Python爬虫入门教程01之爬取豆瓣Top电影
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理
基本开发环境
- Python 3.6
- Pycharm
相关模块的使用
- requests
- parsel
- csv
安装Python并添加到环境变量,pip安装需要的相关模块即可。
爬虫基本思路
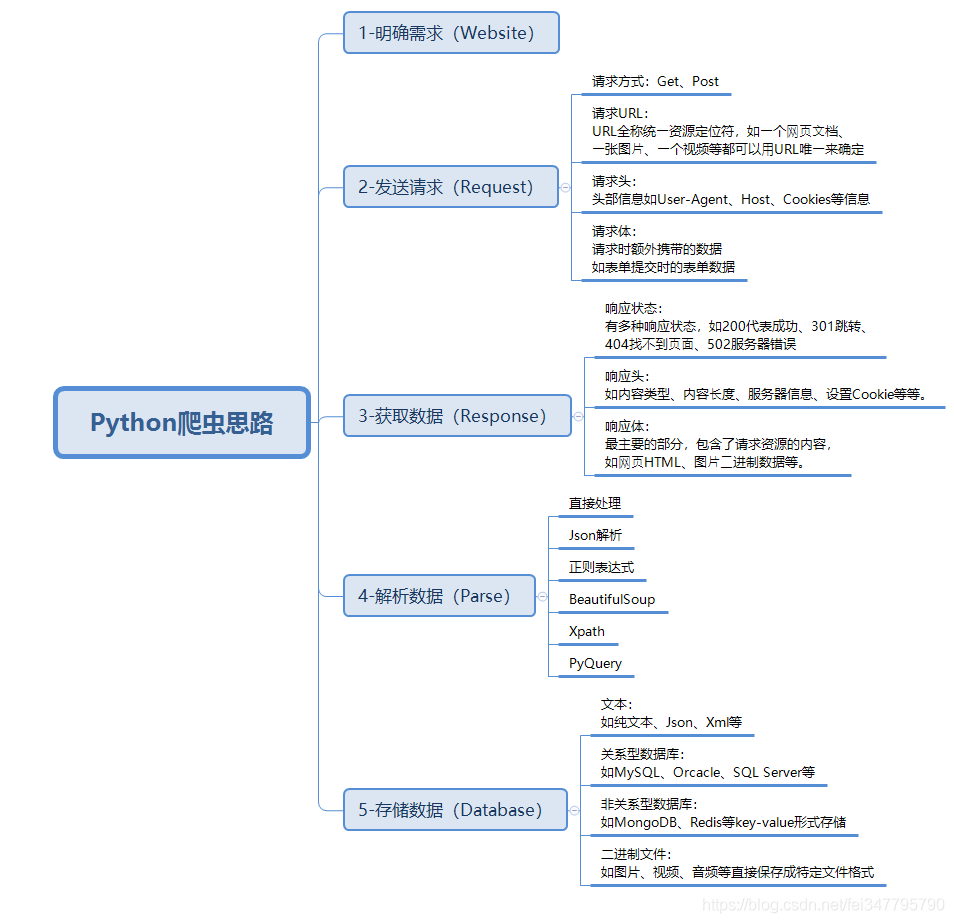
一、明确需求
爬取豆瓣Top250排行电影信息
- 电影名字
- 导演、主演
- 年份、国家、类型
- 评分、评价人数
- 电影简介
二、发送请求
Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模块就是requests。
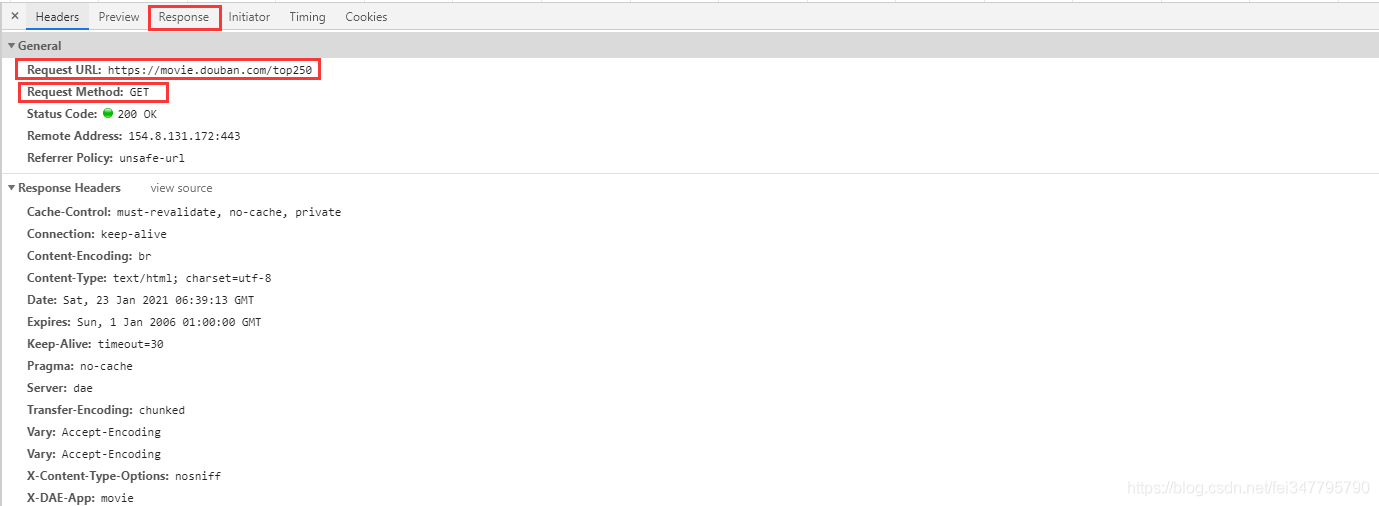
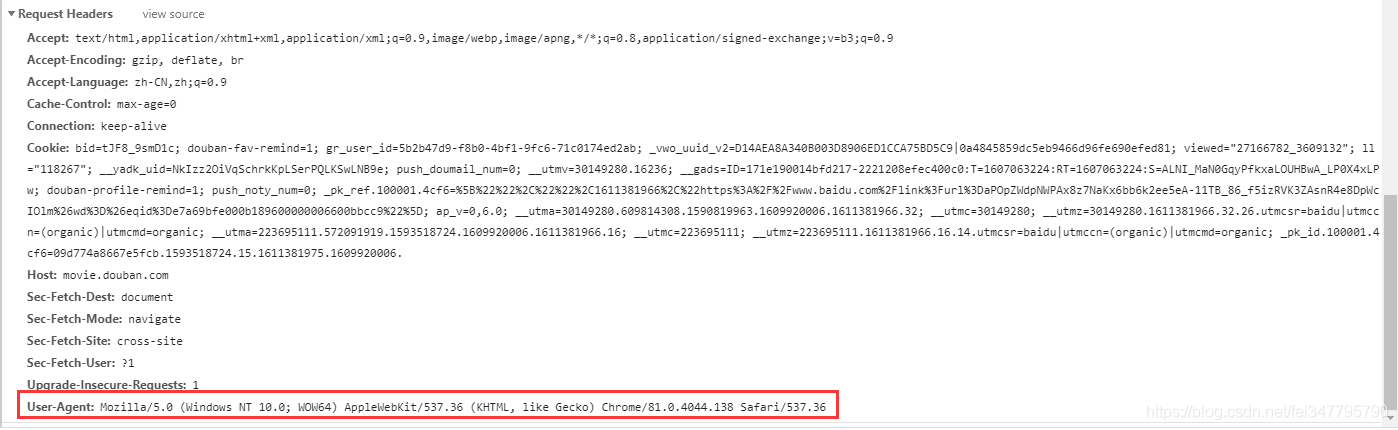
请求url地址,使用get请求,添加headers请求头,模拟浏览器请求,网页会给你返回response对象
# 模拟浏览器发送请求
import requests
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response)

200是状态码,表示请求成功
2xx (成功)
3xx (重定向)
4xx(请求错误)
5xx(服务器错误)
常见状态码
- 200 - 服务器成功返回网页,客户端请求已成功。
- 302 - 对象临时移动。服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 304 - 属于重定向。自上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
- 401 - 未授权。请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
