python爬虫之Appium爬取手机App数据及模拟用户手势
目录
- Appium
- 模拟操作
- 屏幕滑动
- 屏幕点击
- 屏幕拖动
- 屏幕拖拽
- 文本输入
- 动作链
- 实战:爬取微博首页信息

Appium
在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式。但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象。
那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容。

也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载一定的微博内容,也就如上图所示,只能获取2个微博内容。
模拟操作
所以,我们要实战获取微博内容的话,首先你需要学会如何模拟滑动屏幕操作。下面,我们来一一介绍屏幕的互动操作。
屏幕滑动
在Python的Appium-Python-Client包中,我们通过swipe()函数模拟用户手势从A滑动到B点,其具体的方法定义如下所示:
def swipe(self: T, start_x: int, start_y: int, end_x: int, end_y: int, duration: int = 0) -> T
start_x:开始位置的横坐标
start_y:开始位置的纵坐标
end_x:结束位置的横坐标
end_y:结束位置的纵坐标
duration:持续时间,也就是处于距离后生成滑动速度
当然,滑动的方法还有一个:flick(),它只有4个参数,缺少duration参数,也就是快速从某个位置滑动到指定的位置。
示例代码:
from appium import webdriver
import time
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
time.sleep(5)
el1 = driver.find_element_by_id("com.android.permissioncontroller:id/permission_allow_button")
el1.click()
time.sleep(5)
driver.swipe(500,500,500,2000,3000)
上面代码实现的下拉屏幕刷新功能,下拉刷新其实也是一个滑动的操作,是先滑动一段距离然后松开。
当然,如果你要实现上滑加载更多的微博,可以直接将坐标颠倒过来即可,这里我们将方法替换成flick(),也就是只需要替换最后一行代码。
driver.flick(487, 2085, 513, 257)
不过,这里有一个非常显著的问题,手机的坐标到底宽高都是多少呢?虽然说,我们程序员什么都通过代码先解决不要一上来就用工具。
但博主想说,这种坐标每个手机的像素分辨率都不同,比如上面swipe就是博主猜测的坐标。而flick()博主试了半天,没弄出来,最后还是借助Appium生成坐标给我。
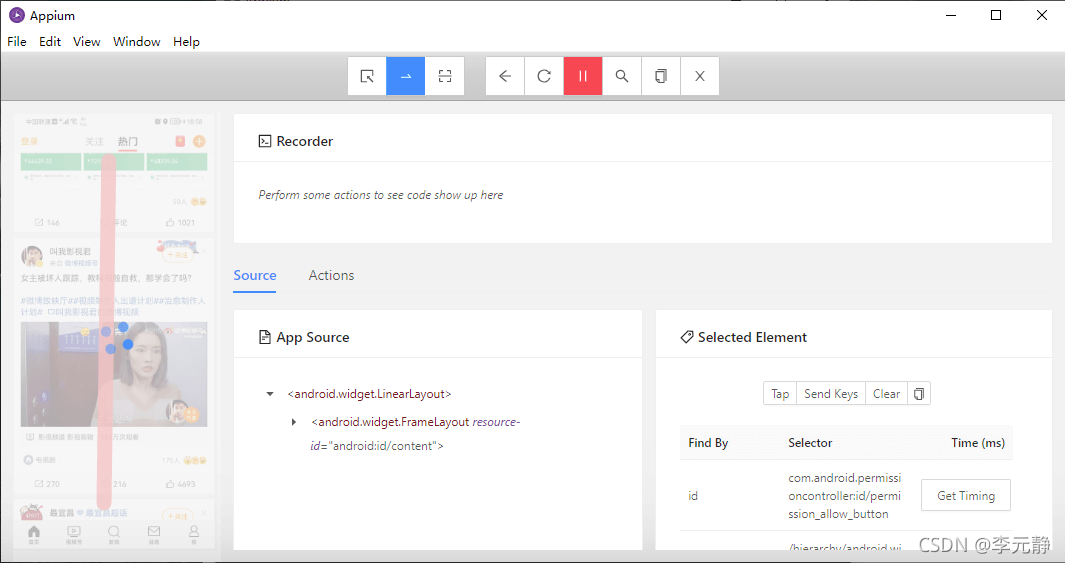
如上图所示,我们先点击蓝色选框中像“一横”的图标,然后记得点录制“眼睛”按钮。接着,在App上拉两个点,这2个点就是滑动的间距,最后生成如下图所示的代码。

