Go并发4种方法简明讲解
一、goroutine
1、协程(Coroutine)
Golang 在语言层面对并发编程进行了支持,使用了一种协程(goroutine)机制,
协程本质上是一种用户态线程,不需要操作系统来进行抢占式调度,但是又寄生于线程中,因此系统开销极小,可以有效的提高线程的任务并发性,而避免多线程的缺点。但是协程需要语言上的支持,需要用户自己实现调度器,因为在Go语言中,实现了调度器所以我们可以很方便的能过 go关键字来使用协程。
func main() {
for i := 0; i <10; i++ {
go func(i int) {
for {
fmt.Printf("Hello goroutine %d\n",i)
}
}(i)
}
time.Sleep(time.Millisecond)
}
最简单的一个并发编程小例子,并发输出一段话。
我们同时开了10个协程进行输出,每次在fmt.printf时交出控制权(不一定每次都会交出控制权),回到调度器中,再由调度器分配。
2、goroutine 可能切换的点
- I/O,Select
- channel
- 等待锁
- 函数调用
- runtime.Gosched()
我们看一个小例子:
func main() {
var a [10]int
for i := 0; i <10; i++ {
go func(i int) {
for {
a[i]++
}
}(i)
}
time.Sleep(time.Millisecond)
fmt.Println(a)
}
在这里,代码直接锁死,程序没有退出,因为在执行函数中没有协程的切换,因为 main函数也是一个协程。
如果想要程序退出,可以通过 runtime.Gosched()函数,在执行函数中添加一行。
for {
a[i]++
runtime.Gosched()
}
加上这个函数之后,代码是可以正常执行了,但是真的是正常执行吗?不一定,我们可以使用 -reac命令来看一下数据是否有冲突:
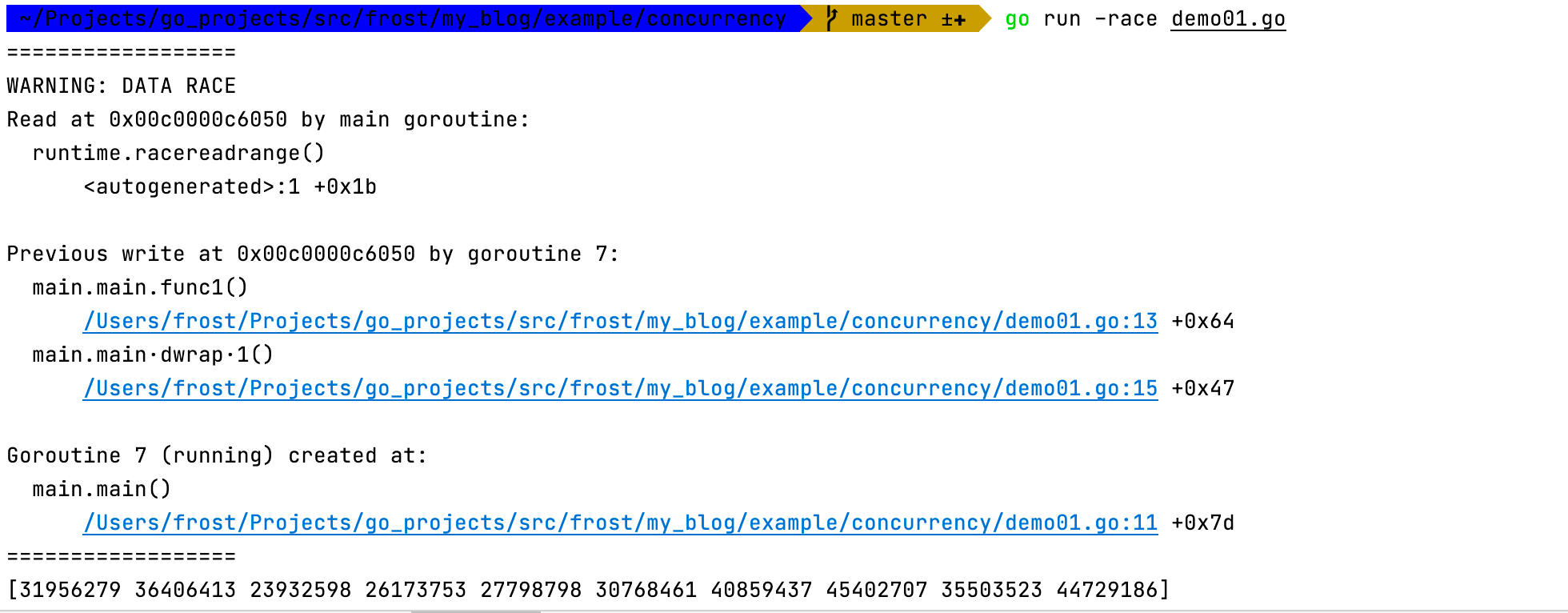
这说明数据还是有冲突的,数组a中的元素一边在做自增,一边在输出。解决这个问题,我们只能使用 channel 来解决。
二、Channel
Channel 中 Go语言在语言级别提供了对 goroutine 之间通信的支持,我们可以使用 channel 在两个或者多个goroutine之间进行信息传递,能过 channel 传递对像的过程和调用函数时的参数传递行为一样,可以传递普通参数和指针。
Channel 有两种模式:
var ch1 = make(chan int) // 无缓冲 channel,同步 var ch2 = make(chan int, 2) // 有缓冲 channel, 异步
无缓冲的方式,数据进入 channel 只要没有被接收,就会处在阻塞状态。
var ch1 = make(chan int) // 无缓冲 channel,同步 ch1 <- 1 ch1 <- 2 // error: all goroutines are asleep - deadlock! fmt.Println(<-ch1)
如果想要运行,必须要再开一个协程不停的去请求数据:
var ch1 = make(chan int) // 无缓冲 channel,同步
go func() {
for {
n := <-ch1
fmt.Println(n)
}
}()
ch1 <- 1
ch1 <- 2
有缓冲的方式,只要缓冲区没有满就可以一直进数据,缓冲区在填满之后没有接收也会处理阻塞状态。
