C++设计一个简单内存池的全过程
什么是内存池???
通常我们用new或malloc来分配内存的话,由于申请的大小不确定,所以当频繁的使用时会造成内存碎片和效率的降低。为了克服这种问题我们提出了内存池的概念。内存池是一种内存分配方式。内存池的优点就是可以有效的减少内存碎片化,分配内存更快速,减少内存泄漏等优点。
内存池是在真正使用内存之前,先申请分配一个大的内存块留作备用。当真正需要使用内存的时候,就从内存池中分配一块内存使用,当使这块用完了之后再还给内存池。若是内存块不够了就向内存再申请一块大的内存块。
可以看出这样做有两个好处:
1、由于向内存申请的内存块都是比较大的,所以能够降低外碎片问题。
2、一次性向内存申请一块大的内存慢慢使用,避免了频繁的向内存请求内存操作,提高内存分配的效率。
内存碎片化:
造成堆利用率很低的一个主要原因就是内存碎片化。如果有未使用的存储器,但是这块存储器不能用来满足分配的请求,这时候就会产生内存碎片化问题。内存碎片化分为内部碎片和外部碎片。
内碎片:
内部碎片是指一个已分配的块比有效载荷大时发生的。(举个栗子:假设以前分配了10个大小的字节,现在只用了5个字节,则剩下的5个字节就会内碎片)。内部碎片的大小就是已经分配的块的大小和他们的有效载荷之差的和。因此内部碎片取决于以前请求内存的模式和分配器实现的模式。

外碎片: 外部碎片就是当空闲的存储器的和计起来足够满足一个分配请求,但是没有一个单独的空闲块足够大可以处理这个请求。外部碎片取决于以前的请求内存的模式和分配器的实现模式,还取决于于将来的内存请求模式。所以外部碎片难以量化。
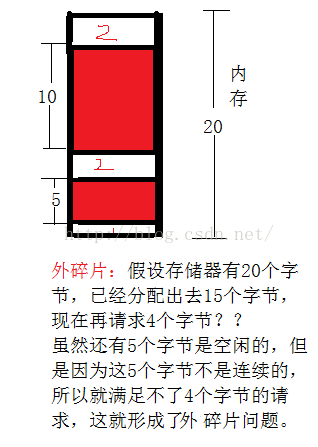
下面介绍一种简单的内存池,它是针对于某种对象实现的。 我们可以用一个链表实现这个内存池,链表上的每个结点都是一个对象池,如果我们需要申请空间的话,直接去内存池里面申请空间,当用完之后再还给内存池。

内存池的设计主要包含三步:
1、初始化
在创建内存池的时候为内存池分配了一块很大的内存,便于以后的使用。
2、分配内存
当需要内存的时候就去内存池里面分配内存。
3、回收内存
当从内存池里面分配来的内存使用完毕之后,需要将这块内存还给内存池。
设计上面这个内存池最重要的问题就是如何重复利用释放回来的内存,让利用率达到最高???