- 404 - 未找到。服务器找不到请求的网页。
- 503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。
通常,这只是暂时状态。
三、获取数据
import requests
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
requests.get(url=url, headers=headers) 请求网页返回的是response对象
response.text: 获取网页文本数据
response.json: 获取网页json数据
这两个是用的最多的,当然还有其他的
apparent_encoding cookies history iter_lines ok close elapsed is_permanent_redirect json raise_for_status connection encoding is_redirect links raw content headers iter_content next reason url
四、解析数据
常用解析数据方法: 正则表达式、css选择器、xpath、lxml…
常用解析模块:bs4、parsel…
我们使用的是 parsel 无论是在之前的文章,还是说之后的爬虫系列文章,我都会使用 parsel 这个解析库,无它就是觉得它比bs4香。
parsel 是第三方模块,pip install parsel 安装即可
parsel 可以使用 css、xpath、re解析方法

所有的电影信息都包含在 li 标签当中。
# 把 response.text 文本数据转换成 selector 对象
selector = parsel.Selector(response.text)
# 获取所有li标签
lis = selector.css('.grid_view li')
# 遍历出每个li标签内容
for li in lis:
# 获取电影标题 hd 类属性 下面的 a 标签下面的 第一个span标签里面的文本数据 get()输出形式是 字符串获取一个 getall() 输出形式是列表获取所有
title = li.css('.hd a span:nth-child(1)::text').get() # get()输出形式是 字符串
movie_list = li.css('.bd p:nth-child(1)::text').getall() # getall() 输出形式是列表
star = movie_list[0].strip().replace('\xa0\xa0\xa0', '').replace('/...', '')
movie_info = movie_list[1].strip().split('\xa0/\xa0') # ['1994', '美国', '犯罪 剧情']
movie_time = movie_info[0] # 电影上映时间
movie_country = movie_info[1] # 哪个国家的电影
movie_type = movie_info[2] # 什么类型的电影
rating_num = li.css('.rating_num::text').get() # 电影评分
people = li.css('.star span:nth-child(4)::text').get() # 评价人数
summary = li.css('.inq::text').get() # 一句话概述
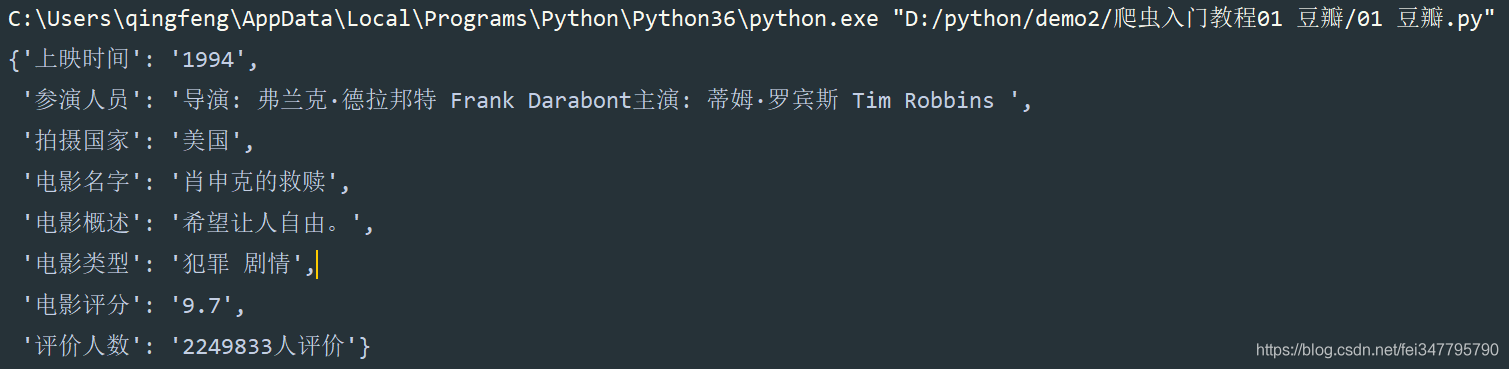
dit = {
'电影名字': title,
'参演人员': star,
'上映时间': movie_time,
'拍摄国家': movie_country,
'电影类型': movie_type,
'电影评分': rating_num,
'评价人数': people,
'电影概述': summary,
}
# pprint 格式化输出模块
pprint.pprint(dit)
以上的知识点使用到了
- parsel 解析模块的方法
- for 循环
- css 选择器
