利用Python爬虫实现抢购某宝秒杀商品
目录
- 1、导入对应类库实现对浏览器的操作
- 2、用代码实现购物流程
- 2.1 访问某宝
- 2.2登录某宝
- 2.3 进入购物车
- 2.4 选中所有商品
- 2.5 对比时间,提交结算(重点)
前言:
某宝秒杀,用毫秒级的精准度来抢购!你还在为各种活动秒杀 抢不过别人而烦恼吗?接下来我们就来实现抢购某宝秒杀商品
项目环境:
- 操作系统:Windows 10
- 开发环境:python3.7
- IDE:Pycharm
- 自动化模块:Selenium
- 安装命令:pip install selenium
- 浏览器版本:Google Chrome 99.0.4844.51
- 浏览器驱动版本:ChromeDriver 99.0.4844.51
注意: 浏览器驱动版本与浏览器版本要一致!
某宝抢购流程分析:
- 1,登录网站
- 2,购物车选中抢购商品
- 3,结算购买
- 4,提交订单
关键:快速完成前面流程,当订单进入提交页面时,付款时间不影响抢购。
程序实现思路:
购物流程都是固定没有变化的,因此可以把购物流程步骤用代码编辑好交给selenium去自动执行。
项目结构:驱动直接复制放入项目根路径

1、导入对应类库实现对浏览器的操作
from selenium import webdriver import datetime import time #自动打开浏览器并且最大化窗口 driver = webdriver.Chrome() driver.maximize_window()
执行上述代码,浏览器会自动打开并显示如下,证明我们已经开始通过代码操控浏览器了。
2、用代码实现购物流程
2.1 访问某宝
driver.get('https://www.taobao.com')
2.2登录某宝

if driver.find_element_by_partial_link_text('亲,请登录'):
driver.find_element_by_partial_link_text('亲,请登录').click()
2.3 进入购物车
#跳转到购物车页面
driver.get('https://cart.taobao.com/cart.htm')
2.4 选中所有商品

#寻找全选选项并勾选
if driver.find_element_by_id("J_SelectAll1"):
driver.find_element_by_id("J_SelectAll1").click()
2.5 对比时间,提交结算(重点)
def buy(buy_time): #buy_time 购买时间
while True:
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
print('当前时间:%s'%now)
#判断是否到达抢购时间
if now>buy_time:
try:
driver.find_element_by_partial_link_text('结 算').click()
except:
pass
#对比时间,循环提交订单
while True:
try:
if driver.find_element_by_link_text('提交订单'):
driver.find_element_by_link_text('提交订单').click()
print(f"抢购成功,请尽快付款")
except:
print(f"再次尝试提交订单")
time.sleep(0.01)
这样就可以通过设定的段时间去定时定点抢购商品啦!
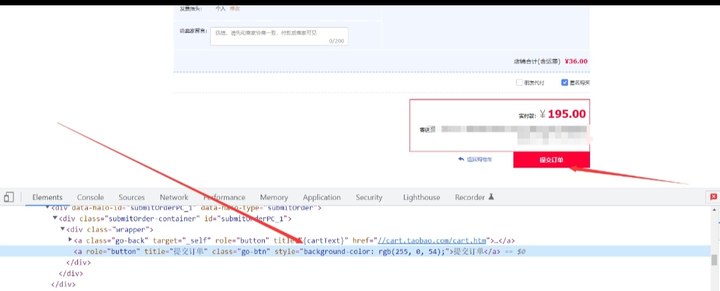
print(f"再次尝试提交订单") time.sleep(0.01) **这样就可以通过设定的段时间去定时定点抢购商品啦!**
到此这篇关于利用Python爬虫实现抢购某宝秒杀商品的文章就介绍到这了,更多相关Python 秒杀商品内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python淘宝抢购脚本程序实现
目录 一.官网下载火狐浏览器 二.下载geckodriver,并解压到火狐浏览器文件夹根目录 三.添加火狐浏览器根目录到系统环境变量 四.下载并安装python3及pycharm开发工具 五.进入淘宝 六.使用Pycharm运行脚本,新建python文件,将代码复制到文件中,并运行. 总结 最近自己在抢冰墩墩钥匙扣,发现一秒瞬间就没了.于是自己网上学习了一下,写了一个抢购脚本.亲测可用. 具体使用步骤如下: 一.官网下载火狐浏览器 二.下载geckodriver,并解压到火狐浏览器文件夹根目录
-
python+selenium小米商城红米K40手机自动抢购的示例代码