但是如果当对象的大小小于对象指针的时候,也就是一个对象的空间存不下一个指针的大小,这时候就不可避免的产生内碎片。 例如:为T类型对象开辟对象池,sizeof(T)<sizeof(T*),这时候我们就要为一个T类型对象申请sizeof(T*)大小的内存。
代码实现:
#pragma once
#include<iostream>
using namespace std;
//用链表来实现内存池,每一个结点都挂有一块内存
template<typename T>
class ObjectPool
{
struct BlockNode //每一个结点类型
{
void* _memory; //指向一块已经分配的内存
BlockNode * _next; //指向下一个结点
size_t _objNum; //记录这块内存中对象的个数
BlockNode(size_t objNum)
:_objNum(objNum)
, _next(NULL)
{
_memory = malloc(_objNum*_itemSize);
}
~BlockNode()
{
free(_memory);
_memory = NULL;
_next = NULL;
_objNum = 0;
}
};
protected:
size_t _countIn; //当前结点的在用的计数
BlockNode* _frist; //指向链表的头
BlockNode* _last; //指向链表的尾
size_t _maxNum; //记录内存块最大的容量
static size_t _itemSize; //单个对象的大小
T* _lastDelete; //指向最新释放的那个对象的空间
public:
ObjectPool(size_t initNum = 32, size_t maxNum = 100000) //默认最开始内存块有32个对象,一个内存块最大有maxNum个对象
:_countIn(0)
, _maxNum(maxNum)
, _lastDelete(NULL)
{
_frist = _last =new BlockNode(initNum); //先开辟一个结点,这个结点里面的内存块能够存放initNum个对象
}
~ObjectPool()
{
Destory();
}
T* New() //分配内存
{
if (_lastDelete) //先到释放已经用完并且换回来的内存中去找
{
T* object = _lastDelete;
_lastDelete = *((T**)_lastDelete); //将_lastDelete转换成T**,*引用再取出来T*,也就是取出前T*类型大小的单元
return new(object) T(); //把这块内存用从定位new初始化一下
}
//判断还有没有已经分配的内存且还未使用,如果没有内存的话就要再分配内存
if (_countIn >= _last->_objNum) //大于等于表示没有了,这时候就要分配内存了
{
size_t size =2*_countIn;
if (size > _maxNum) //块的最大大小不能超过maxNum,如果没超过就以二倍增长
size = _maxNum;
_last->_next = new BlockNode(size);
_last = _last->_next;
_countIn = 0;
}
//还有已经分配好的未被使用的内存
T* object =(T*)((char*)_last->_memory + _countIn*_itemSize);
_countIn++;
return new(object) T(); //将这块空间用重定位new初始化一下
}
void Destory()
{
BlockNode *cur = _frist;
while (cur)
{
BlockNode* del = cur;
cur = cur->_next;
delete del; //会自动调用~BlockNode()
}
_frist = _last = NULL;
}
void Delete(T* object) //释放内存
{
if (object)
{
object->~T();
*((T**)object) = _lastDelete; //将_lastDelete里面保存的地址存到tmp指向空间的前T*大小的空间里面
_lastDelete = object;
}
}
protected:
static size_t GetItemSize()
{
if (sizeof(T)>sizeof(T*))
{
return sizeof(T);
}
else
{
return sizeof(T*);
}
}
};
template<typename T>
size_t ObjectPool<T>::_itemSize =ObjectPool<T>::GetItemSize(); //类外初始化静态变量_itemSize
总结
到此这篇关于C++设计一个简单内存池的文章就介绍到这了,更多相关C++设计内存池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++高并发内存池的整体设计和实现思路
目录 一.整体设计 1.需求分析 2.总体设计思路 3.申请内存流程图 二.详细设计 1.各个模块内部结构详细剖析 2.设计细节 三.测试 一.整体设计 1.需求分析 池化技术是计算机中的一种设计模式,内存池是常见的池化技术之一,它能够有效的提高内存的申请和释放效率以及内存碎片等问题,但是传统的内存池也存在一定的缺陷,高并发内存池相对于普通的内存池它有自己的独特之处,解决了传统内存池存在的一些问题. 附:实现一个内存池管理的类方法 1)直接使用new/delete.malloc/free存在的问