- 字典的创建
- 列表取值
- 字符串的方法:分割、替换等
- pprint 格式化输出模块
所以扎实基础是很有必要的。不然你连代码都不知道为什么要这样写。
五、保存数据(数据持久化)
常用的保存数据方法 with open
像豆瓣电影信息这样的数据,保存到Excel表格里面会更好。
所以需要使用到 csv 模块
# csv模块保存数据到Excel
f = open('豆瓣电影数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['电影名字', '参演人员', '上映时间', '拍摄国家', '电影类型',
'电影评分', '评价人数', '电影概述'])
csv_writer.writeheader() # 写入表头
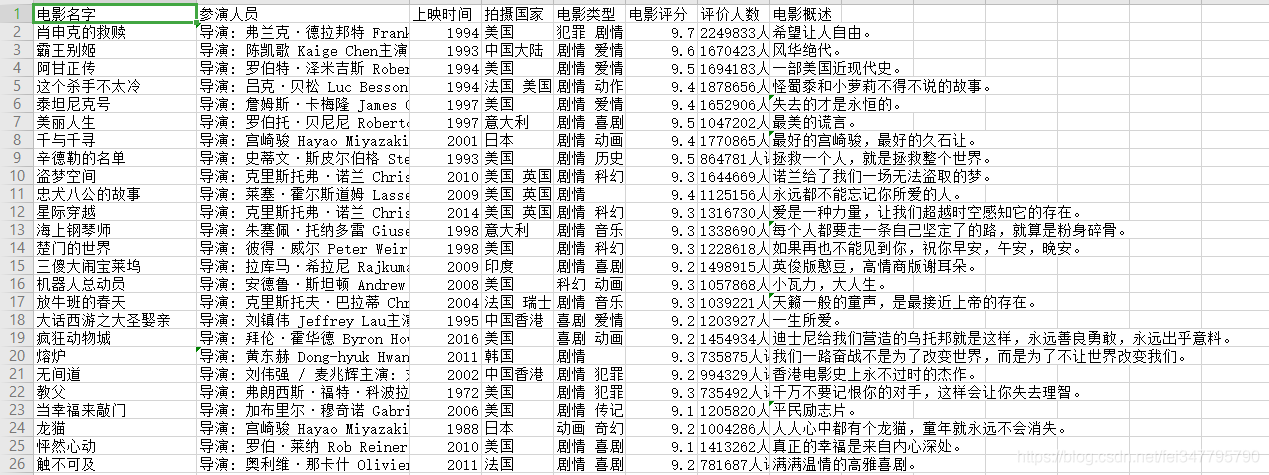
这就是爬取了数据保存到本地了。这只是一页的数据,爬取数据肯定不只是爬取一页数据。想要实现多页数据爬取,就要分析网页数据的url地址变化规律。
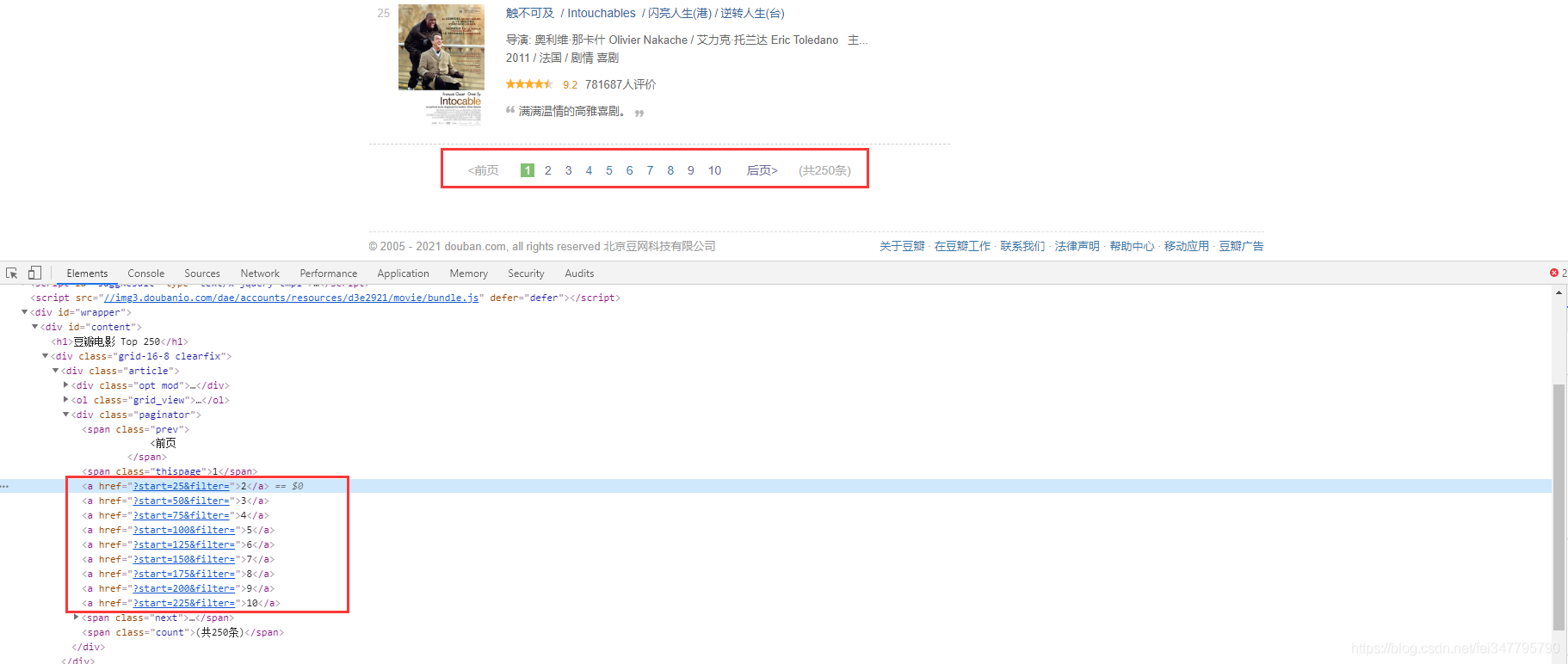
可以清楚看到每页url地址是 25 递增的,使用for循环实现翻页操作
for page in range(0, 251, 25):
url = f'https://movie.douban.com/top250?start={page}&filter='
完整实现代码
""""""
import pprint
import requests
import parsel
import csv
'''
1、明确需求:
爬取豆瓣Top250排行电影信息
电影名字
导演、主演
年份、国家、类型
评分、评价人数
电影简介
'''
# csv模块保存数据到Excel
f = open('豆瓣电影数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['电影名字', '参演人员', '上映时间', '拍摄国家', '电影类型',
'电影评分', '评价人数', '电影概述'])
