shell中的排序算法示例代码
目录
- 冒泡排序法
- 基本思想:
- 算法思路
- 直接选择排序
- 基本思想:
- 反转排序
- 基本思想:
- 直接插入算法
- 基本思想:
- 希尔算法
- 基本思想
冒泡排序法
类似旗袍上涌的动作,会将数据在数组中从小大大或者从大到小不断的向前移动。
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
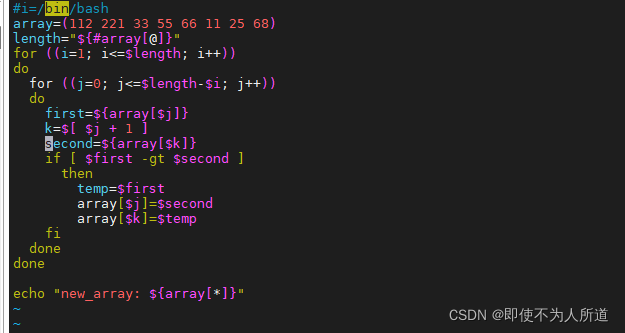
#!/bin/bash
array=(112 221 33 55 66 11 25 68)
length="${#array[@]}"
for ((i=1; i<=$length; i++))
do
for ((j=1; j<=$length-$i; j++))
do
first=${array[$j]}
k=$[$j+1]
second=${array[$k]}
if [ $first -gt $second ]
then
temp=$first
array[$j]=$second
array[$k]=$temp
fi
done
done
echo "new_array: ${array[@]}"
直接选择排序
与冒泡排序相比,直接选择排序的交换次数更少,所以速度会快些。
基本思想:
将指定排序位置与其它数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式。
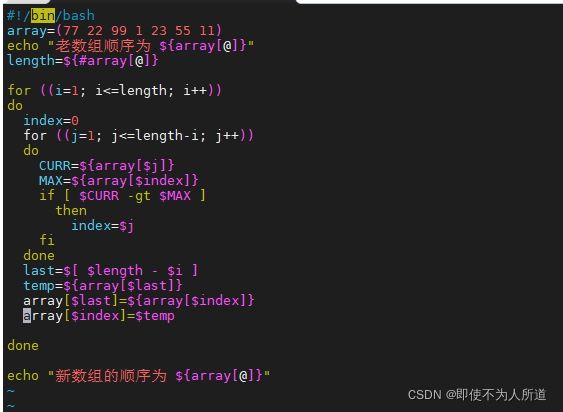
#!/bin/bash
array=(77 22 99 1 23 55 11)
echo "老数组顺序为 ${array[@]}"
length=${#array[@]}
for ((i=1; i<=length; i++))
do
index=0
for ((j=1; j<=length-i; j++))
do
CURR=${array[$j]}
MAX=${array[$index]}
if [ $CURR -gt $MAX ]
then
index=$j
fi
done
last=$[ $length - $i ]
temp=${array[$last]}
array[$last]=${array[$index]}
array[$index]=$temp
done
echo "新数组的顺序为 ${array[@]}"

反转排序
以相反的顺序把原有数组的内容重新排序。
基本思想:
把数组最后一个元素与第一个元素替换,倒数第二个元素与第二个元素替换,以此类推,直到把所有数组元素反转替换。
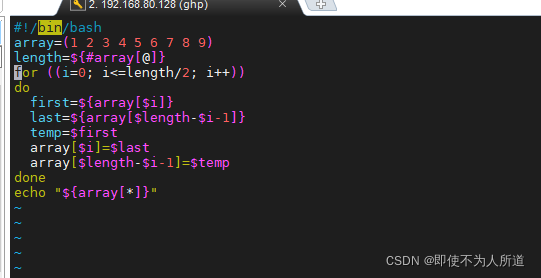
#!/bin/bash
array=(1 2 3 4 5 6 7 8 9)
length=${#array[@]}
for ((i=0; i<=length/2; i++))
do
first=${array[$i]}
last=${array[$length-$i-1]}
temp=$first
array[$i]=$last
array[$length-$i-1]=$temp
done
echo "${array[*]}"

直接插入算法
插入排序,又叫直接插入排序。实际中,我们玩扑克牌的时候,就用了插入排序的思想。
基本思想:
在待排序的元素中,假设前n-1个元素已有序,现将第n个元素插入到前面已经排好的序列中,使得前n个元素有序。按照此法对所有元素进行插入,直到整个序列有序。