这里就有2个坐标,当然上面的代码是动作链的知识后面我们会讲解。这里我们需要copy这2个坐标到flick()方法中,然后就可以下滑微博加载数据。
至于加载微博的动图与下滑微博的动图,大家都玩过微博,这里不需要演示。
屏幕点击
以前的微博都是限制为140字,你不需要打开微博详情,也能看到微博的所有数据。但是自从长微博出现之后,有些微博还必须点击进去才能看完整。
同样,我们爬取这些数据,有时候也要点击进去才能完全获取长微博的数据。所以,我们需要掌握如何点击某个微博。
在Appium包中,我们点击微博使用的是:tap()方法。该方法不仅支持单指点击,而且最多可以支持5个手指,同时也可以设置点击的时长。具体定义如下:
def tap(self: T, positions: List[Tuple[int, int]], duration: Optional[int] = None) -> T
positions:点击的位置组成的列表,比如五个手指,那就是5个坐标值的列表
duration:点击持续的时间,时间短就是点击操作,时间长就是长按操作
示例代码如下:
el2 = driver.tap([(500,500)]) el2.click()
不过,这里有读者肯定会问,每条微博的我难道用坐标取定位?那是怎么区分你点的是哪条微博,毕竟一个页面最少也有2条微博。这里,我们先来看张图:

这里,博主点击的是第2条微博数据,可以看到其id就是微博的内容。所以,后面我们想要获取微博的详细内容,可以直接通过获取内容后在点击。
屏幕拖动
看到这个小标题,博主都有写困惑。拖动与滑动是不是差不多的?
还别说,博主觉得还真差不多,不过这2个在Appium包中的方法却不一样,前文的滑动时通过坐标进行定位的,这里的拖动是通过元素定位的。
比如,你需要你滑动的距离是一个按钮到另一个按钮的位置,我们可以直接获取到这2个按钮,然后使用scroll()方法实现滑动操作。其定义如下:
def scroll(self: T, origin_el: WebElement, destination_el: WebElement, duration: Optional[int] = None) -> T
origin_el:被操作的元素
destination_el:目标元素
duration:持续时间
这里就不演示了,就是获取元素位置然后拖动到指定元素的位置。与前文实现的效果差不多,只是将坐标变成了2个元素的位置。
屏幕拖拽
同样的,微博不好演示的还有拖拽操作。它的方法为drag_and_drop(),其定义如下:
def drag_and_drop(self: T, origin_el: WebElement, destination_el: WebElement) -> T
origin_el:被拖拽的元素
destination_el:目标元素
这里的拖拽你可以理解为将一个按钮元素拖动到另一个按钮的位置,这里拖拽的是元素本身,不是位置的滑动。微博中暂时也没有演示的操作,感兴趣的可以测试其他App。
文本输入
在模拟登录或者说这里发微博的时候,用户肯定需要模拟输入文本。而且,在需要登录的爬虫场景之下,登录都是必备步骤。比如微信朋友圈内容的爬取,你不登陆看得到朋友圈吗?