csv_writer.writeheader() # 写入表头
# 模拟浏览器发送请求
for page in range(0, 251, 25):
url = f'https://movie.douban.com/top250?start={page}&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# 把 response.text 文本数据转换成 selector 对象
selector = parsel.Selector(response.text)
# 获取所有li标签
lis = selector.css('.grid_view li')
# 遍历出每个li标签内容
for li in lis:
# 获取电影标题 hd 类属性 下面的 a 标签下面的 第一个span标签里面的文本数据 get()输出形式是 字符串获取一个 getall() 输出形式是列表获取所有
title = li.css('.hd a span:nth-child(1)::text').get() # get()输出形式是 字符串
movie_list = li.css('.bd p:nth-child(1)::text').getall() # getall() 输出形式是列表
star = movie_list[0].strip().replace('\xa0\xa0\xa0', '').replace('/...', '')
movie_info = movie_list[1].strip().split('\xa0/\xa0') # ['1994', '美国', '犯罪 剧情']
movie_time = movie_info[0] # 电影上映时间
movie_country = movie_info[1] # 哪个国家的电影
movie_type = movie_info[2] # 什么类型的电影
rating_num = li.css('.rating_num::text').get() # 电影评分
people = li.css('.star span:nth-child(4)::text').get() # 评价人数
summary = li.css('.inq::text').get() # 一句话概述
dit = {
'电影名字': title,
'参演人员': star,
'上映时间': movie_time,
'拍摄国家': movie_country,
'电影类型': movie_type,
'电影评分': rating_num,
'评价人数': people,
'电影概述': summary,
}
pprint.pprint(dit)
csv_writer.writerow(dit)
实现效果
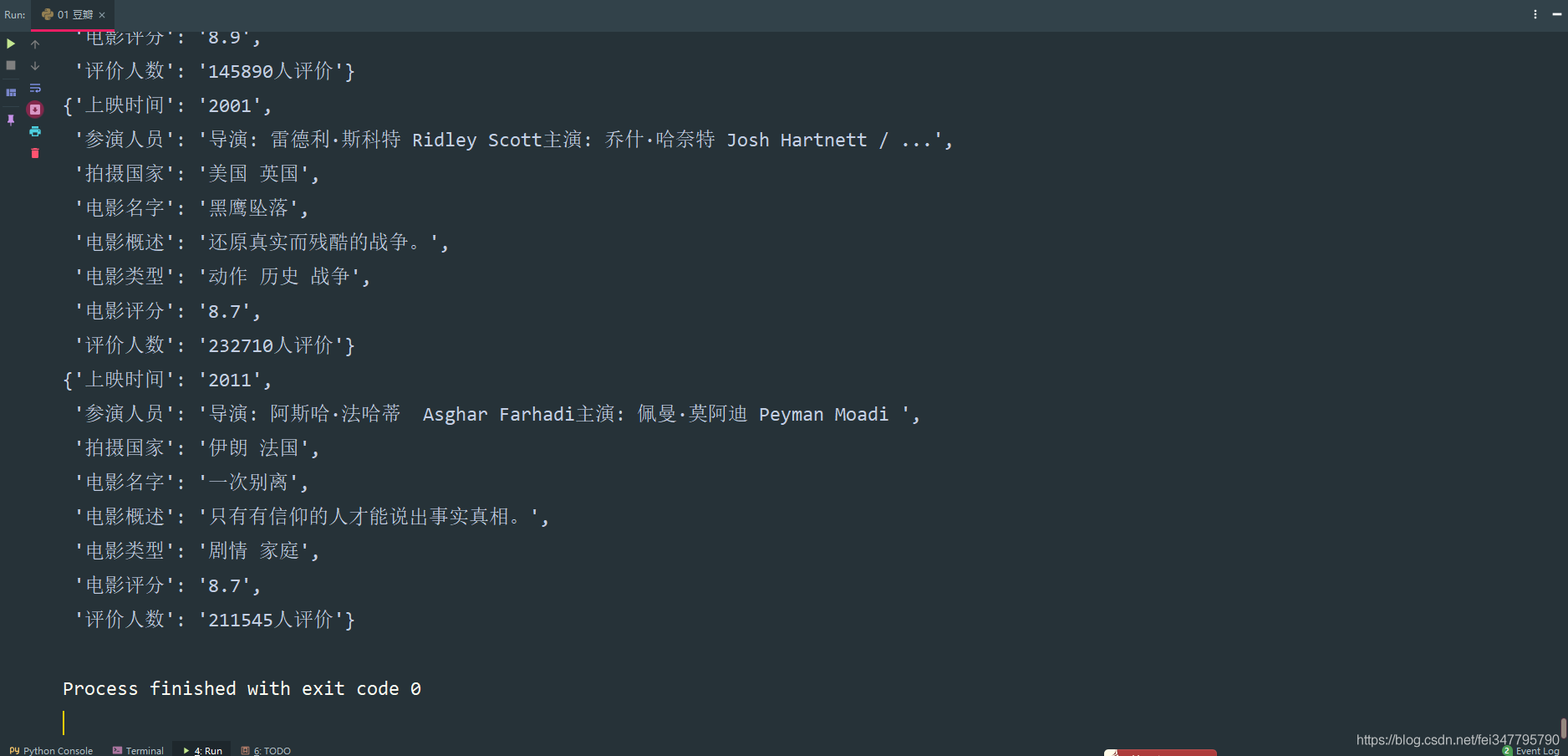
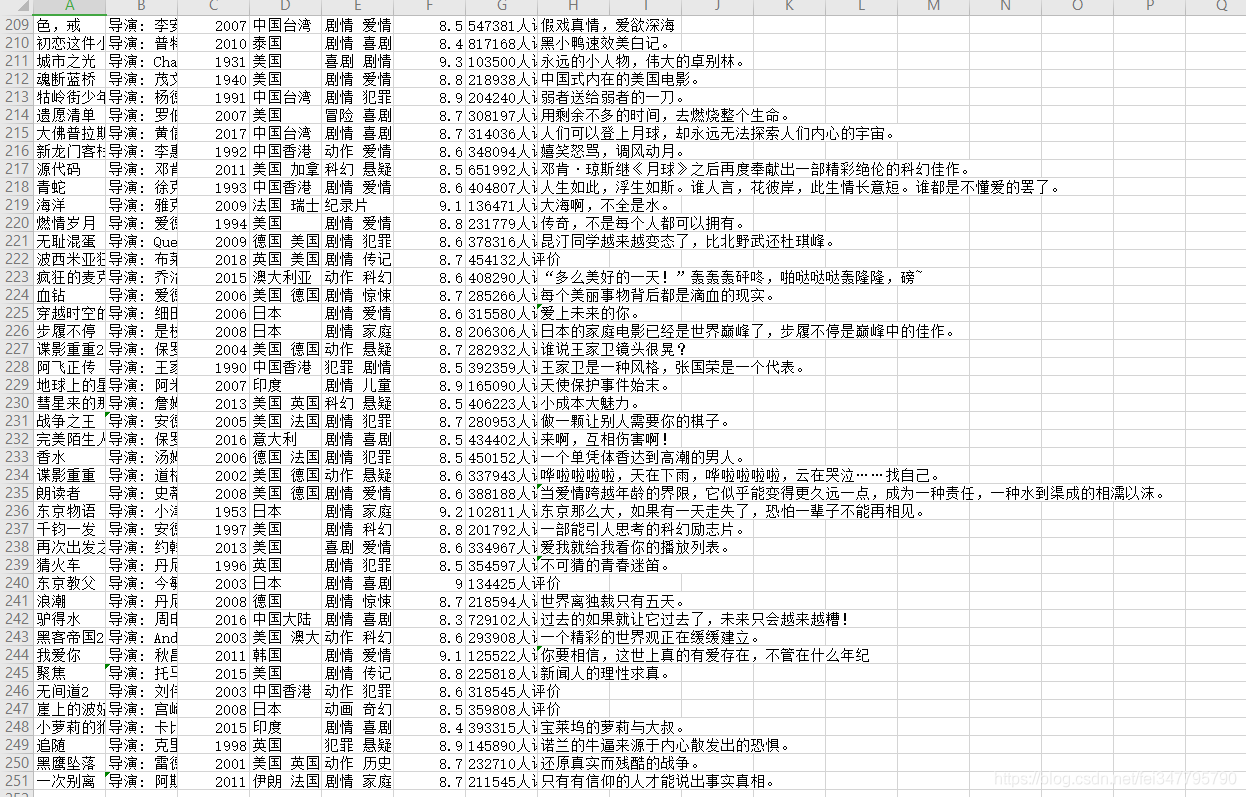
到此这篇关于Python爬虫入门教程01之爬取豆瓣Top电影的文章就介绍到这了,更多相关Python爬取豆瓣Top电影内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬虫基础之urllib的使用
一.urllib 和 urllib2的关系 在python2中,主要使用urllib和urllib2,而python3对urllib和urllib2进行了重构,拆分成了urllib.request, urllib.parse, urllib.error,urllib.robotparser等几个子模块,这样的架构从逻辑和结构上说更加合理.urllib库无需安装,python3自带.python 3.x中将urllib库和urilib2库合并成了urllib库. urllib2.urlopen()
-
Python爬虫之Selenium库的使用方法
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需求.支持自动录制动作和自动生成 .Net.Java.Perl等不同语言的测试
-