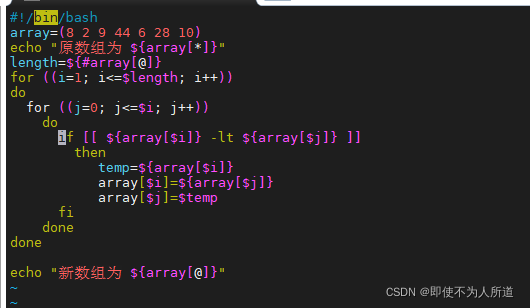
#!/bin/bash
array=(8 2 9 44 6 28 10)
echo "原数组为 ${array[*]}"
length=${#array[@]}
for ((i=1; i<=$length; i++))
do
for ((j=0; j<=$i; j++))
do
if [[ ${array[$i]} -lt ${array[$j]} ]]
then
temp=${array[$i]}
array[$i]=${array[$j]}
array[$j]=$temp
fi
done
done
echo "新数组为 ${array[@]}"
~
~

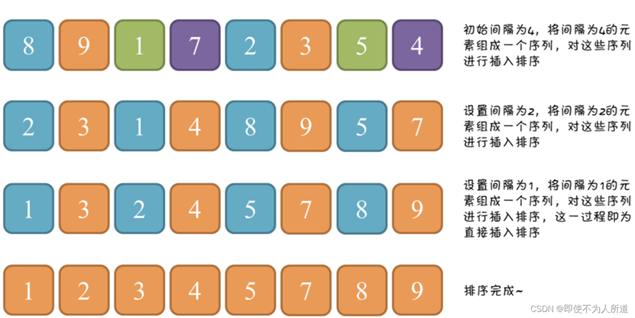
希尔算法
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序 。
基本思想
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
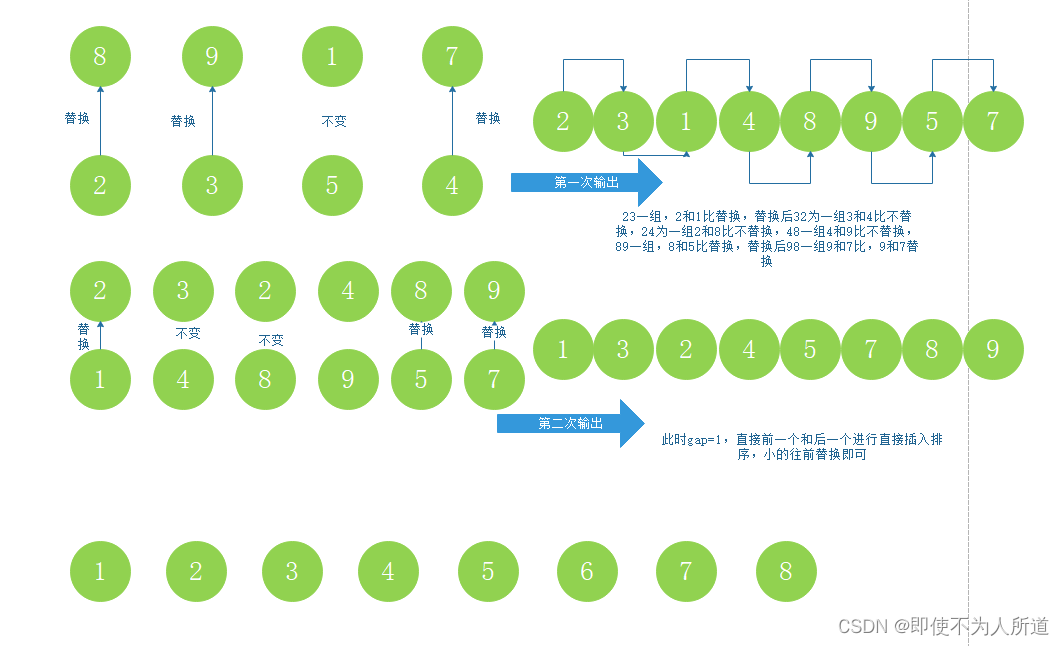
1.先选定一个小于N的整数gap作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作…
2.当增量的大小减到1时,就相当于整个序列被分到一组,进行一次直接插入排序,排序完成。
gap越大,数据挪动得越快;gap越小,数据挪动得越慢。前期让gap较大,可以让数据更快得移动到自己对应的位置附近,减少挪动次数。
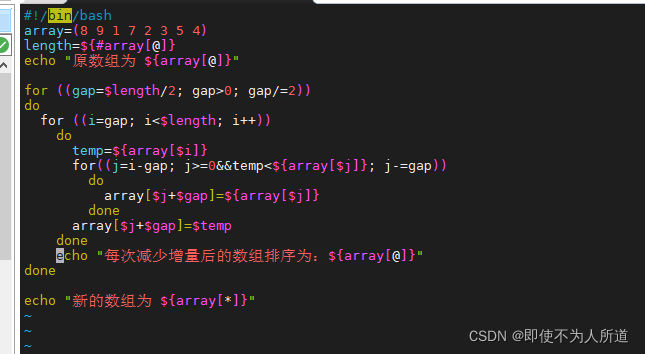
#!/bin/bash
array=(8 9 1 7 2 3 5 4)
length=${#array[@]}
echo "原数组为 ${array[@]}"
#设长度的一半为gap初始间隔,每次循环gap都除以2,直至gap为1结束循环
for ((gap=$length/2; gap>0; gap/=2))
do
#因为gap为整个长度的一半,所以gap到length结尾包含的元素数刚好为需要进行直接插入算法的个数
for ((i=gap; i<$length; i++))
do
#设一个第三变量方便直接插入进行交换
temp=${array[$i]}
#对距离为gap的元素组进行排序,每一轮比较拿当前轮次最后一个元素与组内其他元素比较,将数组大的往后放
for((j=i-gap; j>=0&&temp<${array[$j]}; j-=gap))
do
array[$j+$gap]=${array[$j]}
done
array[$j+$gap]=$temp
done
done
echo "新的数组为 ${array[*]}"

到此这篇关于shell中的排序算法示例代码的文章就介绍到这了,更多相关shell 排序算法 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

PHP排序算法之希尔排序(Shell Sort)实例分析
本文实例讲述了PHP排序算法之希尔排序(Shell Sort).分享给大家供大家参考,具体如下: 基本思想: 希尔排序是指记录按下标的一定增量分组,对每一组使用 直接插入排序 ,随着增量逐渐减少,每组包含的关键字越来越多,当增量减少至 1 时,整个序列恰好被分成一组,算法便终止. 操作步骤: 先取一个小于 n(序列记录个数) 的整数 d1 作为第一个增量,把文件的全部记录分组.所有距离为 d1 的倍数的记录放在同一个组中.先在各组内进行 直接插入排序:然后,取第二个增量 d2 < d1 重复上述
