Python爬虫必备技巧详细总结
自定义函数
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&word=' + company
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.news-title_1YtI1 a')
for i in title:
print(i.text)
# 批量调用函数
companies = ['腾讯', '阿里巴巴', '百度集团']
for i in companies:
baidu(i)
批量输出多个搜索结果的标题
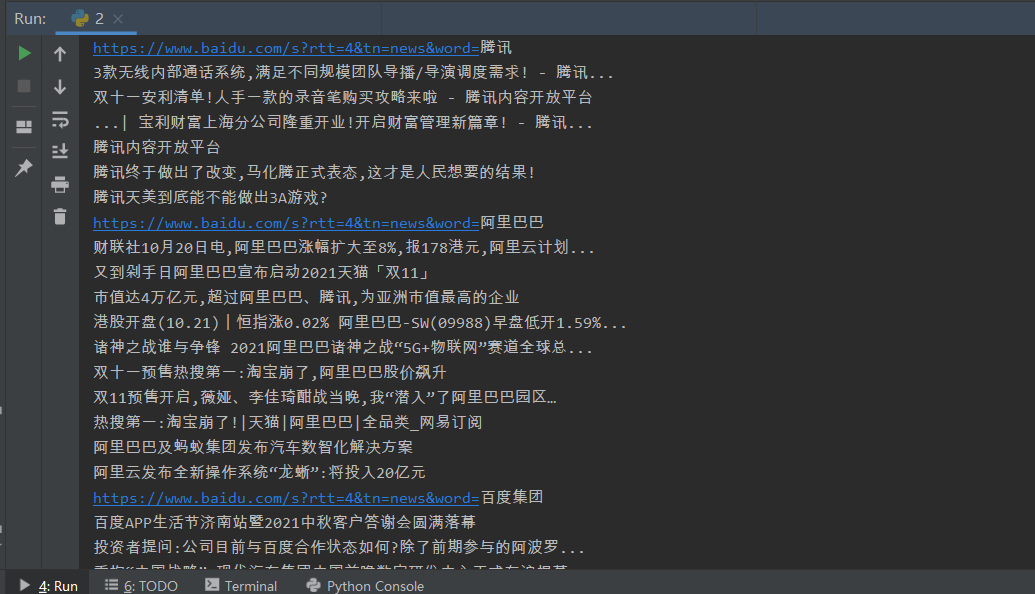
结果保存为文本文件
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&word=' + company
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.news-title_1YtI1 a')
fl=open('test.text','a', encoding='utf-8')
for i in title:
fl.write(i.text + '\n')
# 批量调用函数
companies = ['腾讯', '阿里巴巴', '百度集团']
for i in companies:
baidu(i)
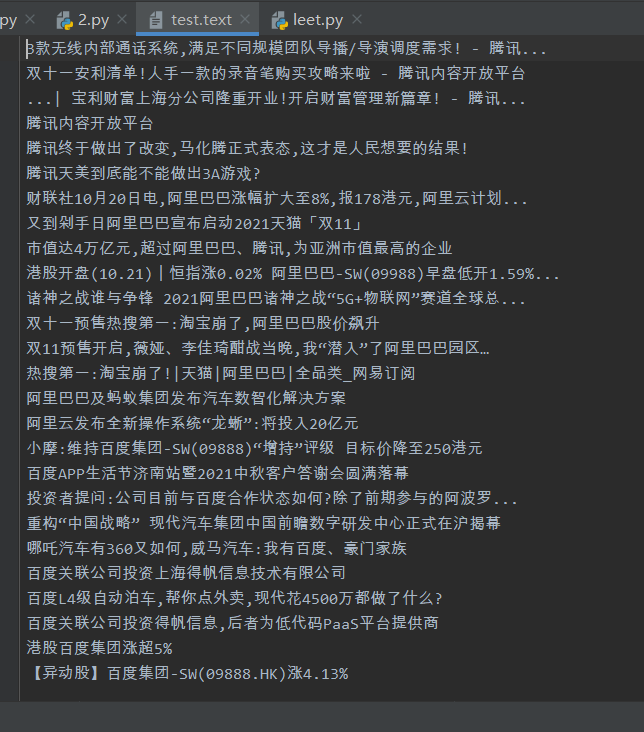
写入代码
fl=open('test.text','a', encoding='utf-8')
for i in title:
fl.write(i.text + '\n')
异常处理
for i in companies:
try:
baidu(i)
print('运行成功')
except:
print('运行失败')
写在循环中 不会让程序停止运行 而会输出运行失败
休眠时间
import time
for i in companies:
try:
baidu(i)
print('运行成功')
except:
print('运行失败')
time.sleep(5)
time.sleep(5)
括号里的单位是秒
放在什么位置 则在什么位置休眠(暂停)
爬取多页内容
百度搜索腾讯
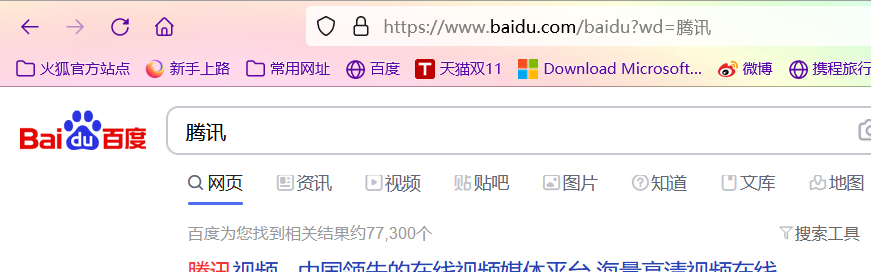
切换到第二页

去掉多多余的
https://www.baidu.com/s?wd=腾讯&pn=10
分析出
https://www.baidu.com/s?wd=腾讯&pn=0 为第一页
https://www.baidu.com/s?wd=腾讯&pn=10 为第二页
https://www.baidu.com/s?wd=腾讯&pn=20 为第三页
https://www.baidu.com/s?wd=腾讯&pn=30 为第四页
..........
代码
from bs4 import BeautifulSoup
import time
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(c):
url = 'https://www.baidu.com/s?wd=腾讯&pn=' + str(c)+'0'
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.t a')
for i in title:
print(i.text)
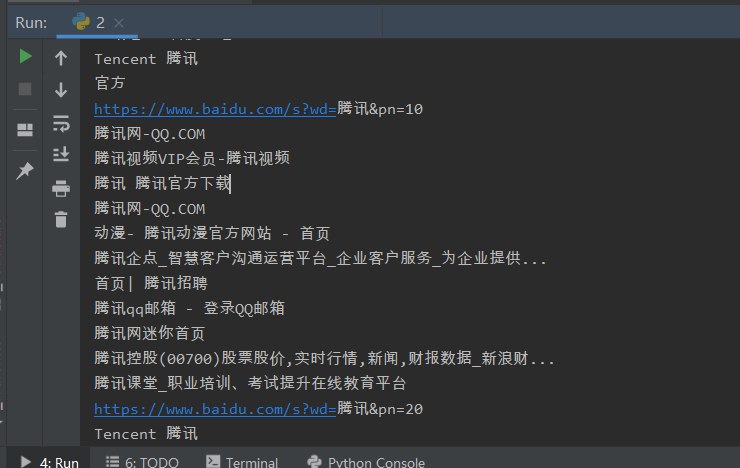
for i in range(10):
baidu(i)
time.sleep(2)
到此这篇关于Python爬虫必备技巧详细总结的文章就介绍到这了,更多相关Python 爬虫技巧内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫设置代理IP的方法(爬虫技巧)
