PostgreSQL 中的postgres_fdw扩展详解
通过postgres_fdw 扩展,访问远程数据库表
一、环境准备
虚拟机(node107):centos7、PostgreSQL10
远程服务器(百度云服务BBC): centos7、PostgreSQL10
在本地虚拟机上访问远程服务器的数据表。
二、配置连接
(1)创建扩展: 在本地107这个节点上创建扩展。
[root@107 ~]# su postgre su: user postgre does not exist [root@107 ~]# su postgres bash-4.2$ psql mydb postgres could not change directory to "/root": 权限不够 psql (10.7) Type "help" for help. mydb=# CREATE EXTENSION postgres_fdw; CREATE EXTENSION
如果是普通用户使用 ·postgres_fdw 需要单独授权
grant usage on foreign data wrapper postgres_fdw to 用户名
(2) 创建 foreign server 外部服务器,外部服务是指连接外部数据源的连接信息
mydb=# create server fs_postgres_bbc foreign data wrapper postgres_fdw options(host '182.61.136.109',port '5432',dbname 'technology'); mydb=#
定义名称为 fs_postgres_bbc的外部服务,options 设置远程PostgreSQL数据源连接选项,通常设置主机名、端口、数据库名称。
(3)需要给外部服务创建映射用户
mydb=# create user mapping for postgres server fs_postgres_bbc options(user 'postgres',password 'password'); CREATE USER MAPPING mydb=#
for 后面接的是 node107 的数据库用户,options 里接的是远程PostgreSQL数据库的用户和密码。password 注意修改成自己的
其实想访问远程数据库,无非就是知道连接信息。包括host、port、dbname、user、password
(4)BBC上准备数据。
technology=# select * from public.customers where id < 5; id | name ----+------- 1 | name1 2 | name2 3 | name3 4 | name4 (4 rows) technology=# -- schemaname = public
(5) 在node107上创建外部表:
mydb=# create foreign table ft_customers
(
id int4 primary key ,
name varchar(200)
) server fs_postgres_bbc options (schema_name 'public',table_name 'customers');
错误: 外部表上不支持主键约束
第1行create foreign table ft_customers (id int4 primary key , nam...
^
mydb=#
可以看见,外部表不支持主键约束。想想也是合理
mydb=# create foreign table ft_customers ( id int4 , name varchar(200) ) server fs_postgres_bbc options (schema_name 'public',table_name 'customers'); CREATE FOREIGN TABLE mydb=#
options 选项中: 需要指定外部表的schema和表名
(6)在node107上去访问远程BBC的数据
mydb=# select * from ft_customers where id < 5; id | name ----+------- 1 | name1 2 | name2 3 | name3 4 | name4 (4 rows) mydb=#
可以看见在mydb上能够访问远程数据库上 的数据了。
如果出现报错,如报pg_hba.conf 文件没有访问策略,在需要在对修改配置文件。
(7)本地数据库表与远程数据库表进行进行关联查询
create table orders ( id int PRIMARY KEY, customerid int ); INSERT INTO orders(id,customerid) VALUES(1,1),(2,2); SELECT * FROM orders; -- 和外部表关联查询。 mydb=# SELECT o.*,c.* mydb-# FROM orders o mydb-# INNER JOIN ft_customers c ON o.customerid = c.id mydb-# WHERE c.id < 10000; id | customerid | id | name ----+------------+----+------- 1 | 1 | 1 | name1 2 | 2 | 2 | name2 (2 rows) mydb=#