func bufferChannel() {
var ch2 = make(chan int,2)
ch2<-1
ch2<-2
fmt.Println(ch2)
// 不加这一行的话,是可以正常运行的
ch2<-3 // error: all goroutines are asleep - deadlock!
}
1、chaanel 指定方向
比如我现在有一个函数创建一个 channel,并且不断的需要消费channel中的数据:
func worker(ch chan int) {
for {
fmt.Printf("hello goroutine worker %d\n", <-ch)
}
}
func createWorker() chan int{
ch := make(chan int)
go worker(ch)
return ch
}
func main() {
ch := createWorker()
ch<-1
ch<-2
ch<-3
time.Sleep(time.Millisecond)
}
这个函数我是要给别人用的,但是我怎么保证使用 createWorker 函数创建的 channel 都是往里面传入数据的呢?
如果外面有人消费了这个 channel 中的数据,我们怎么限制?
这个时候,我们就可以给返回的channel 加上方向,指明这个 channel 中能往里传入数据,不能从中取数据:
func worker(ch <-chan int) {
for {
fmt.Printf("hello goroutine worker %d\n", <-ch)
}
}
func createWorker() chan<- int{
ch := make(chan int)
go worker(ch)
return ch
}
我们可以在返回 channel 的地方加上方向,指明返回的函数只能是一个往里传入数据,不能从中取数据。
并且我们还可以给专门消费的函数加上一个方向,指明这个函数只能出不能进。
2、channel 关闭
在使用 channel 的时候,随说我们可以等待channel中的函数使用完之后自己结束,或者等待 main 函数结束时关闭所有的 goroutine 函数,但是这样的方式显示不够优雅。
当一个数据我们明确知道他的结束时候,我们可以发送一个关闭信息给这个 channel ,当这个 channel 接收到这个信号之后,自己关闭。
// 方法一
func worker(ch <-chan int) {
for {
if c ,ok := <- ch;ok{
fmt.Printf("hello goroutine worker %d\n", c)
}else {
break
}
}
}
// 方法二
func worker(ch <-chan int) {
for c := range ch{
fmt.Printf("hello goroutine worker %d\n", c)
}
}
func main() {
ch := createWorker()
ch<-1
ch<-2
ch<-3
close(ch)
time.Sleep(time.Millisecond)
}
通过 Closeb函数,我们可以能过 channel 已经关闭,并且我们还可以通过两种方法判断通道内是否还有值。
三、Select
当我们在实际开发中,我们一般同时处理两个或者多个 channel 的数据,我们想要完成一个那个 channel 先来数据,我们先来处理个那 channel 怎么办呢?
