keras 实现轻量级网络ShuffleNet教程
ShuffleNet是由旷世发表的一个计算效率极高的CNN架构,它是专门为计算能力非常有限的移动设备(例如,10-150 MFLOPs)而设计的。该结构利用组卷积和信道混洗两种新的运算方法,在保证计算精度的同时,大大降低了计算成本。ImageNet分类和MS COCO对象检测实验表明,在40 MFLOPs的计算预算下,ShuffleNet的性能优于其他结构,例如,在ImageNet分类任务上,ShuffleNet的top-1 error 7.8%比最近的MobileNet低。在基于arm的移动设备上,ShuffleNet比AlexNet实际加速了13倍,同时保持了相当的准确性。
Paper:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
Github:https://github.com/zjn-ai/ShuffleNet-keras
网络架构
组卷积
组卷积其实早在AlexNet中就用过了,当时因为GPU的显存不足因而利用组卷积分配到两个GPU上训练。简单来讲,组卷积就是将输入特征图按照通道方向均分成多个大小一致的特征图,如下图所示左面是输入特征图右面是均分后的特征图,然后对得到的每一个特征图进行正常的卷积操作,最后将输出特征图按照通道方向拼接起来就可以了。

目前很多框架都支持组卷积,但是tensorflow真的不知道在想什么,到现在还是不支持组卷积,只能自己写,因此效率肯定不及其他框架原生支持的方法。组卷积层的代码编写思路就与上面所说的原理完全一致,代码如下。
def _group_conv(x, filters, kernel, stride, groups):
"""
Group convolution
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
# Returns
Output tensor
"""
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
in_channels = K.int_shape(x)[channel_axis]
# number of input channels per group
nb_ig = in_channels // groups
# number of output channels per group
nb_og = filters // groups
gc_list = []
# Determine whether the number of filters is divisible by the number of groups
assert filters % groups == 0
for i in range(groups):
if channel_axis == -1:
x_group = Lambda(lambda z: z[:, :, :, i * nb_ig: (i + 1) * nb_ig])(x)
else:
x_group = Lambda(lambda z: z[:, i * nb_ig: (i + 1) * nb_ig, :, :])(x)
gc_list.append(Conv2D(filters=nb_og, kernel_size=kernel, strides=stride,
padding='same', use_bias=False)(x_group))
return Concatenate(axis=channel_axis)(gc_list)
通道混洗
通道混洗是这篇paper的重点,尽管组卷积大量减少了计算量和参数,但是通道之间的信息交流也受到了限制因而模型精度肯定会受到影响,因此作者提出通道混洗,在不增加参数量和计算量的基础上加强通道之间的信息交流,如下图所示。

通道混洗层的代码实现很巧妙参考了别人的实现方法。通过下面的代码说明,d代表特征图的通道序号,x是经过通道混洗后的通道顺序。
>>> d = np.array([0,1,2,3,4,5,6,7,8]) >>> x = np.reshape(d, (3,3)) >>> x = np.transpose(x, [1,0]) # 转置 >>> x = np.reshape(x, (9,)) # 平铺 '[0 1 2 3 4 5 6 7 8] --> [0 3 6 1 4 7 2 5 8]'
利用keras后端实现代码:
def _channel_shuffle(x, groups): """ Channel shuffle layer # Arguments x: Tensor, input tensor of with `channels_last` or 'channels_first' data format groups: Integer, number of groups per channel # Returns Shuffled tensor """ if K.image_data_format() == 'channels_last': height, width, in_channels = K.int_shape(x)[1:] channels_per_group = in_channels // groups pre_shape = [-1, height, width, groups, channels_per_group] dim = (0, 1, 2, 4, 3) later_shape = [-1, height, width, in_channels] else: in_channels, height, width = K.int_shape(x)[1:] channels_per_group = in_channels // groups pre_shape = [-1, groups, channels_per_group, height, width] dim = (0, 2, 1, 3, 4) later_shape = [-1, in_channels, height, width] x = Lambda(lambda z: K.reshape(z, pre_shape))(x) x = Lambda(lambda z: K.permute_dimensions(z, dim))(x) x = Lambda(lambda z: K.reshape(z, later_shape))(x) return x
ShuffleNet Unit
ShuffleNet的主要构成单元。下图中,a图为深度可分离卷积的基本架构,b图为1步长时用的单元,c图为2步长时用的单元。
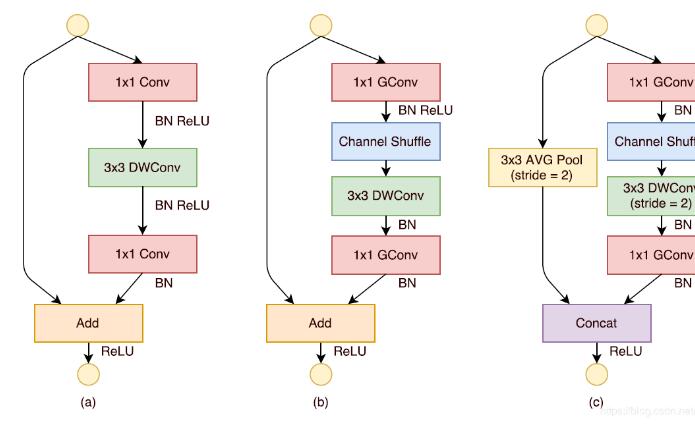
ShuffleNet架构
注意,对于第二阶段(Stage2),作者没有在第一个1×1卷积上应用组卷积,因为输入通道的数量相对较少。

环境
Python 3.6
Tensorlow 1.13.1
Keras 2.2.4
实现
支持channel first或channel last
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 25 18:26:41 2019
@author: zjn
"""
import numpy as np
from keras.callbacks import LearningRateScheduler
from keras.models import Model
from keras.layers import Input, Conv2D, Dropout, Dense, GlobalAveragePooling2D, Concatenate, AveragePooling2D
from keras.layers import Activation, BatchNormalization, add, Reshape, ReLU, DepthwiseConv2D, MaxPooling2D, Lambda
from keras.utils.vis_utils import plot_model
from keras import backend as K
from keras.optimizers import SGD