三、postgres_fdw 外部表支持写操作
postgres_fdw 外部表一开始只支持读,PostgreSQL9.3 版本开始支持可写。
写操作需要保证:1. 映射的用户对有写权限;2. 版本需要9.3 以上。
在node107结点上线删除数据,后再插入数据、最后更新。并查看远程BBC数据库表情况
mydb=# select count(*) from ft_customers; count ---------- 10000000 (1 row) mydb=# delete from ft_customers where id = 9999999; DELETE 1 mydb=# select count(*) from ft_customers; count --------- 9999999 (1 row) mydb=# insert into ft_customers values(9999999,'name1'); INSERT 0 1 mydb=# select count(*) from ft_customers; count ---------- 10000000 (1 row) mydb=# select * from ft_customers where id = 9999999; id | name ---------+------- 9999999 | name1 (1 row) mydb=# update ft_customers set name = 'name999' where id = 9999999; UPDATE 1 mydb=# select * from ft_customers where id = 9999999; id | name ---------+--------- 9999999 | name999 (1 row) mydb=#
可以看见对ft_customers 进行增删改查。
四、postgres_fdw支持聚合函数下推
PostgreSQL10 增强了postgres_fdw 扩展模块的特性,可以将聚合、关联操作下推到远程PostgreSQL数据库进行,而之前的版本是将外部表相应的远程数据全部取到本地再做聚合,10版本这个心特性大幅度减少了从远程传输到本地库的数据量。提升了postgres_fdw外部表上聚合查询的性能。
mydb=# EXPLAIN(ANALYZE on,VERBOSE on) select id,count(*) from ft_customers where id < 100 group by id;
QUERY PLAN
----------------------------------------------------------------------------------------------------
Foreign Scan (cost=104.88..157.41 rows=199 width=12) (actual time=16.725..16.735 rows=99 loops=1)
Output: id, (count(*))
Relations: Aggregate on (public.ft_customers)
Remote SQL: SELECT id, count(*) FROM public.customers WHERE ((id < 100)) GROUP BY 1
Planning time: 0.247 ms
Execution time: 249.410 ms
(6 rows)
mydb=#
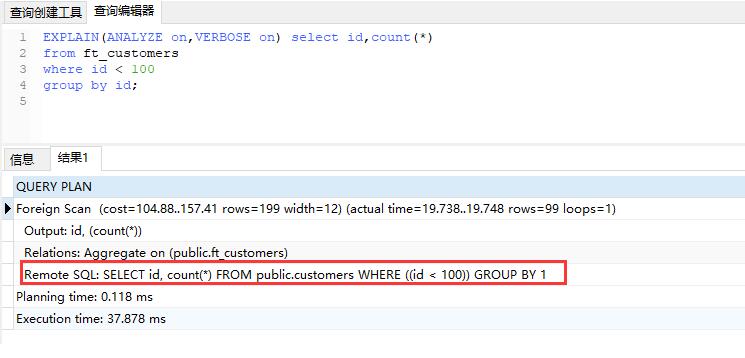
remote sql: 远程库上执行的SQL,此SQL为聚合查询的SQL。聚合是在远程上执行的。
如果在PostgreSQL9.6 测试,则需要从远程传输到本地才可以。
小结
物理表和外部表不能同名,因为pg_class的对象名称唯一键的缘故
外部表不会存储数据。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

PostgreSQL的B-tree索引用法详解
结构 B-tree索引适合用于存储排序的数据.对于这种数据类型需要定义大于.大于等于.小于.小于等于操作符. 通常情况下,B-tree的索引记录存储在数据页中.叶子页中的记录包含索引数据(keys)以及指向heap tuple记录(即表的行记录TIDs)的指针.内部页中的记录包含指向索引子页的指针和子页中最小值. B-tree有几点重要的特性: 1.B-tree是平衡树,即每个叶子页到root页中间有相同个数的内部页.因此查询任何一个值的时间是相同的. 2.B-tree中一个节点有多个分支,即每