-
C语言基本排序算法之shell排序实例
本文实例讲述了C语言基本排序算法之shell排序.分享给大家供大家参考,具体如下: shell排序是对直接插入方法的改进方法. /*------------------------------------------------------------------------------------- Shell_sort.h shell排序是对直接插入方法的改进,它并不是对相邻元素进行比较,而是对一定间隔的元素比较. 选择增量序列的几种方法:(为方便,本例采用第一种增量序列) 1. h[1]=
-
shell中的排序算法示例代码
目录 冒泡排序法 基本思想: 算法思路 直接选择排序 基本思想: 反转排序 基本思想: 直接插入算法 基本思想: 希尔算法 基本思想 冒泡排序法 类似旗袍上涌的动作,会将数据在数组中从小大大或者从大到小不断的向前移动. 基本思想: 冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部. 算法思路 冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要
-
python3实现常见的排序算法(示例代码)
冒泡排序 冒泡排序是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. def mao(lst): for i in range(len(lst)): # 由于每一轮结束后,总一定有一个大的数排在后面 # 而且后面的数已经排好了 # 即i轮之后,就有i个数字被排好 # 所以其 len-1 -i到
-
java中TreeMap排序的示例代码
1. 定义TreeMap的排序方法 使用Comparator对象作为参数 需要注意的是:排序方法是针对键的,而不是值的.如果想针对值,需要更麻烦的一些方法(重写一些方法) TreeMap<Screen,Integer> res = new TreeMap<Screen, Integer>(new Comparator<Screen>() { @Override public int compare(Screen screen1, Screen t1) { // 定义Tr
-
Python实现各种排序算法的代码示例总结
在Python实践中,我们往往遇到排序问题,比如在对搜索结果打分的排序(没有排序就没有Google等搜索引擎的存在),当然,这样的例子数不胜数.<数据结构>也会花大量篇幅讲解排序.之前一段时间,由于需要,我复习了一下排序算法,并用Python实现了各种排序算法,放在这里作为参考. 最简单的排序有三种:插入排序,选择排序和冒泡排序.这三种排序比较简单,它们的平均时间复杂度均为O(n^2),在这里对原理就不加赘述了.贴出来源代码. 插入排序: def insertion_sort(sort_lis
-
Python cookbook(数据结构与算法)实现对不原生支持比较操作的对象排序算法示例
