探索性数据分析报告的文章就介绍到这了,更多相关 Python自制网页内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用pyscript在网页中撰写Python程式的方法
根据 Anaconda 的项目 pyscript,可以将 python 的代码直接写在网页中,目前只支援两种标签,分别是<py-script> 与 <py-repl>,以下是简单的示例. 使用这两行导入 pyscript <link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" rel="external nofollow" rel=&
-
python爬取网页数据到保存到csv
目录 任务需求: 爬取网址: 网址页面: 代码实现结果: 代码实现: 完整代码: 总结 任务需求: 爬取一个网址,将网址的数据保存到csv中. 爬取网址: https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title 网址页面: 代码实现结果: 代码实现: 导入包: import requests import parsel import csv 设置csv文件格
-
一文教会你用Python获取网页指定内容
目录 前言 1.抓取网页源代码 2.抓取一个网页源代码中的某标签内容 3.抓取多个网页子标签的内容 总结 前言 Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能在我们开始之前,我们需要安装一些环境依赖包,打开命令行 确保电脑中具有python和pip,如果没有的话则需要自行进行安装 之后我们可使用pip安装必备模块 requests pip install requests requests是python
-
Python爬虫网页元素定位术
目录 实战场景 基础用法如下所示 BeautifulSoup 模块的对象说明 BeautifulSoup 对象 Tag 对象 NavigableString 对象 Comment 对象 find() 方法和 find_all() 方法 实战场景 初学 Python 爬虫,十之八九大家采集的目标是网页,因此快速定位到网页内容,就成为我们面临的第一道障碍,本篇博客就为你详细说明最易上手的网页元素定位术,学完就会系列. 本文核心使用到的是 Beautiful Soup 模块,因此我们用来做测试采集的站
-
requests.gPython 用requests.get获取网页内容为空 ’ ’问题
目录 一.如何设置headers 1.QQ浏览器 2.Miscrosft edge 二.微软自带浏览器 下面先来看一个例子: import requests result=requests.get("http://data.10jqka.com.cn/financial/yjyg/") result 输出结果: 表示成功处理了请求,一般情况下都是返回此状态码: 报200代表没问题 继续运行,发现返回空值,在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止
-
python爬虫lxml库解析xpath网页过程示例
目录 前言 (一)xpath是什么 (二)xpath的基本语法 路径查询. (三) lxml库 (四)lxml库的使用 导入lxml.etree (五)实例演示 前言 在我们抓取网页内容的时候,通常是抓取一整个页面的内容,而我们仅仅只是需要该网页中的部分内容,那该如何去提取呢?本章就带你学习xpath插件的使用.去对网页的内容进行提取. (一)xpath是什么 xpath是一门在XML文档中查找信息的语言,xpath可用来在XML 文档中对元素和属性进行遍历,主流的浏览器都支持xpath,因为h
-
Python实现网页文件转PDF文件和PNG图片的示例代码
目录 一.html网页文件转pdf 二.html网页文件转png 一.html网页文件转pdf #将HTML文件导出为PDF def html_to_pdf(html_path,pdf_path='.\\pdf_new.pdf',html_encoding='UTF-8',path_wkpdf = r'.\Tools\wkhtmltopdf.exe'): ''' 将HTML文件导出为PDF :param html_path:str类型,目标HTML文件的路径,可以是一个路径,也可以是多个路径,以
-
Python用requests模块实现动态网页爬虫
目录 前言 开发工具 环境搭建 总结 前言 Python爬虫实战,requests模块,Python实现动态网页爬虫 让我们愉快地开始吧~ 开发工具 Python版本: 3.6.4 相关模块: urllib模块: random模块: requests模块: traceback模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 那我们就开启爬虫的正确姿势吧,先用解析接口的方法来写爬虫. 首先,找到真实请求.右键检查,点击Networ
-
利用Python自制网页并实现一键自动生成探索性数据分析报告
目录 前言 上传文件以及变量的筛选 前言 今天小编带领大家用Python自制一个自动生成探索性数据分析报告这样的一个工具,大家只需要在浏览器中输入url便可以轻松的访问,如下所示: 第一步 首先我们导入所要用到的模块,设置网页的标题.工具栏以及logo的导入,代码如下: from st_aggrid import AgGrid import streamlit as st import pandas as pd import pandas_profiling from streamlit_pan