所以,我们需要掌握Appium的文本输入操作。而它提供了2个方法进行文本的输入,一个是set_text();一个是send_keys()。
现在我们模拟微博输入账号,示例代码如下:
from appium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as ec
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
wait = WebDriverWait(driver, 20)
time.sleep(5)
el1 = driver.find_element_by_id("com.android.permissioncontroller:id/permission_allow_button")
el1.click()
el2 = wait.until(ec.presence_of_element_located((By.ID, 'com.sina.weibo:id/titleBack')))
el2.click()
el3 = wait.until(ec.presence_of_element_located((By.ID, 'com.sina.weibo:id/et_login_view_phone')))
el3.send_keys("liyuanjinglyj@163.com")
这里,我们只是模拟输入文本,当然登录用户名是手机,但手机属于隐私。博主这里替换成邮箱。感兴趣的可以自己替换手机试试。同时也可以替换为send_text()方法。
动作链
动作链顾名思义就是一系列操作动作的组合。在Selenium中,动作链是ActionChains,而Appium中,动作链是TouchAction。
比如,我们执行的下拉刷新其实就是一个动作链。这里,我们会执行2个动作,一个是按压,一个是从指定位置滑动到另一个位置。这里,我们将2个动作组合实现:
TouchAction(driver).press(x=380, y=2101).move_to(x=390, y=519).release()
实战:爬取微博首页信息
其实,Appium开始推出的时候,是为了自动化测试准备的工具,并不专用于爬虫数据。而且Appium有一个缺陷,目前没有直接的办法获取图片。
如果你想下载App界面中的图片,可以模拟用户长按的操作进行图片的下载。也可以直接截图。话不多说,我们来实现获取微博的文字信息并保存到目录。示例如下:
from appium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
import os
def mkdir(path):
path = path.strip()
path = path.rstrip("\\")
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
wait = WebDriverWait(driver, 20)
time.sleep(5)
el1 = driver.find_element_by_id("com.android.permissioncontroller:id/permission_allow_button")
el1.click()
time.sleep(5)
mkdir("weiboFile")
for i in range(10):
items = driver.find_elements_by_id("com.sina.weibo:id/contentTextView")
for item in items:
txt_text = item.get_attribute("content-desc")
folder_output = 'weiboFile/%s.txt' % str(int(time.time()))
with open(folder_output, "w", encoding='utf-8') as f:
f.write(txt_text)
f.close()
print(txt_text)
driver.swipe(487, 2085, 513, 257, 3000)
上面代码主要的功能在for-in循环之中。这里,我们通过先获取文本数据保存之后,在滑动屏幕获取其他的微博数据。
如果你想获取更多的数据,可以把循环的次数设置的更大一些。因为App的数据都是在滑动之中进行加载的。运行之后,效果如下所示:


到此这篇关于python爬虫之Appium爬取手机App数据及模拟用户手势的文章就介绍到这了,更多相关Appium爬取手机App数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解使用python爬取抖音app视频(appium可以操控手机)
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思路: 假设已经配置好我们所需要的工具 1.使用mitmproxy对手机app抓包获取我们想要的内容 2.利用appium自动化测试工具,驱动app模拟人的动作(滑动.点击等) 3.将1和2相结合达到自动化爬虫的效果 一.mitmproxy/mitmdump抓包 确保已经安装好了mitmproxy,并
-
Python+Appium新手教程
准备 1.电脑系统:win10 2.手机:安卓(没钱买苹果) 3.需要的工具可以从官网下载 https://appium.io/ https://www.jetbrains.com/pycharm/ https://www.python.org/ https://www.oracle.com/cn/java/technologies/javase-downloads.html 安装 python jdk 编辑器PyCharm Appium-windows-x.x Appium_Python_Cl
-
Python实现Appium端口检测与释放的实现
1. 监测端口 我们要引用的socket模块来校验端口是否被占用. 1.1 socket是什么? 简单一句话:网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket.建立网络通信连接至少要一对端口号(socket). 1.2 socket本质是什么? socket本质是编程接口(API),对TCP/IP的封装,TCP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口. 关于socket的通讯原理,我们可以参考socket通讯原理 关于soc
-
Python使用Appium在移动端抓取微博数据的实现
