Redis入门教程详解
目录
- Redis
- 一、Redis基本数据结构
- 1. 字符串 (String)
- 2. 散列(hash)
- 3. 列表(list)
- 4. 集合(Set)
- 5. 有序集合(sorted set)
- 二、Redis的高级数据结构
- 1. HyperLogLog
- 2. GEO
- 3. BitMap
- 三、Redis 高级特性
- 1. Redis事务
- 2. 发布订阅
- 3. 脚本
- 4. Redis Stream
- 四、Redis使用场景
- 1. 业务数据缓存
- 2. 业务数据处理
- 3. 全局一致计数
- 4. 高效统计计数
- 5. 发布订阅与Stream
- 6. 分布式锁
- 五、Redis的Java客户端
- 1. Jedis
- 2. Lettuce
- 3. Redission
- 六、项目集成
- 1. SpringMvc项目可以引入Spring data redis
- 2. SpringBoot接入(默认使用的Lettuce)
- 3. Spring Cache 集成Redis
- 番外:
Redis
Redis是一个开源(BSD许可)的内存数据结构存储,用作数据库、缓存和消息代理。Redis提供数据结构,如strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams.。Redis具有内置复制、Lua脚本、LRU eviction、事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster的自动分区提供高可用性。
一、Redis基本数据结构
1. 字符串 (String)
字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这意味着该类型可以接受任何格式的数据,如JPEG图像数据或json对象描述信息等。在Redis中字符串类型的value最多可以容纳的数据长度是512M。
常用命令:
- set key value 设置值
- get key 获取值
- getset 将给定的值设置进去,并返回旧值
- mget key1 key2... 获取一个或多个key的值
- setnx key value 当key不存在时才设置值
- incr key 将key存储的值+1
- incrby key increment 将 key 所储存的值加上给定的增量值(increment)
- decr key 将key存储的值-1
- decrby key increment 将 key 所储存的值减去给定的增量值(increment)
- strlen key 返回key所存储的字符串的长度
注意:
1.字符串append命令会使用更多的内存
2.整数共享:如果能使用整数,就尽量使用整数
3.整数精度问题:redis能保证16位精度,17-18位的大整数就会丢失精度
2. 散列(hash)
Redis中Hash类型可以看成句又String key和String value的map容器。所以该类型非常适合存储对象的信息。
常用命令:
- hset key field value
- hget key field
- hmset key field1 value1 [field2 value2 ] 同时set多个field值
- hmget key field1 [field2]
- hgetall key 获取key的所有值
- hincrby key field increment 给指定的key的field增加给定的增量值(increment)
- hkeys key 获取某个key的所有field
- hvals key 获取某个key的所有value
- hlen key 获取hash表中字段的数量
- hexists key field 查看hash表中的字段是否存在
- hdel key field1 [field2] 删除一个或多个hash表字段
3. 列表(list)
在Redis中,List类型是按照插入顺序排序的字符串链表。和数据库结构中的普通链表一样,可以在头部和尾部添加新的元素。在插入时如果键不存在,Redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也会被从数据库中删除。
常用命令:
- lpush key value1 [value2] 将一个值或多个值插入到列表头部
- rpush key value1 [value2] 将一个值或多个值插入到列表尾部
- lrange key start stop 获取列表指定范围的元素
- lpop key 移出并获取列表中的第一个元素
- rpop key 移出并获取列表中的最后一个元素
- blpop key1 [key2 ] timeout 阻塞性的移出并获取列表的第一个元素,如果没有元素就会阻塞到超时或有元素为止
- brpop key1 [key2 ] timeout 阻塞性的移出并获取列表的最后一个元素,如果没有元素就会阻塞到超时或有元素为止
- lindex key index 通过索引位置获取列表中的元素
- llen key 获取列表长度
- lset key index value 通过索引位置设置值
- ltrim key start stop 对一个列表进行修剪,只保留指定区间的元素,区间外的都删除掉
4. 集合(Set)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 2^32 - 1
常用命令:
- sadd key member1 [member2] 向集合中添加元素
- scard key 获取集合的成员数
- sdiff key1 [key2] 返回第一个集合与其他集合之间的差异