此时,我们就可以使用 select 调度:
func genInt() chan int {
ch := make(chan int)
go func() {
i := 0
for {
// 随机两秒以内生成一次数据
time.Sleep(time.Duration(rand.Intn(2000)) * time.Millisecond)
ch <- i
i++
}
}()
return ch
}
func main() {
var c1 = genInt()
var c2 = genInt()
for {
select {
case n := <-c1:
fmt.Printf("server 1 generator %d\n", n)
case n := <- c2:
fmt.Printf("server 2 generator %d\n", n)
}
}
}
1、定时器
for {
tick := time.Tick(time.Second)
select {
case n := <-c1:
fmt.Printf("server 1 generator %d\n", n)
case n := <-c2:
fmt.Printf("server 2 generator %d\n", n)
case <-tick:
fmt.Println("定时每秒输出一次!")
}
}
2、超时
for {
tick := time.Tick(time.Second)
select {
case n := <-c1:
fmt.Printf("server 1 generator %d\n", n)
case n := <-c2:
fmt.Printf("server 2 generator %d\n", n)
case <-tick:
fmt.Println("定时每秒输出一次!")
case <-time.After(1300 * time.Millisecond): // 如果 1.3秒内没有数据进来,那么就输出超时
fmt.Println("timeout")
}
}
四、传统的并发控制
1、sync.Mutex
type atomicInt struct {
value int
lock sync.Mutex
}
func (a *atomicInt) increment() {
a.lock.Lock()
defer a.lock.Unlock() // 使用 defer 解锁,以防忘记
a.value++
}
func main() {
var a atomicInt
a.increment()
go func() {
a.increment()
}()
time.Sleep(time.Millisecond)
fmt.Println(a.value)
}
2、sync.WaitGroup
type waitGrouInt struct {
value int
wg sync.WaitGroup
}
func (w *waitGrouInt) addInt() {
w.wg.Add(1)
w.value++
}
func main() {
var w waitGrouInt
for i := 0; i < 10; i++ {
w.addInt()
w.wg.Done()
}
w.wg.Wait()
fmt.Println(w.value)
}
更多关于Go并发简明讲解请查看下面的相关链接
相关推荐
-
Golang极简入门教程(三):并发支持
Golang 运行时(runtime)管理了一种轻量级线程,被叫做 goroutine.创建数十万级的 goroutine 是没有问题的.范例: 复制代码 代码如下: package main import ( "fmt" "time" ) func say(s string) { for i := 0; i < 5; i++ { time.Sleep(100 * time.Millisecond)
-
详解Golang 中的并发限制与超时控制
前言 上回在 用 Go 写一个轻量级的 ssh 批量操作工具里提及过,我们做 Golang 并发的时候要对并发进行限制,对 goroutine 的执行要有超时控制.那会没有细说,这里展开讨论一下. 以下示例代码全部可以直接在 The Go Playground上运行测试: 并发 我们先来跑一个简单的并发看看 package main import ( "fmt" "time" ) func run(task_id, sleeptime int, ch chan st
-
Go语言如何并发超时处理详解
实现原理: 并发一个函数,等待1s后向timeout写入数据,在select中如果1s之内有数据向其他channel写入则会顺利执行,如果没有,这是timeout写入了数据,则我们知道超时了. 实现代码: package main import "fmt" import "time" func main() { ch := make(chan int, 1) timeout := make(chan bool, 1) // 并发执行一个函数,等待1s后向timeou
-
golang并发下载多个文件的方法
背景说明 假设有一个分布式文件系统,现需要从该系统中并发下载一部分文件到本地机器. 已知该文件系统的部分节点ip, 以及需要下载的文件fileID列表,并能通过这些信息来拼接下载地址. 其中节点ip列表保存在xx_node.txt, 要下载的fileID保存在xx_fileID.txt中. 代码示例 package main import ( "bufio" "flag" "fmt" "io" "math/rand&
-
使用google-perftools优化nginx在高并发时的性能的教程(完整版)
注意:本教程仅适用于Linux. 下面为大家介绍google-perftools的安装,并配置Nginx和MySQL支持google-perftools. 首先,介绍如何优化Nginx: 1,首先下载并安装google-perftools: 注意,如果是64位系统: 那么你需要做:1)先安装libunwind或者2)在configure时添加--enable-frame-pointers. 那么首先说说如何安装libunwind: 复制代码 代码如下: wget http://download.