在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术,高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP. (一)配置环境 安装requests库 安装bs4库 安装lxml库 (二)代码展示 # IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/ # 仅仅爬取首页IP地址就足够一般使用 from bs4 import BeautifulSoup
-
一些常用的Python爬虫技巧汇总
Python爬虫:一些常用的爬虫技巧总结 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情. 1.基本抓取网页 get方法 import urllib2 url "http://www.baidu.com" respons = urllib2.urlopen(url) print response.read() post方法 import urllib import urllib2 url = "http://abcde.com" form = {
-
Python常用的爬虫技巧总结
用python也差不多一年多了,python应用最多的场景还是web快速开发.爬虫.自动化运维:写过简单网站.写过自动发帖脚本.写过收发邮件脚本.写过简单验证码识别脚本. 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情. 1.基本抓取网页 get方法 import urllib2 url = "http://www.baidu.com" response = urllib2.urlopen(url) print response.read() post方法 impo
-

Python爬虫必备技巧详细总结
自定义函数 import requests from bs4 import BeautifulSoup headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'} def baidu(company): url = 'https://www.baidu.com/s?rtt=4&tn=news&word=' + company print(url
-
Python爬虫必备之XPath解析库
一.简介 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上. Xpath解析库介绍:数据解析的过程中使用过正则表达式, 但正则表达式想要进准匹配难度较高, 一旦正则表达式书写错误, 匹配的数据也会出错. 网页由三部分组成: HTML, Css, JavaScript, HTML页面标签存在层级关系, 即DOM树,
-
Python爬虫必备之Xpath简介及实例讲解
目录 前言 一.Xpath简介 二.Xpath语法规则 语法规则 标签定位 属性定位 索引定位 取文本内容 三.语法规则练习 总结 前言 网上已经有很多大佬发过Xpath,而且讲的都很好,我是因为刚开始学习网络爬虫,对这些基础重要知识不太了解,所以写一下来加深印象,本篇文章只是简单介绍一下Xpath及使用,总体来说比较基础. 一.Xpath简介 XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言. Xpath以XML为基础,提供用户
-
Python爬虫小技巧之伪造随机的User-Agent
前言 不管是做开发还是做过网站的朋友们,应该对于User Agent一点都不陌生,User Agent 中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本.CPU 类型.浏览器及版本.浏览器渲染引擎.浏览器语言.浏览器插件等 在Python爬虫的过程中经常要模拟UserAgent, 因此自动生成UserAgent十分有用 通过UA来判断不同的设备或者浏览器是开发者最常用的方式方法,这个也是对于Python反爬的一种策略,但是有盾就有矛啊 写好爬虫的原则