使用环境 1.python3 2.selenium selenium使用简述 1.安装selenium pip install selenium 2.安装ChromeDriver 下载地址:http://chromedriver.storage.googleapis.com/index.html 注意:下载的ChromeDriver需要与Chrome版本一致. 1)Chrome版本查看: 2)ChromeDriver对应版本下载: 3)ChromeDriver下载后解压到任意文件夹,建议可以放到
-
python抢购软件/插件/脚本附完整源码
距上篇关于淘宝抢购源码的文章已经过去五个月了,五个月来我通过不停的学习,掌握了更深层的抢购技术及原理,而上篇文章中我仅分享了关于加入购物车的商品的抢购源码,且有部分不足. 博主不提供任何服务器端程序,也不提供任何收费抢购软件.该文章仅作为学习selenium框架及GUI开发的一个示例代码.该思路可运用到其他任何网站,京东,天猫,淘宝均可使用,且不属于外挂或者软件之类,只属于一个自动化点击工具,如有侵犯到任何公司的合法权益,请私信联系,会第一时间将相关代码给予删除. 本篇文章我将附上完整源码,及其
-
自制Python淘宝秒杀抢购脚本双十一百分百中
大家好,我是不学前端的前端程序员, 事情是这个样子的,前几天不是双十一预购秒杀嘛 由于我女朋友比较笨,手速比较慢,就一直抢不到,她没抢到特价商品就不开心, 她不开心,我也就不能跟着开心,就别提看6号的全球总决赛了 为了解决这个问题,就决定写一个自动定时抢购的脚本. 第一步: 首先我的思路很简单,就是让"程序"帮我们自动打开浏览器,进入淘宝,然后到购物车等待抢购时间,自动购买并支付. 第二步: 导入模块,我们需要一个时间模块,抢购的时间,还有一个Python的自动化操作. 代码如下: i
-
Python实现抢购IPhone手机
要买IPhone7主要有三个途径吧,一是官网下单:二是官网预约,直营店取货:三是第三方渠道.第一个渠道需要等3-4周,而且是直接快递过来,方便是方便,缺点主要是对物流不放心和怕遇到瑕疵机器退换货麻烦,优点是可以信用卡12期免息付款.第三个渠道加价且不放心.预约去直营店取机就是唯一选择. 预约是唯一的问题,官网上的预约号是不定时发放,基本刚出来几分钟就被抢走.编程改变世界,于是我用python写了一个查询脚本,在苹果放票的第一时间通过蜂鸣器通知抢预约. python代码如下 #!/usr/bin/
-
Python实现淘宝秒杀聚划算抢购自动提醒源码
说明 本实例能够监控聚划算的抢购按钮,在聚划算整点聚的时间到达时发出提醒(音频文件自己定义位置)并自动弹开页面(URL自己定义). 同时还可以通过命令行参数自定义刷新间隔时间(默认0.1s)和监控持续时间(默认1800s). 源码 # encoding: utf-8 ''''' @author: Techzero @email: techzero@163.com @time: 2014-5-18 下午5:06:29 ''' import cStringIO import getopt impor
-
Python制作脚本帮女朋友抢购清空购物车
目录 爬取目标 工具使用 需求分析 项目思路解析 selenium安装配置 项目解析 简易源码分享 大家好,我是辣条. 辣条的一个朋友最近跟我诉苦:女朋友沉迷淘宝抢购无法自拔,大晚上不睡觉都在定时抢购,真是败家. 都是好朋友辣条肯定帮忙,不就是定时抢购,定时清空购物车嘛,这叫安排. 爬取目标 网站:淘宝 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:selenuim 需求分析 我们的目标是秒杀淘宝的订单,这里面有几个关键点,首先需要登录淘宝,
-
Python 实现毫秒级淘宝抢购脚本的示例代码
本篇文章主要介绍了Python 通过selenium实现毫秒级自动抢购的示例代码,通过扫码登录即可自动完成一系列操作,抢购时间精确至毫秒,可抢加购物车等待时间结算的,也可以抢聚划算的商品. 博主不提供任何服务器端程序,也不提供任何收费抢购软件.该文章仅作为学习selenium框架的一个示例代码.该思路可运用到其他任何网站,京东,天猫,淘宝均可使用,且不属于外挂或者软件之类,只属于一个自动化点击工具,如有侵犯到任何公司的合法权益,会第一时间将相关代码给予删除. 直接上源码: # !/usr/bin
-
Python抢购脚本的编写方法
想买mate40,但总是抢不到,所以想试着能不能写个脚本代码. 第一步:把想要抢购的商品加进购物车,注意:脚本是对购物车内全部商品进行下单操作,所以不够买的商品最好先从购物车内删除. 第二步:写好Python脚本,在抢购之前运行,并设置好抢购时间. Python脚本实现 安装Python.我安装的是anaconda 安装webdriver扩展.它是Selenium模块的一部分.Selenium是一个用于Web应用程序测试的工具,用于测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.