- sinter key1 [key2] 返回给定所有集合的交集
- sunion key1 [key2] 返回给定集合的并集
- sismember key member 判断member元素是否是集合中的成员
- smembers key 返回集合中所有成员
- spop key 移除并返回集中中的一个随机元素
- srandmember key [count] 返回集合中一个或多个随机数
- srem key member1 [member2] 移除集合中一个或多个成员
5. 有序集合(sorted set)
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
常用命令:
- zadd key score1 member1 [score2 member2] 向有序集合中添加一个或多个成员,或更新已有成员的分数
- zcard key 获取有序集合中的成员数量
- zrange key start end [withscores] 通过索引区间返回有序集合中的成员
- zrevrange key start stop [WITHSCORES] 通过索引区间返回有序集合中的成员,分数从高到低
- zrangebyscore key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员
- zrevrangebyscore key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员,分数由高到低排序
- zrem key member [member ...] 移除
- zremrangebyrank key start stop 移除给定排名区间的所有成员
- zremrangebyscore key min max 移除给定分数区间的所有成员
- zscore key member 返回有序集合中成员的分数
二、Redis的高级数据结构
1. HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。Redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。不过这个是估算,有一定的误差。
基数计算指的是统计一批元素中不重复元素的个数,比如UV的统计。实现基数统计最常见的是用Set这种数据结构。但是大数据量下Set会占用很大的存储空间。
常用命令:
- pfadd key element [element ...] 添加指定元素到HyperLogLog 中
- pfcount key [key ...] 返回给定key的基数估算值
- pfmerge destkey sourcekey [sourcekey ...] 将多个hyperloglog 合为一个
2. GEO
Redis GEO主要用于存储地理位置信息,并对其进行操作。该功能在Redis3.2版本增加
常用命令:
- geoadd key longitude latitude member [longitude latitude member ...] 添加地理位置坐标
- geopos key member [member ...] 返回指定member的经纬度
- geodist key member1 member2 [m|km|ft|mi] 计算两个位置的距离 后面的是单位
m【米】 km【千米】 ft【英尺】 mi【英里】
- georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] 以给定的经纬度为中心,返回键包含的元素中,与中心距离不超过给定最大距离的所有位置元素
- georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] 同上,只不过中心位置的传参由经纬度变成了member
- geohash key member [member ...] 获取一个或多个元素的geohash值
3. BitMap
BitMap的原理上一篇已经讲过了,它可以用作大数据量的存储,不过存储的内容只能是0或1. 可以使用在10亿用户的在线状态,1代表在线,0代表离线。
value值只能是0、1
- setbit key offset value
- getbit key offset
- bitcount key 获取值为1的个数
三、Redis 高级特性
1. Redis事务
Redis的事务与数据库的事务概念不同,Redis会将一个事务中的所有命令序列化,然后按顺序执行。Redis不可能在一个Redis事务的执行过程中插入执行另一个客户端发出的请求,事务中任意命令失败不影响其他命令的执行,也不会回滚。
2. 发布订阅
发布订阅是一种通信模式,发送者发送消息,订阅者接受消息。客户端可以订阅多个频道,然后有新消息发送给频道,订阅该频道的客户端就都能收到消息。

常用命令:
- subscribe channel [channel ...] 订阅一个或多个频道
- psubscribe pattern [pattern ...] 订阅一个或多个符合给定模式的频道
- publish channel message 将消息发送到指定通道
- unsubscribe [channel [channel ...]] 退订给定的频道
- punsubscribe channel [channel ...] 退订所有给定模式的频道。
3. 脚本
Redis 脚本通过Lua解释器来执行脚本,Redis 2.6 版本通过内嵌支持Lua环境
基本语法如下:
EVAL script numkeys key [key ...] arg [arg ...]