目录 使用Appium在移动端抓取微博数据 查找Android App的Package和入口 记录微博刷新动作 爬取微博第一条信息 使用Appium在移动端抓取微博数据 Appium是移动端的自动化测试工具,读者可以类比为PC端的selenium.通过它,我们可以驱动App完成自动化的一系列操作,同样也可以爬取需要的内容. 这里,我们需要首先在PC端安装Appium软件,安装下载的地址如下:https://github.com/appium/appium-desktop/releases 安装软
-
Python3+Appium安装使用教程
一.安装 我们知道selenium是桌面浏览器自动化操作工具(Web Browser Automation) appium是继承selenium自动化思想旨在使手机app操作也能自动化的工具(Mobile App Automation Made Awesome). appium可以通过Desktop App和npm两种方式安装.Desktop App类似于selenium IDE提供一个图形界面式操作工具:npm类似于selenium就只能使用命令行. 如果对appium还不太熟悉,推荐使用De
-
Python3+Appium安装及Appium模拟微信登录方法详解
一.Appium安装 我们知道selenium是桌面浏览器自动化操作工具(Web Browser Automation) appium是继承selenium自动化思想旨在使手机app操作也能自动化的工具(Mobile App Automation Made Awesome). appium可以通过Desktop App和npm两种方式安装.Desktop App类似于selenium IDE提供一个图形界面式操作工具:npm类似于selenium就只能使用命令行. 如果对appium还不太熟悉,
-
python爬虫之Appium爬取手机App数据及模拟用户手势
目录 Appium 模拟操作 屏幕滑动 屏幕点击 屏幕拖动 屏幕拖拽 文本输入 动作链 实战:爬取微博首页信息 Appium 在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式.但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象. 那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容. 也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
Python爬虫利用多线程爬取 LOL 高清壁纸
目录 页面分析 抓取思路 数据采集 程序运行 总结 前言: 随着移动端的普及出现了很多的移动 APP,应用软件也随之流行起来. 最近又捡起来了英雄联盟手游,感觉还行,PC 端英雄联盟可谓是爆火的游戏,不知道移动端的英雄联盟前途如何,那今天我们使用到多线程的方式爬取 LOL 官网英雄高清壁纸. 页面分析 目标网站:英雄联盟 官网界面如图所示,显而易见,一个小图表示一个英雄,我们的目的是爬取每一个英雄的所有皮肤图片,全部下载下来并保存到本地. 次级页面 上面的页面我们称为主页面,次级页面也就是每一个
-
Python爬虫DOTA排行榜爬取实例(分享)
1.分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在 XHR一栏里,我们找到所请求的数据 json存储的数据 请求字段为: post请求字段 2.伪装浏览器,并将json数据存入excel里面 获取信息 将数据保存到excel中 3.结果展示 以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python爬虫小例子——爬取51job发布的工作职位
概述 不知从何时起,Python和爬虫就如初恋一般,情不知所起,一往而深,相信很多朋友学习Python,都是从爬虫开始,其实究其原因,不外两方面:其一Python对爬虫的支持度比较好,类库众多.其二Pyhton的语法简单,入门容易.所以两者形影相随,不离不弃,本文主要以一个简单的小例子,简述Python在爬虫方面的简单应用,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 本例主要爬取51job发布的工作职位,用到的知识点如下: 开发环境及工具:主要用到Python3.7 ,IDE为PyC
-
python爬虫使用正则爬取网站的实现
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关. 本文章是自己学习的一些记录.欢迎各位大佬点评! 首先 今天是第一天写博客,感受到了博客的魅力,博客不仅能够记录每天的代码学习情况,并且可以当作是自己的学习笔记,以便在后面知识点不清楚的时候前来复习.这是第一次使用爬虫爬取网页,这里展示的是爬取豆瓣电影top250的整个过程,欢迎大家指点. 这里我只爬取了电影链接和电影名称,如果想要更加完整的爬取代码,请联系我.qq 1540741
-
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip 环境:python3.8+pycharm 库:requests,lxml 浏览器:谷歌 IP地址:http://www.xiladaili.com/gaoni/ 分析网页源码: 选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath 我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1] 虽然可以查出来ip,但不利于程序自动爬取所有
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
Python爬虫UA伪装爬取的实例讲解
在使用python爬取网站信息时,查看爬取完后的数据发现,数据并没有被爬取下来,这是因为网站中有UA这种请求载体的身份标识,如果不是基于某一款浏览器爬取则是不正常的请求,所以会爬取失败.本文介绍Python爬虫采用UA伪装爬取实例. 一.python爬取失败原因如下: UA检测是门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求.如果检测到请求的载体身份标识不是基于某一款浏览器的.则表示该请求为不正常的请求,则服务器端就很有可能会
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查