-
PostgreSQL copy 命令教程详解
报文介绍PostgreSQL copy 命令,通过示例展示把查询结果导出到csv文件,导入数据文件至postgresql. 1. copy命令介绍 copy命令用于在postgreSql表和标准文件系统直接传输数据.copy命令让PostgreSQL 服务器直接读写文件,因此文件必须让PostgreSQL 用户能够访问到.该命令使用的文件是数据库服务器直接读写的文件,不是客户端应用的文件,因此必须位于服务器本地或被直接访问的文件,而不是客户端位置. copy to 命令拷贝表内容至文件,也可以拷
-
PostgreSQL查看正在执行的任务并强制结束的操作方法
查看任务sql语句: SELECT procpid, start, now() - start AS lap, current_query FROM (SELECT backendid, pg_stat_get_backend_pid(S.backendid) AS procpid, pg_stat_get_backend_activity_start(S.backendid) AS start, pg_stat_get_backend_activity(S.backendid) AS curr
-
Postgresql 如何选择正确的关闭模式
停止数据库的命令: pg_ctl stop -D $PGDATA [-m shutdown-mode] shutdown-mode有如下几种模式: 1. smart: 等所有的连接中止后,关闭数据库.如果客户端连接不终止, 则无法关闭数据库. 开启一个空会话: [root@localhost ~]# su - postgres [postgres@localhost ~]$ psql psql (9.4.4) Type "help" for help. postgres=# 用smar
-
Postgresql在mybatis中报错:操作符不存在:character varying == unknown的问题
错误: 操作符不存在: character varying == unknown , Hint: 没有匹配指定名称和参数类型的操作符. 您也许需要增加明确的类型转换. 在Mybatis条件查询时,动态SQL的一个错误,sql写的也不多,没仔细看所以一直找不到错误,网上也找不到类似的错误,结果是低级错误... <div> <form:select path="finished" class="col-xs-12 form-control m-b"&g
-
PostgreSQL的外部数据封装器fdw用法
数据封装器fdw(Foreign Data Wrappers)在PostgreSQL中相当于oracle中的dblink,可以很方便的操作其他数据库中的数据. 场景,在本地的test库中通过外部数据封装器fdw访问本地的testdb中的t2表 本地库test用户u1,远程库test用户dbuser 版本: postgres=# select version(); version -----------------------------------------------------------
-
postgresql 如何关闭自动提交
postgresql中默认是自动提交的 查看是否是自动提交: postgres=# \echo :AUTOCOMMIT on 关闭自动提交: postgres=# \set AUTOCOMMIT off postgres=# \echo :AUTOCOMMIT off 另一种方式就在会话开始的时候以begin开始相当于关闭了自动提交,以end或者commit结束就可以了 补充:pg(hgdb)默认事务自动提交 默认情况下,AUTOCOMMIT(自动提交)是开着的,也就是说任何一个SQL语句执行完
-
PostgreSQL 中的postgres_fdw扩展详解
通过postgres_fdw 扩展,访问远程数据库表 一.环境准备 虚拟机(node107):centos7.PostgreSQL10 远程服务器(百度云服务BBC): centos7.PostgreSQL10 在本地虚拟机上访问远程服务器的数据表. 二.配置连接 (1)创建扩展: 在本地107这个节点上创建扩展. [root@107 ~]# su postgre su: user postgre does not exist [root@107 ~]# su postgres bash-4.2
-
postgresql 中的序列nextval详解
一.postgresql中的序列 1.1 场景需求 需要向下图一样,需要对产品编码编码设置一个序列.编码规则 SKU + 序列号: 1.2 序列 序列是基于bigint算法的,因此范围是不能超过一个八字节 整数的范围(-9223372036854775808 到 9223372036854775807). 由于nextval和setval调用绝不会回滚, 如果需要序数的"无间隙"分配,则不能使用序列对象.可以 通过在一个只包含一个计数器的表上使用排他锁来构建无间隙的分配, 但是这种方案