Python爬虫自动化获取华图和粉笔网站的错题(推荐)
这篇博客对于考公人或者其他用华图或者粉笔做题的人比较友好,通过输入网址可以自动化获取华图以及粉笔练习的错题. 粉笔网站 我们从做过的题目组中获取错题 打开某一次做题组,我们首先进行抓包看看数据在哪里 我们发现现在数据已经被隐藏,事实上数据在这两个包中: https://tiku.fenbi.com/api/xingce/questions https://tiku.fenbi.com/api/xingce/solutions 一个为题目的一个为解析的.此url要通过传入一个题目组参数才能获取到当
-
python基于爬虫+django,打造个性化API接口
简述 今天也是同事在做微信小程序的开发,需要音乐接口的测试,可是用网易云的开放接口比较麻烦,也不能进行测试,这里也是和我说了一下,所以就用爬虫写了个简单网易云歌曲URL的爬虫,把数据存入mysql数据库,再利用django封装装了一个简单的API接口,给同事测试使用. 原理 创建django项目,做好基础的配置,在views里写两个方法,一个是从mysql数据库中查数据然后封装成API,一个是爬虫方法,数据扒下来以后,通过django的ORM把数据插入到mysql数据库中. 这里的路由也是对应两
-
Python爬虫入门教程02之笔趣阁小说爬取
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前文 01.python爬虫入门教程01:豆瓣Top电影爬取 基本开发环境 Python 3.6 Pycharm 相关模块的使用 request sparsel 安装Python并添加到环境变量,pip安装需要的相关模块即可. 单章爬取 一.明确需求 爬取小说内容保存到本地 小说名字 小说章节名字 小说内容 # 第一章小说url地址 url = 'http://www.biquges.co
-
Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
python爬虫入门教程--优雅的HTTP库requests(二)