-
利用Python自制一个批量图片水印添加器
前段时间写了个比较简单的批量水印添加的python实现方式,将某个文件夹下面的图片全部添加上水印. 今天正好有时间就做了一个UI应用的封装,这样不需要知道python直接下载exe的应用程序使用即可. 下面主要来介绍一下实现过程. 首先,还是老规矩介绍一下在开发过程中需要用到的python非标准库,由于这些库都是之前使用过的. 所以这里就直接导入到代码块中,如果没有的话直接使用pip的方式进行安装即可. # It imports all the classes, attributes, and
-
利用JAVA反射,读取数据库表名,自动生成对应实体类的操作
本代码是利用java反射,读取数据库表自动根据表名生成实体类,数据库采用老牌SQLSERVER 2000,驱动为JTDS,其他数据库可根据情况自定修改. 代码中包含了大部分数据库类型与JAVA类型的转换,少数未包含进去的会在生成代码时打印出来,方面后期查找修改. import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.io.PrintWriter; import java.sq
-
python工具快速为音视频自动生成字幕(使用说明)
为音视频自动生成字幕的 python 工具 autosub 是一个能自动为音视频生成字幕的 python 包,以下为其简介和使用说明. autosub autosub原本使用 python 2.X 开发,仅支持 linux 和 macos 系统,现已停止维护 其原理是对音视频文件进行语音活动检测以查找说话的区域,然后并行调用 Google Web Speech API 进行转录,(可选)翻译成目标语言,并将结果存储下来. autosub3 基于 autosub,升级到 python 3.X 版本
-
教你怎么用java一键自动生成数据库文档
这是该工具的github地址:https://github.com/pingfangushi/screw 一.引入pom.xml依赖 <dependencies> <!-- screw 库,简洁好用的数据库表结构文档生成器 --> <dependency> <groupId>cn.smallbun.screw</groupId> <artifactId>screw-core</artifactId> <version
-
利用Python制作本地Excel的查询与生成的程序问题
目录 前言 需求 实验步骤 Excel预览图片 查询 2.1 Excel的索引与输入 2.2 开始查询.丰富程序 追加查询结果到Excel 完整代码 前言 今天教大家利用Python制作本地Excel的查询与生成的程序 需求 制作一个程序 有一个简单的查询入口 实现Excel的查询与生成 实验步骤 1打开一个exe 弹出一个界面 2有一个查询 卡号 点击查询 3下方展示查询的结果 同时将这个查询的结果 追加到一个新的结果Excel文件里 4新的结果Excel文件 格式和源文件格式相同 但是每次都
-
Python使用selenium实现网页用户名 密码 验证码自动登录功能
好久没有学python了,反正各种理由吧(懒惰总会有千千万万的理由),最近网上学习了一下selenium,实现了一个简单的自动登录网页,具体如下. 1.安装selenium: 如果你已经安装好anaconda3,直接在windows的dos窗口输入命令安装selenium: python -m pip install --upgrade pip 查看版本pip show selenium 2.接着去http://chromedriver.storage.googleapis.com/index.
-
利用Python模拟登录pastebin.com的实现方法
任务 在https://pastebin.com网站注册一个账号,利用python实现用户的自动登录和创建paste.该任务需要分成如下两步利用python实现: 1.账号的自动登录 2.paste的自动创建 模拟账号登录 模拟登录,需要知道登录的URL是什么,那么登录URL怎么去看呢. 进入https://pastebin.com/之后,发现是以访客的身份进入的,点击身份图像的下拉中的LOGIN,进入登录页面,打开Chrome开发工具,选择Network,勾选Preserve log: 输入用
-
如何利用python之wxpy模块玩转微信
wxpy也是一个python的模块,利用它我们可以做很多有意思的事情 首先利用一句代码我们就可以利用python登录网页版微信 bot = Bot(cache_path= True) 这条语句会产生一个二维码,我们扫描了这个二维码之后就可以登录我们的微信了 功能一:获得微信好友信息 利用一行语句获得你微信好友的个数.男女比例.TOP10省份及TOP10城市 my_friends.stats_text() 效果如图 利用下面两行代码我们可以给微信好友发送信息 friends = my_friend
-
利用Python脚本实现自动刷网课
人在学校,身不由己.总有一些奇奇怪怪的学习任务,需要我们刷够一定的时长去完成,但这很多都是不太令人感兴趣的文字或是视频,而这些课都有共同的特点就是会间隔一定时间发出弹窗,确认屏幕前的我们是否还在浏览页面.每次靠人工去点击,会严重影响我们做其他正事的效率. 最近小李也需要刷够一定的学习时长.于是乎,我便找了好兄弟Python来帮忙.下面我们就用Python来实现自动化刷课吧! 说到自动化,Selenium这个浏览器自动化测试框架就派上了用场,整个自动刷课的主角便是它. 网站登录 那么为了实现自动刷