-
利用Python爬虫实现抢购某宝秒杀商品
目录 1.导入对应类库实现对浏览器的操作 2.用代码实现购物流程 2.1 访问某宝 2.2登录某宝 2.3 进入购物车 2.4 选中所有商品 2.5 对比时间,提交结算(重点) 前言: 某宝秒杀,用毫秒级的精准度来抢购!你还在为各种活动秒杀 抢不过别人而烦恼吗?接下来我们就来实现抢购某宝秒杀商品 项目环境: 操作系统:Windows 10 开发环境:python3.7 IDE:Pycharm 自动化模块:Selenium 安装命令:pip install selenium 浏览器版本:Googl
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬虫爬取淘宝商品比价(附淘宝反爬虫机制解决小办法)
因为评论有很多人说爬取不到,我强调几点 kv的格式应该是这样的: kv = {'cookie':'你复制的一长串cookie','user-agent':'Mozilla/5.0'} 注意都应该用 '' ,然后还有个英文的 逗号, kv写完要在后面的代码中添加 r = requests.get(url, headers=kv,timeout=30) 自己得先登录自己的淘宝账号才有自己登陆的cookie呀,没登录cookie当然没用 以下原博 本人是python新手,目前在看中国大学MOOC的嵩天
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
利用Python爬虫给孩子起个好名字
前言 相信每位家长都有所体会,因为要在孩子出生后两周内起个名字(需要办理出生证明了),估计很多人都像我一样,刚开始是很慌乱的,虽然感觉汉字非常的多随便找个字做名字都行,后来才发现真不是随便的事情,怎么想都发现不合适,于是到处翻词典.网上搜.翻唐诗宋词.诗经.甚至武侠小说,然而想了很久得到的名字,往往却受到家属的意见和反对,比如不顺口.和亲戚重名重音等问题,这样就陷入了重复寻找和否定的循环,越来越混乱. 于是我们再次回到网上各种搜索,找到很多网上给出的"男宝宝好听的名字大全"之类的文章,
-
Python淘宝或京东等秒杀抢购脚本实现(秒杀脚本)
目录 一.环境 二.安装 1.ChromeDriver安装 2.Seleuinm安装 3.淘宝秒杀脚本 4.京东秒杀脚本 总结 我们的目标是秒杀淘宝或京东等的订单,这里面有几个关键点,首先需要登录淘宝或京东,其次你需要准备好订单,最后要在指定时间快速提交订单. 这里就要用到一个爬虫利器Selenium,Selenium是一个用于Web应用程序测试的工具,Selenium可以直接运行在浏览器中,通过后台控制操作浏览器,完成购买操作,利用它我们可以驱动浏览器执行特定的动作,抢购脚本就是通过Selen
-
备战618!用Python脚本帮你实现淘宝秒杀
selenium 安装与 chromedriver安装 我们前文提到,Python脚本中使用了selenium库,而selenium又通过chromedriver来控制浏览器的鼠标点击等操作.所以,我们的第一步,是正确的安装与配置selenium以及chromedriver. selenium的安装很简单,与其他Python三方库一样,我们直接用pip安装. pip install selenium chromedriver的安装,首先,chromedriver的版本很关键,我们需要选择的chr
-
python爬虫获取淘宝天猫商品详细参数
首先我是从淘宝进去,爬取了按销量排序的所有(100页)女装的列表信息按综合.销量分别爬取淘宝女装列表信息,然后导出前100商品的 link,爬取其详细信息.这些商品有淘宝的,也有天猫的,这两个平台有些区别,处理的时候要注意.比如,有的说"面料".有的说"材质成分",其实是一个意思,等等.可以取不同的链接做一下测试. import re from collections import OrderedDict from bs4 import BeautifulSoup