本文实例讲述了Python实现对不原生支持比较操作的对象排序算法.分享给大家供大家参考,具体如下: 问题:想在同一个类的实例之间做排序,但是它们并不原生支持比较操作. 解决方案:使用内建的sorted()函数可接受一个用来传递可调用对象的参数key,sorted利用该可调用对象返回的待排序对象中的某些值来比较对象. from operator import attrgetter class User: def __init__(self, user_id): self.user_id = use
-
Python cookbook(数据结构与算法)通过公共键对字典列表排序算法示例
本文实例讲述了Python通过公共键对字典列表排序算法.分享给大家供大家参考,具体如下: 问题:想根据一个或多个字典中的值来对列表排序 解决方案:利用operator模块中的itemgetter()函数对这类结构进行排序是非常简单的. # Sort a list of a dicts on a common key rows = [ {'fname': 'Brian', 'lname': 'Jones', 'uid': 1003}, {'fname': 'David', 'lname': 'Be
-
C++ 实现桶排序的示例代码
目录 原理 实现步骤: 模拟生成整数随机数 桶排序实现 完整版可运行程序 时间复杂度计算 桶排序:整数 原理 原理简述:按照需要排序数组的实际情况,生成一个一定长度的一维数组,用于统计需要排序数组的不同数值的重复次数,完成统计后,再按顺序重复输出该数值 实现步骤: 确定需要排序数组的最大值和最小值 生成桶数组,并初始化 对需要排序数组进行统计,统计结果放入相应的桶中 循环输出桶,并替换原序列 模拟生成整数随机数 #include <random> #include <ctime>
-
java睡眠排序算法示例实现
无聊逛论坛,发现了这张图 真是厉害啊,这排序, 既有多线程,又有排序,还有lambda表达式,但是这是C#版本,作为一个入坑的Java爱好者,当然要去试试Java版本了,废话不多说,上代码 /** * @author Marblog */ public class Main { public static void main(String[] args) { int[] nums = new int[]{235, 233, 110, 789, 5, 0, 1}; for (int item :
-
Python实现希尔排序,归并排序和桶排序的示例代码
目录 1. 前言 2. 希尔排序 2.1 前后切分 2.2 增量切分 3. 归并排序 3.1 分解子问题 3.2 求解子问题 3.3 合并排序 4. 基数排序 5. 总结 1. 前言 本文将介绍希尔排序.归并排序.基数排序(桶排序). 在所有的排序算法中,冒泡.插入.选择属于相类似的排序算法,这类算法的共同点:通过不停地比较,再使用交换逻辑重新确定数据的位置. 希尔.归并.快速排序算法也可归为同一类,它们的共同点都是建立在分治思想之上.把大问题分拆成小问题,解决所有小问题后,再合并每一个小问题的
-
C++实现中值滤波的示例代码
目录 冒泡排序实现: 中值滤波的实现: 为了加深对中值滤波算法的理解以及方便以后更好的复习,我将该算法的一些重点细节和实现过程踩过的坑记录下来. 中值滤波器是一种非线性滤波器,或者叫统计排序滤波器. 适用对象:带椒盐噪声的图像 由于椒盐噪声像素值与原图像素值没有关联,随机性较大,因此使用中值滤波可有效滤掉噪声. 中值滤波需要对像素值进行排序,因此首先写一个冒泡排序算法. 冒泡排序实现: 为提高效率加入标志位flag,当第i次寻找最大值时,如果相邻两个数均未发生互换,此时flag位为false,即