例子:
EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
4. Redis Stream
Redis Stream是5.0版本新增的数据结构。Redis Stream主要用于消息队列,Redis本身有一个发布/订阅功能,但是它有一个缺点,消息没有持久化,如果网络中断或宕机,数据就会丢失。
Redis Stream提供了消息的持久化和主备复制功能,它有一个消息链表,把所有加入的消息都串起来,每个消息都有唯一的ID和内容。
常用命令:
- xadd key ID field value [field value ...] 添加消息
xadd mystream * name sa surname occc (*代表id由redis生成)
- xdel key ID [ID ..] 删除消息
- xrange key start end [COUNT count] 查看消息
xrange mystream - + (- 代表最小值,+ 代表最大值)
- xgroup [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername] 创建消费者组
从头开始消费:
xgroup create mystream consumer-group-name 0-0
从尾部开始消费,只接受新消息
xgroup create mystream consumer-group-name $
- xreadgroup group group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...] 从消费者组读取消息
XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream
第二个group :消费组名
consumer: 消费者名
count :读取数量
milliseconds : 阻塞毫秒数
key :队列名
ID:消息id
四、Redis使用场景
1. 业务数据缓存
1.通用数据缓存:String、list
2.等会话缓存、token、session缓存
2. 业务数据处理
1.非严格一致性要求的数据
2.业务操作去重:订单处理的幂等校验业务数据排序
3. 全局一致计数
1.全局流控
2.秒杀时库存计算
3.全局ID生成
4. 高效统计计数
1.id、ip等使用bitmap操作
2.使用HyperLogLog进行UV、PV等非精确性的统计
5. 发布订阅与Stream
用于消息发布订阅模式
6. 分布式锁
1.获取锁
set key my_random_value NX PX 30000
2.释放锁,需要用到lua脚本保证原子性
if redis.call("get",KEYS[1])==ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
五、Redis的Java客户端
1. Jedis
基于BIO、线程不安全,需要配置连接池管理连接
2. Lettuce
目前主流推荐的驱动,基于Netty NIO,API线程安全
3. Redission
基于Netty NIO,API线程安全。大量丰富的分布式功能,如分布式的基本数据类型和锁。
六、项目集成
1. SpringMvc项目可以引入Spring data redis
maven依赖
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>2.1.2.RELEASE</version>
</dependency>
核心是RedisTemplate(可以配置基于Jedis、Lettuce、Redisson),封装了基本的redis命令。
2. SpringBoot接入(默认使用的Lettuce)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
配置spring.redis
如:spring.redis.host=127.0.0.1
3. Spring Cache 集成Redis
1.启用Spring Cache
@EnableCaching
2.方法上添加缓存注解
@Override
@Cacheable(value = "userCache")
public User getUser(Integer id) {
return userMapper.getUser(id);
}
3.配置redisCache
@Configuration
public class CacheConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
return RedisCacheManager.create(redisConnectionFactory);
}
}
番外:
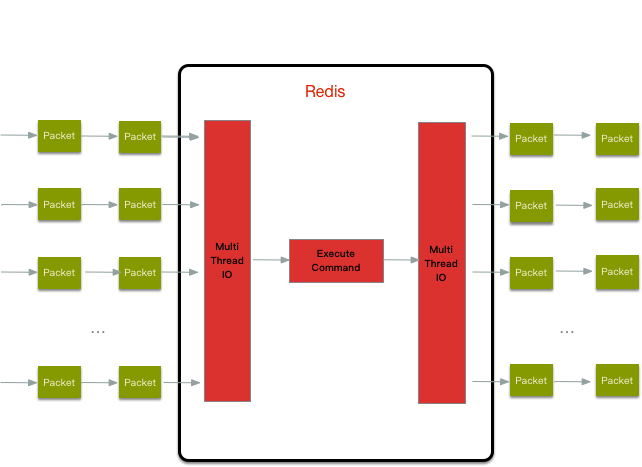
1.Redis到底是单线程,还是多线程?