-
ChatGPT 帮我自动编写 Python 爬虫脚本的详细过程
目录 1.爬取知乎上的专栏文章 2. 爬取京东某商品的评论 3.继续更多的测试 都知道最近ChatGPT聊天机器人爆火,我也想方设法注册了账号,据说后面要收费了. ChatGPT是一种基于大语言模型的生成式AI,换句话说它可以自动生成类似人类语言的文本,把梳理好的有逻辑的答案呈现在你面前,这完全不同于传统搜索工具. ChatGPT不光可以回答人文.科学.情感等传统问题,还可以写代码.改bug,程序员可就急了,简直是在抢饭碗,所以网上出现各种ChatGPT让你失业的焦虑言论. 俗话说“百闻不如一见
-
python爬虫开发之urllib模块详细使用方法与实例全解
爬虫所需要的功能,基本上在urllib中都能找到,学习这个标准库,可以更加深入的理解后面更加便利的requests库. 首先 在Pytho2.x中使用import urllib2---对应的,在Python3.x中会使用import urllib.request,urllib.error 在Pytho2.x中使用import urllib---对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse 在Pytho2.x中使
-
python爬虫开发之selenium模块详细使用方法与实例全解
python爬虫模块selenium简介 selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题. 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 一.声明浏览器对象 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入 from selenium import webdriver #webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里
-
python爬虫开发之PyQuery模块详细使用方法与实例全解
python爬虫模块PyQuery简介 PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现.语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了. 官网地址:http://pyquery.readthedocs.io/en/latest/ jQuery参考文档: http://jquery.cuishifeng.cn/ P
-
Python爬虫防封ip的一些技巧
在编写爬虫爬取数据的时候,因为很多网站都有反爬虫措施,所以很容易被封IP,就不能继续爬了.在爬取大数据量的数据时更是瑟瑟发抖,时刻担心着下一秒IP可能就被封了. 本文就如何解决这个问题总结出一些应对措施,这些措施可以单独使用,也可以同时使用,效果更好. 伪造User-Agent 在请求头中把User-Agent设置成浏览器中的User-Agent,来伪造浏览器访问.比如: headers ={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleW
-
Python必备技巧之字符数据操作详解
目录 字符串操作 字符串 + 运算符 字符串 * 运算符 字符串 in 运算符 内置字符串函数 字符串索引 字符串切片 字符串切片中的步幅 将变量插入字符串 修改字符串 内置字符串方法 bytes对象 定义文字bytes对象 bytes使用内置bytes()函数定义对象 bytes对象操作,操作参考字符串. bytearray对象,Python 支持的另一种二进制序列类型 字符串操作 字符串 + 运算符 +运算符用于连接字符串,返回一个由连接在一起的操作数组成的字符串. >>> s =