前言 urllib.urllib2.urllib3.httplib.httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反人类,更糟糕的是这些模块在 Python2 与 Python3 中有很大的差异,如果业务代码要同时兼容 2 和 3,写起来会让人崩溃. 好在,还有一个非常惊艳的 HTTP 库叫 requests,它是 GitHUb 关注数最多的 Python 项目之一,requests 的作者是 Kenneth Reitz 大神. requests 实现了 HTTP
-
Python爬虫实战之虎牙视频爬取附源码
目录 知识点 开发环境 分析目标url 开始代码 最开始还是线导入所需模块 数据请求 获取视频标题以及url地址 获取视频id 保存数据 调用函数 运行代码,得到数据 知识点 爬虫基本流程 re正则表达式简单使用 requests json数据解析方法 视频数据保存 开发环境 Python 3.8 Pycharm 爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析] 1.确定需求 (爬取的内容是什么东西?) 都通过开发者工具进行抓包分析 分析视频播放url地址 是
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
python使用re模块爬取豆瓣Top250电影
爬蟲四步原理: 1.发送请求:requests 2.获取相应数据:对方及其直接返回 3.解析并提取想要的数据:re 4.保存提取后的数据:with open()文件处理 爬蟲三步曲: 1.发送请求 2.解析数据 3.保存数据 注意:豆瓣网页爬虫必须使用请求头,否则服务器不予返回数据 import re import requests # 爬蟲三部曲: # 1.获取请求 def get_data(url, headers): response = requests.get(url, headers