-
PostgreSQL中的collations用法详解
与Oracle相比,PostgreSQL对collation的支持依赖于操作系统. 以下是基于Centos7.5的测试结果 $ env | grep LC $ env | grep LANG LANG=en_US.UTF-8 使用initdb初始化集群的时候,就会使用这些操作系统的配置. postgres=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------
-
PyTorch中clone()、detach()及相关扩展详解
clone() 与 detach() 对比 Torch 为了提高速度,向量或是矩阵的赋值是指向同一内存的,这不同于 Matlab.如果需要保存旧的tensor即需要开辟新的存储地址而不是引用,可以用 clone() 进行深拷贝, 首先我们来打印出来clone()操作后的数据类型定义变化: (1). 简单打印类型 import torch a = torch.tensor(1.0, requires_grad=True) b = a.clone() c = a.detach() a.data *=
-
php 中的closure用法详解
Closure,匿名函数,是php5.3的时候引入的,又称为Anonymous functions.字面意思也就是没有定义名字的函数.比如以下代码(文件名是do.php) <?php function A() { return 100; }; function B(Closure $callback) { return $callback(); } $a = B(A()); print_r($a);//输出:Fatal error: Uncaught TypeError: Argument 1
-
JavaScript知识点总结(十一)之js中的Object类详解
JavaScript中的Object对象,是JS中所有对象的基类,也就是说JS中的所有对象都是由Object对象衍生的.Object对象主要用于将任意数据封装成对象形式. 一.Object类介绍 Object类是所有JavaScript类的基类(父类),提供了一种创建自定义对象的简单方式,不再需要程序员定义构造函数. 二.Object类主要属性 1.constructor:对象的构造函数. 2.prototype:获得类的prototype对象,static性质. 三.Object类主要方法 1
-
java中变量和常量详解
变量和常量 在程序中存在大量的数据来代表程序的状态,其中有些数据在程序的运行过程中值会发生改变,有些数据在程序运行过程中值不能发生改变,这些数据在程序中分别被叫做变量和常量. 在实际的程序中,可以根据数据在程序运行中是否发生改变,来选择应该是使用变量代表还是常量代表. 变量 变量代表程序的状态.程序通过改变变量的值来改变整个程序的状态,或者说得更大一些,也就是实现程序的功能逻辑. 为了方便的引用变量的值,在程序中需要为变量设定一个名称,这就是变量名.例如在2D游戏程序中,需要代表人物的位置,则需
-
Spring生命周期回调与容器扩展详解
本篇主要总结下Spring容器在初始化实例前后,提供的一些回调方法和可扩展点.利用这些方法和扩展点,可以实现在Spring初始化实例前后做一些特殊逻辑处理. 下面主要介绍: 类级别的生命周期初始化回调方法init-method配置.InitializingBean接口和PostConstruct注解 容器级别的扩展BeanPostProcessor接口和BeanFactoryPostProcessor接口 1.类级别生命周期回调 1.1init-method 参照:Springbeanxsdin
-
Java多线程中ReentrantLock与Condition详解
一.ReentrantLock类 1.1什么是reentrantlock java.util.concurrent.lock中的Lock框架是锁定的一个抽象,它允许把锁定的实现作为Java类,而不是作为语言的特性来实现.这就为Lock的多种实现留下了空间,各种实现可能有不同的调度算法.性能特性或者锁定语义.ReentrantLock类实现了Lock,它拥有与synchronized相同的并发性和内存语义,但是添加了类似锁投票.定时锁等候和可中断锁等候的一些特性.此外,它还提供了在激烈争用情况下更
-
JVM中的flag设置详解
本文研究的主要是JVM中的flag设置详解的相关内容,具体介绍如下. 一.堆大小设置 -Xmx3550m:设置JVM最大可用内存为3550M. -Xms3550m:设置JVM初始可用内存为3550M. -Xmn2g:设置年轻代大小为2G. -Xss128k:设置每个线程的堆栈大小为128K -XX:NewSize=4:设置年轻代大小为4 -XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与老年代(除去持久代)的比值为4,则年轻代与年老代所占比值为1:4,年轻代占整个