def _group_conv(x, filters, kernel, stride, groups):
"""
Group convolution
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
# Returns
Output tensor
"""
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
in_channels = K.int_shape(x)[channel_axis]
# number of input channels per group
nb_ig = in_channels // groups
# number of output channels per group
nb_og = filters // groups
gc_list = []
# Determine whether the number of filters is divisible by the number of groups
assert filters % groups == 0
for i in range(groups):
if channel_axis == -1:
x_group = Lambda(lambda z: z[:, :, :, i * nb_ig: (i + 1) * nb_ig])(x)
else:
x_group = Lambda(lambda z: z[:, i * nb_ig: (i + 1) * nb_ig, :, :])(x)
gc_list.append(Conv2D(filters=nb_og, kernel_size=kernel, strides=stride,
padding='same', use_bias=False)(x_group))
return Concatenate(axis=channel_axis)(gc_list)
def _channel_shuffle(x, groups):
"""
Channel shuffle layer
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
groups: Integer, number of groups per channel
# Returns
Shuffled tensor
"""
if K.image_data_format() == 'channels_last':
height, width, in_channels = K.int_shape(x)[1:]
channels_per_group = in_channels // groups
pre_shape = [-1, height, width, groups, channels_per_group]
dim = (0, 1, 2, 4, 3)
later_shape = [-1, height, width, in_channels]
else:
in_channels, height, width = K.int_shape(x)[1:]
channels_per_group = in_channels // groups
pre_shape = [-1, groups, channels_per_group, height, width]
dim = (0, 2, 1, 3, 4)
later_shape = [-1, in_channels, height, width]
x = Lambda(lambda z: K.reshape(z, pre_shape))(x)
x = Lambda(lambda z: K.permute_dimensions(z, dim))(x)
x = Lambda(lambda z: K.reshape(z, later_shape))(x)
return x
def _shufflenet_unit(inputs, filters, kernel, stride, groups, stage, bottleneck_ratio=0.25):
"""
ShuffleNet unit
# Arguments
inputs: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
stage: Integer, stage number of ShuffleNet
bottleneck_channels: Float, bottleneck ratio implies the ratio of bottleneck channels to output channels
# Returns
Output tensor
# Note
For Stage 2, we(authors of shufflenet) do not apply group convolution on the first pointwise layer
because the number of input channels is relatively small.
"""
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
in_channels = K.int_shape(inputs)[channel_axis]
bottleneck_channels = int(filters * bottleneck_ratio)
if stage == 2:
x = Conv2D(filters=bottleneck_channels, kernel_size=kernel, strides=1,
padding='same', use_bias=False)(inputs)
else:
x = _group_conv(inputs, bottleneck_channels, (1, 1), 1, groups)
x = BatchNormalization(axis=channel_axis)(x)
x = ReLU()(x)
x = _channel_shuffle(x, groups)
x = DepthwiseConv2D(kernel_size=kernel, strides=stride, depth_multiplier=1,
padding='same', use_bias=False)(x)
x = BatchNormalization(axis=channel_axis)(x)
if stride == 2:
x = _group_conv(x, filters - in_channels, (1, 1), 1, groups)
x = BatchNormalization(axis=channel_axis)(x)
avg = AveragePooling2D(pool_size=(3, 3), strides=2, padding='same')(inputs)
x = Concatenate(axis=channel_axis)([x, avg])
else:
x = _group_conv(x, filters, (1, 1), 1, groups)
x = BatchNormalization(axis=channel_axis)(x)
x = add([x, inputs])
return x
def _stage(x, filters, kernel, groups, repeat, stage):
"""
Stage of ShuffleNet
# Arguments
x: Tensor, input tensor of with `channels_last` or 'channels_first' data format
filters: Integer, number of output channels
kernel: An integer or tuple/list of 2 integers, specifying the
width and height of the 2D convolution window.
strides: An integer or tuple/list of 2 integers,
specifying the strides of the convolution along the width and height.