这个问题有坑。首先Redis作为一个进程来讲是多个线程的。比如Redis通过多线程方式在后台删除对象、以及通过 Redis模块实现的阻塞命令等.单线程的地方在于探测哪个接收完了请求数据->数据处理->返回数据。而其他耗时操作是用了其他线程。
探测哪个客户端的请求接受完了,使用的是IO多路复用模型,“多路”是指多个网络连接,“复用”是复用同一个线程。

2.为什么IO模块在Redis6之前是单线程?
因为Redis是基于内存的操作,CPU不是瓶颈,瓶颈在于机器内存的大小或网络带宽。
3. Redis6之后的多线程是什么?
IO模型使用了多线程的NIO模型,内存处理线程也还是单线程。
以上就是Redis详解的详细内容,更多关于Redis的资料请关注我们其它相关文章!
相关推荐
-

Redis底层数据结构详解
Redis作为Key-Value存储系统,数据结构如下: Redis没有表的概念,Redis实例所对应的db以编号区分,db本身就是key的命名空间. 比如:user:1000作为key值,表示在user这个命名空间下id为1000的元素,类似于user表的id=1000的行. RedisDB结构 Redis中存在"数据库"的概念,该结构由redis.h中的redisDb定义. 当redis 服务器初始化时,会预先分配 16 个数据库 所有数据库保存到结构 redisServer 的一
-
redis的五大数据类型应用场景分析
目录 1.对象的类型与编码 2.字符串对象 3.列表对象 4.哈希对象 5.集合对象 6.有序集合对象 7.五大数据类型的应用场景 1.对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redisObject 结构来表示: typedef struct redisObject{ //类型 unsigned type:4; //编码 unsigned encod
-
详解Redis数据类型实现原理
目录 1. 对象的类型与编码 ① type属性 ② encoding 属性和 *prt 指针 2. 字符串对象 ① 编码 ② 编码的转换 3. 列表对象 ① 编码 ② 编码转换 4. 哈希对象 ① 编码 ② 编码转换 5. 集合对象 ① 编码 ② 编码转换 6. 有序集合对象 ① 编码 ② 编码转换 7. 五大数据类型的应用场景 1. 对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Re
-
Redis入门教程详解
目录 Redis 一.Redis基本数据结构 1. 字符串 (String) 2. 散列(hash) 3. 列表(list) 4. 集合(Set) 5. 有序集合(sorted set) 二.Redis的高级数据结构 1. HyperLogLog 2. GEO 3. BitMap 三.Redis 高级特性 1. Redis事务 2. 发布订阅 3. 脚本 4. Redis Stream 四.Redis使用场景 1. 业务数据缓存 2. 业务数据处理 3. 全局一致计数 4. 高效统计计数 5.