-
C++设计一个简单内存池的全过程
什么是内存池??? 通常我们用new或malloc来分配内存的话,由于申请的大小不确定,所以当频繁的使用时会造成内存碎片和效率的降低.为了克服这种问题我们提出了内存池的概念.内存池是一种内存分配方式.内存池的优点就是可以有效的减少内存碎片化,分配内存更快速,减少内存泄漏等优点. 内存池是在真正使用内存之前,先申请分配一个大的内存块留作备用.当真正需要使用内存的时候,就从内存池中分配一块内存使用,当使这块用完了之后再还给内存池.若是内存块不够了就向内存再申请一块大的内存块. 可以看出这样做有两个好
-
Spring之借助Redis设计一个简单访问计数器的示例
为什么要做一个访问计数?之前的个人博客用得是卜算子做站点访问计数,用起来挺好,但出现较多次的响应很慢,再其次就是个人博客实在是访问太少,数据不好看
-
利用jQuery设计一个简单的web音乐播放器的实例分享
一.准备数据库 首先,我们设计MYSQL数据库如下: CREATE TABLE `songs` ( `song_id` int(11) NOT NULL AUTO_INCREMENT, `url` varchar(500) NOT NULL, `artist` varchar(250) NOT NULL, `title` varchar(250) NOT NULL, PRIMARY KEY (`song_id`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1 AU
-
C++如何实现定长内存池详解
目录 1. 池化技术 2. 内存池概念 2.1 内存碎片 3. 实现定长内存池 3.1 定位new表达式(placement-new) 3.2 完整实现 总结 1. 池化技术 池是在计算机技术中经常使用的一种设计模式,其内涵在于:将程序中需要经常使用的核心资源先申请出来,放到一个池内,由程序自己管理,这样可以提高资源的使用效率,也可以保证本程序占有的资源数量. 经常使用的池技术包括内存池.线程池和连接池(数据库经常使用到)等,其中尤以内存池和线程池使用最多. 2. 内存池概念 内存池(Memor
-
C++内存池的简单实现
目录 一.内存池基础知识 1.什么是内存池 1.1 池化技术 1.2 内存池 2.内存池的作用 2.1 效率问题 2.2 内存碎片 3.内存池技术的演进 二.简易内存池原理 1.整体设计 1.1 内存池结构 1.2 申请内存 1.3 释放内存 2.详细剖析 2.1 blockNode结构 2.2 单个对象的大小 3.性能比较 三.简易内存池完整源码 一.内存池基础知识 1.什么是内存池 1.1 池化技术 池化技术是计算机中的一种设计模式,主要是指:将程序中经常要使用的计算机资源预先申请出来,由程
-
C++高并发内存池的实现
目录 项目介绍 内存池介绍 定长内存池的实现 高并发内存池整体框架设计 threadcache threadcache整体设计 threadcache哈希桶映射对齐规则 threadcacheTLS无锁访问 centralcache centralcache整体设计 centralcache结构设计 centralcache核心实现 pagecache pagecache整体设计 pagecache中获取Span 申请内存过程联调 threadcache回收内存 centralcache回收内存
-
基于一个简单定长内存池的实现方法详解
主要分为 3 个部分,memoryPool 是管理内存池类,block 表示内存块,chunk 表示每个存储小块.它们之间的关系为,memoryPool 中有一个指针指向某一起始 block,block 之前通过 next 指针构成链表结构的连接,每个 block 包含指定数量的 chunk.每次分配内存的时候,分配 chunk 中的数据地址. 主要数据结构设计: Block: 复制代码 代码如下: struct block { block * next;//指向下一个block指针
-
java实现手写一个简单版的线程池
有些人可能对线程池比较陌生,并且更不熟悉线程池的工作原理.所以他们在使用线程的时候,多数情况下都是new Thread来实现多线程.但是,往往良好的多线程设计大多都是使用线程池来实现的. 为什么要使用线程 降低资源的消耗.降低线程创建和销毁的资源消耗.提高响应速度:线程的创建时间为T1,执行时间T2,销毁时间T3,免去T1和T3的时间提高线程的可管理性 下图所示为线程池的实现原理:调用方不断向线程池中提交任务:线程池中有一组线程,不断地从队列中取任务,这是一个典型的生产者-消费者模型. 要实现一
-
详解利用C语言如何实现简单的内存池
前言 在编程过程中,尤其是对于C语言开发者,其实编程就是在使用内存,不停地变化内存中的数据.当我们想开辟一片新的内存使用时,就会使用malloc实现.但是通过查阅很多资料,发现频繁的使用malloc并不是很好的选择.原因就是如果频繁的申请.释放内存,操作系统由于内存管理算法原因,导致出现内存碎片.其实产生碎片是一件很平常的事情,为何会这样,我想主要是内存利用率与性能的一个平衡.如果操作系统很抠门,肯定会把内存分配的逻辑算的很严密,"见缝插针"这四个字能很到的诠释内存分配策略.正因为见缝