-
golang实现并发数控制的方法
golang并发 谈到golang这门语言,很自然的想起了他的的并发goroutine.这也是这门语言引以为豪的功能点.并发处理,在某种程度上,可以提高我们对机器的使用率,提升系统业务处理能力.但是并不是并发量越大越好,太大了,硬件环境就会吃不消,反而会影响到系统整体性能,甚至奔溃.所以,在使用golang提供便捷的goroutine时,既要能够实现开启并发,也要学会如果控制并发量. 开启golang并发 golang开启并发处理非常简单,只需要在调用函数时,在函数前边添加上go关键字即可.如下
-
Golang 实现分片读取http超大文件流和并发控制
分片读取http超大文件流 Golang中的HTTP发送get请求,在获取内容有两种情况. Golang发送http get请求方式 resp, err := http.Get(sendUrl) if err != nil { fmt.Println("出错", err) return } 第一种方式是直接全部读取出来,这种方式在小数据量的时候很方便. body变量直接全部接收resp响应内容 body, err2 := ioutil.ReadAll(resp.Body) 第二种方式,
-
golang 并发安全Map以及分段锁的实现方法
涉及概念 并发安全Map 分段锁 sync.Map CAS ( Compare And Swap ) 双检查 分断锁 type SimpleCache struct { mu sync.RWMutex items map[interface{}]*simpleItem } 在日常开发中, 上述这种数据结构肯定不少见,因为golang的原生map是非并发安全的,所以为了保证map的并发安全,最简单的方式就是给map加锁. 之前使用过两个本地内存缓存的开源库, gcache, cache2go,其中
-
如何利用Golang写出高并发代码详解
前言 之前一直对Golang如何处理高并发http请求的一头雾水,这几天也查了很多相关博客,似懂非懂,不知道具体代码怎么写 下午偶然在开发者头条APP上看到一篇国外技术人员的一篇文章用Golang处理每分钟百万级请求,看完文章中的代码,自己写了一遍代码,下面自己写下自己的体会 核心要点 将请求放入队列,通过一定数量(例如CPU核心数)goroutine组成一个worker池(pool),workder池中的worker读取队列执行任务 实例代码 以下代码笔者根据自己的理解进行了简化,主要是表达出
-
golang中sync.Map并发创建、读取问题实战记录
背景: 我们有一个用go做的项目,其中用到了zmq4进行通信,一个简单的rpc过程,早期远端是使用一个map去做ip和具体socket的映射. 问题 大概是这样 struct SocketMap { sync.Mutex sockets map[string]*zmq4.Socket } 然后调用的时候的代码大概就是这样的: func (pushList *SocketMap) push(ip string, data []byte) { pushList.Lock() defer pushLi
-
Go语言并发技术详解
有人把Go比作21世纪的C语言,第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持了并行. goroutine goroutine是Go并行设计的核心.goroutine说到底其实就是线程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享.执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩.也正因为如此,可同时运行成千上万个并发任务.goro
-
Go 并发控制context实现原理剖析(小结)