-
ABP(现代ASP.NET样板开发框架)系列之二、ABP入门教程详解
ABP是"ASP.NET Boilerplate Project (ASP.NET样板项目)"的简称. ASP.NET Boilerplate是一个用最佳实践和流行技术开发现代WEB应用程序的新起点,它旨在成为一个通用的WEB应用程序框架和项目模板. ABP的官方网站:http://www.aspnetboilerplate.com ABP在Github上的开源项目:https://github.com/aspnetboilerplate ABP 的由来 "DRY--避免重复
-
Vuejs第一篇之入门教程详解(单向绑定、双向绑定、列表渲染、响应函数)
什么是组件? 组件(Component)是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码.在较高层面上,组件是自定义元素,Vue.js 的编译器为它添加特殊功能.在有些情况下,组件也可以是原生 HTML 元素的形式,以 is 特性扩展. 接下来给大家介绍vuejs单向绑定.双向绑定.列表渲染.响应函数基础知识,具体详情如下所示: (一)单向绑定 <div id="app"> {{ message }} </div> <sc
-
BootStrop前端框架入门教程详解
Bootstrap,来自 Twitter,是目前最受欢迎的前端框架.Bootstrap 是基于 HTML.CSS.JAVASCRIPT 的,它简洁灵活,使得 Web 开发更加快捷. bootstrap 的学习非常简单,并且它所提供的样式又非常精美.只要稍微简单的学习就可以制作出漂亮的页面. bootstrap中文网:http://v3.bootcss.com/ bootstrap提供了三种类型的下载: -----------------------------------------------
-
Node.js+Express配置入门教程详解
Node.js是一个Javascript运行环境(runtime).实际上它是对Google V8引擎进行了封装.V8引 擎执行Javascript的速度非常快,性能非常好.Node.js对一些特殊用例进行了优化,提供了替代的API,使得V8在非浏览器环境下运行得更好.Node.js是一个基于Chrome JavaScript运行时建立的平台, 用于方便地搭建响应速度快.易于扩展的网络应用.Node.js 使用事件驱动, 非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行的数据密集型
-
springboot连接Redis的教程详解
创建springboot项目 在NoSQL中选择Redis 项目目录 pom.xml中还需要加入下面的jar包 org.springframework.boot spring-boot-starter-json 在application.properties文件中添加Redis服务器信息 spring.redis.host=192.168.5.132 spring.redis.port=6379 剩下4个test类,我直接以源码的方式粘出来,里面有些代码是非必须的,我保留了测试的验证过程,所以里
-
JSON Web Token(JWT)原理入门教程详解
目录 一.跨域认证的问题 二.JWT 的原理 三.JWT 的数据结构 3.1 Header 3.2 Payload 3.3 Signature 3.4 Base64URL 四.JWT 的使用方式 五.JWT 的几个特点 六.参考链接 一.跨域认证的问题 互联网服务离不开用户认证.一般流程是下面这样. 1.用户向服务器发送用户名和密码. 2.服务器验证通过后,在当前对话(session)里面保存相关数据,比如用户角色.登录时间等等. 3.服务器向用户返回一个 session_id,写入用户的 Co
-
SpringBoot入门教程详解
目录 一.SpringBoot简介 二.SpringBoot入门案例 1.创建项目 2.编写 Controller 类 3.启动项目 4.使用 Postman 测试 三.SpringBoot VS Spring 四.在官网中构建工程 六.SpringBoot 是如何实现简化开发的 1.启动依赖 2.引导类 七.切换 Web 一.SpringBoot简介 SpringBoot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化 Spring 应用的初始搭建以及开发过程. 我们在学习 S
-
JS库之Three.js 简易入门教程(详解之一)
开场白 webGL可以让我们在canvas上实现3D效果.而three.js是一款webGL框架,由于其易用性被广泛应用.如果你要学习webGL,抛弃那些复杂的原生接口从这款框架入手是一个不错的选择. 博主目前也在学习three.js,发现相关资料非常稀少,甚至官方的api文档也非常粗糙,很多效果需要自己慢慢敲代码摸索.所以我写这个教程的目的一是自己总结,二是与大家分享. 本篇是系列教程的第一篇:入门篇.在这篇文章中,我将以一个简单的demo为例,阐述three.js的基本配置方法.学完这篇文章
-
网络抓包工具wireshark入门教程详解
Wireshark(前称Ethereal)是一个网络数据包分析软件.网络数据包分析软件的功能是截取网络数据包,并尽可能显示出最为详细的网络数据包数据. Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换. 网络管理员使用Wireshark来检测网络问题,网络安全工程师使用Wireshark来检查资讯安全相关问题,开发者使用Wireshark来为新的通讯协定除错,普通使用者使用Wireshark来学习网络协定的相关知识. 当然,有的人也会"居心叵测"的用它来寻找一些