Can be a single integer to specify the same value for
all spatial dimensions.
groups: Integer, number of groups per channel
repeat: Integer, total number of repetitions for a shuffle unit in every stage
stage: Integer, stage number of ShuffleNet
# Returns
Output tensor
"""
x = _shufflenet_unit(x, filters, kernel, 2, groups, stage)
for i in range(1, repeat):
x = _shufflenet_unit(x, filters, kernel, 1, groups, stage)
return x
def ShuffleNet(input_shape, classes):
"""
ShuffleNet architectures
# Arguments
input_shape: An integer or tuple/list of 3 integers, shape
of input tensor
k: Integer, number of classes to predict
# Returns
A keras model
"""
inputs = Input(shape=input_shape)
x = Conv2D(24, (3, 3), strides=2, padding='same', use_bias=True, activation='relu')(inputs)
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
x = _stage(x, filters=384, kernel=(3, 3), groups=8, repeat=4, stage=2)
x = _stage(x, filters=768, kernel=(3, 3), groups=8, repeat=8, stage=3)
x = _stage(x, filters=1536, kernel=(3, 3), groups=8, repeat=4, stage=4)
x = GlobalAveragePooling2D()(x)
x = Dense(classes)(x)
predicts = Activation('softmax')(x)
model = Model(inputs, predicts)
return model
if __name__ == '__main__':
model = ShuffleNet((224, 224, 3), 1000)
#plot_model(model, to_file='ShuffleNet.png', show_shapes=True)
以上这篇keras 实现轻量级网络ShuffleNet教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
在keras中model.fit_generator()和model.fit()的区别说明
首先Keras中的fit()函数传入的x_train和y_train是被完整的加载进内存的,当然用起来很方便,但是如果我们数据量很大,那么是不可能将所有数据载入内存的,必将导致内存泄漏,这时候我们可以用fit_generator函数来进行训练. keras中文文档 fit fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=N
-
浅谈keras通过model.fit_generator训练模型(节省内存)
前言 前段时间在训练模型的时候,发现当训练集的数量过大,并且输入的图片维度过大时,很容易就超内存了,举个简单例子,如果我们有20000个样本,输入图片的维度是224x224x3,用float32存储,那么如果我们一次性将全部数据载入内存的话,总共就需要20000x224x224x3x32bit/8=11.2GB 这么大的内存,所以如果一次性要加载全部数据集的话是需要很大内存的. 如果我们直接用keras的fit函数来训练模型的话,是需要传入全部训练数据,但是好在提供了fit_generator,
-
浅谈keras2 predict和fit_generator的坑
1.使用predict时,必须设置batch_size,否则效率奇低. 查看keras文档中,predict函数原型: predict(self, x, batch_size=32, verbose=0) 说明: 只使用batch_size=32,也就是说每次将batch_size=32的数据通过PCI总线传到GPU,然后进行预测.在一些问题中,batch_size=32明显是非常小的.而通过PCI传数据是非常耗时的. 所以,使用的时候会发现预测数据时效率奇低,其原因就是batch_size太小
-
keras 实现轻量级网络ShuffleNet教程
ShuffleNet是由旷世发表的一个计算效率极高的CNN架构,它是专门为计算能力非常有限的移动设备(例如,10-150 MFLOPs)而设计的.该结构利用组卷积和信道混洗两种新的运算方法,在保证计算精度的同时,大大降低了计算成本.ImageNet分类和MS COCO对象检测实验表明,在40 MFLOPs的计算预算下,ShuffleNet的性能优于其他结构,例如,在ImageNet分类任务上,ShuffleNet的top-1 error 7.8%比最近的MobileNet低.在基于arm的移动设