1. 前言 Golang context是Golang应用开发常用的并发控制技术,它与WaitGroup最大的不同点是context对于派生goroutine有更强的控制力,它可以控制多级的goroutine. context翻译成中文是"上下文",即它可以控制一组呈树状结构的goroutine,每个goroutine拥有相同的上下文. 典型的使用场景如下图所示: 上图中由于goroutine派生出子goroutine,而子goroutine又继续派生新的goroutine,这种情况下
-

在Go中构建并发TCP服务器
开发一个并发TCP服务器,该服务器仅使用大约65行GO代码生成随机数. TCP和UDP服务器随处可见,通过TCP/IP网络为网络客户端提供服务.在本文中,我将在GO编程语言,返回随机数.对于来自TCP客户端的每个传入连接,TCP服务器将启动一个新的goroutine来处理该请求. 你可以找到这个项目,concTCP.go,在GitHub上. 处理TCP连接 程序的逻辑可以在handleConnection()职能,其实现方式如下: func handleConnection(c net.Conn
-
GO语言并发编程之互斥锁、读写锁详解
在本节,我们对Go语言所提供的与锁有关的API进行说明.这包括了互斥锁和读写锁.我们在第6章描述过互斥锁,但却没有提到过读写锁.这两种锁对于传统的并发程序来说都是非常常用和重要的. 一.互斥锁 互斥锁是传统的并发程序对共享资源进行访问控制的主要手段.它由标准库代码包sync中的Mutex结构体类型代表.sync.Mutex类型(确切地说,是*sync.Mutex类型)只有两个公开方法--Lock和Unlock.顾名思义,前者被用于锁定当前的互斥量,而后者则被用来对当前的互斥量进行解锁. 类型sy
-
Go并发调用的超时处理的方法
之前有聊过 golang 的协程,我发觉似乎还很理论,特别是在并发安全上,所以特结合网上的一些例子,来试验下go routine中 的 channel, select, context 的妙用. 场景-微服务调用 我们用 gin(一个web框架) 作为处理请求的工具,需求是这样的: 一个请求 X 会去并行调用 A, B, C 三个方法,并把三个方法返回的结果加起来作为 X 请求的 Response. 但是我们这个 Response 是有时间要求的(不能超过3秒的响应时间),可能 A, B, C
-
Go语言并发模型的2种编程方案
概述 我一直在找一种好的方法来解释 go 语言的并发模型: 不要通过共享内存来通信,相反,应该通过通信来共享内存 但是没有发现一个好的解释来满足我下面的需求: 1.通过一个例子来说明最初的问题 2.提供一个共享内存的解决方案 3.提供一个通过通信的解决方案 这篇文章我就从这三个方面来做出解释. 读过这篇文章后你应该会了解通过通信来共享内存的模型,以及它和通过共享内存来通信的区别,你还将看到如何分别通过这两种模型来解决访问和修改共享资源的问题. 前提 设想一下我们要访问一个银行账号: 复制代码 代
-
Go 并发实现协程同步的多种解决方法
go 简洁的并发 多核处理器越来越普及.有没有一种简单的办法,能够让我们写的软件释放多核的威力?是有的.随着Golang, Erlang, Scala等为并发设计的程序语言的兴起,新的并发模式逐渐清晰.正如过程式编程和面向对象一样,一个好的编程模式有一个极其简洁的内核,还有在此之上丰富的外延.可以解决现实世界中各种各样的问题.本文以GO语言为例,解释其中内核.外延. 前言 Java 中有一系列的线程同步的方法,go 里面有 goroutine(协程),先看下下面的代码执行的结果是什么呢? pac
-
golang gin 框架 异步同步 goroutine 并发操作
goroutine机制可以方便地实现异步处理 package main import ( "log" "time" "github.com/gin-gonic/gin" ) func main() { // 1.创建路由 // 默认使用了2个中间件Logger(), Recovery() r := gin.Default() // 1.异步 r.GET("/long_async", func(c *gin.Context) {