-
使用keras实现孪生网络中的权值共享教程
首先声明,这里的权值共享指的不是CNN原理中的共享权值,而是如何在构建类似于Siamese Network这样的多分支网络,且分支结构相同时,如何使用keras使分支的权重共享. Functional API 为达到上述的目的,建议使用keras中的Functional API,当然Sequential 类型的模型也可以使用,本篇博客将主要以Functional API为例讲述. keras的多分支权值共享功能实现,官方文档介绍 上面是官方的链接,本篇博客也是基于上述官方文档,实现的此功能.(插
-
使用Keras画神经网络准确性图教程
1.在搭建网络开始时,会调用到 keras.models的Sequential()方法,返回一个model参数表示模型 2.model参数里面有个fit()方法,用于把训练集传进网络.fit()返回一个参数,该参数包含训练集和验证集的准确性acc和错误值loss,用这些数据画成图表即可. 如: history=model.fit(x_train, y_train, batch_size=32, epochs=5, validation_split=0.25) #获取数据 #########画图
-

手把手教你使用 virtualBox 让虚拟机连接网络的教程
1 设置 virtualBox 打开设置->网络 采用桥接模式连接网络,并选择对应的物理网卡. 2 设置虚拟机(centos7) 1.使用 nmcli 命令,查看当前虚拟机的所有网络基本信息: nmcli connection show 具体参数说明如下: 参数名称 说明 NAME 连网代号,通常与 DEVICE 一样 UUID 识别码 TYPE 网卡的类型:802-3-ethernet 就是以太网 DEVICE 网卡名称 * 这里的 enp0s3 是 centos7 自动生成的带随机数的网卡名
-
VMWare虚拟机15.X局域网网络配置教程图解
最近在搞几台虚拟机来学习分布式和大数据的相关技术,首先先要把虚拟机搞起来,搞起虚拟机第一步先安装系统,接着配置网络 vmware为我们提供了三种网络工作模式,它们分别是:Bridged(桥接模式).NAT(网络地址转换模式).Host-Only(仅主机模式). 一.Bridged(桥接模式) 桥接模式相当于虚拟机和主机在同一个真实网段,VMWare充当一个集线器功能(一根网线连到主机相连的路由器上),所以如果电脑换了内网,静态分配的ip要更改.图如下: 二.NAT(网络地址转换模式) NAT模式
-
python神经网络Keras构建CNN网络训练
目录 Keras中构建CNN的重要函数 1.Conv2D 2.MaxPooling2D 3.Flatten 全部代码 利用Keras构建完普通BP神经网络后,还要会构建CNN Keras中构建CNN的重要函数 1.Conv2D Conv2D用于在CNN中构建卷积层,在使用它之前需要在库函数处import它. from keras.layers import Conv2D 在实际使用时,需要用到几个参数. Conv2D( nb_filter = 32, nb_row = 5, nb_col = 5
-
VirtualBox下Centos6.8网络配置教程
win10环境下,VirtualBox和Centos6.8已经按照完毕,下面配置Centos6.8网络. 1.设置VirtualBox为桥接模式,具体的有三种联网方法,我们参考http://www.cnblogs.com/jasmine-Jobs/p/5928218.html 2.桥接模式使得宿主机和虚拟机在同一个网段内工作,ipconfig查看宿主机的ip,子网掩码,网关,我的宿主机连接的是无线网. 3.ifconfig 查看虚拟的的IP地址 4.修改网络配置 把ip地址设置为静态地址,子网掩
-
vmware中CentOS7网络设置教程详解
为了能够使用XShell来管理我们安装好的CentOS7系统,所以我们要先设置CentOS7的网络使其能够联网. 1.选择vmware的编辑,然后点击虚拟网络编辑器 2.点击更改设置(需要有管理员权限) 3.选择VMnet0为桥接模式,选择自动或者网卡 4.打开"网络和共享中心"选择"VMware Virtual Ethernet Adapter for VMnet8"网卡,右键选择属性,勾选VMware Bridge Protocol,同时设置ip为自动获取 5.
-
使用Python构建Hopfield网络的教程
热的东西显然会变凉.房间会会人沮丧地变得凌乱.几乎同样,消息会失真.逆转这些情况的短期策略分别是重新加热. 做卫生和使用 Hopfield 网络.本文向您介绍了三者中的最后一个,它是一个只需要特定的参数就可以消除噪声的算法.net.py 是一个特别简单的 Python 实现,将向您展示它的基本部分如何结合到一起,以及为何 Hopfield 网络有时可以自失真的图案中 重新得到原图案.尽管这个实现有局限性,不过仍然可以让您获得关于 Hopfield 网络的很多有益且有启发作用的经验. 您寻求的是什
-
网络克隆教程
网吧机器数量越来越多,游戏更新越来越快,我们对机器的系统和游戏必须经常更新才能客人的需要.现在也有各种游戏更新软件,但是我们在进行更新工作的时候,更新速度太不理想.利用整个分区克隆,还要拆机箱,太麻烦!那么,网络克隆成为不用拆机箱,只要按键盘就可以完成的更新方法. 一.网络克隆适用的环境: 网络克隆是利用网络多播的技术,实现一对多的数据更新.要运行网络克隆这一操作,必须具备一定的网络环境. 1.网络传输速度稳定:网络克隆利用数据广播的工作原理,因此要求网络传输速度一定要稳定. 2.网络克隆服务器