SQL之Join的使用详解
一.基本概念
关于sql语句中的连接(join)关键字,是较为常用而又不太容易理解的关键字,下面这个例子给出了一个简单的解释 –建表user1,user2:
table1 : create table user2(id int, user_name varchar(10), over varchar(10));
insert into user1 values(1, ‘tangseng', ‘dtgdf');
insert into user1 values(2, ‘sunwukong', ‘dzsf');
insert into user1 values(1, ‘zhubajie', ‘jtsz');
insert into user1 values(1, ‘shaseng', ‘jslh');
table2 : create table user2(id int, user_name varchar(10), over varchar(10));
insert into user2 values(1, ‘sunwukong', ‘chengfo');
insert into user2 values(2, ‘niumowang', ‘chengyao');
insert into user2 values(3, ‘jiaomowang', ‘chengyao');
insert into user2 values(4, ‘pengmowang', ‘chengyao');
SQL标准中Join的类型
1. 内连接(inner join或join)
(1).概念:内联接是基于连接谓词将两张表的列结合在一起,产生新的结果表
(2).内连接维恩图:
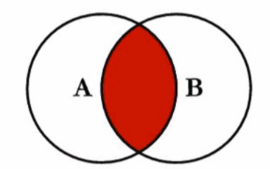
(3).sql语句
select a.id, a.user_name, b.over from user1 a inner join user2 b on a.user_name=b.user_name;
结果:

2. 外连接
外连接包括左向外联接、右向外联接或完整外部联接
a.左外连接:left join 或 left outer join
(1)概念:左向外联接的结果集包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值(null)。
(2)左外连接维恩图:
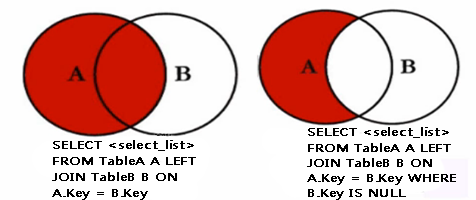
(3)sql语句:
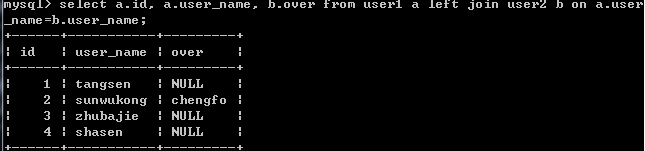
select a.id, a.user_name, b.over from user1 a left join user2 b on a.user_name=b.user_name;
结果:
b.右外连接:right join 或 right outer join
(1)右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
(2)右外连接维恩图:

(3)sql语句
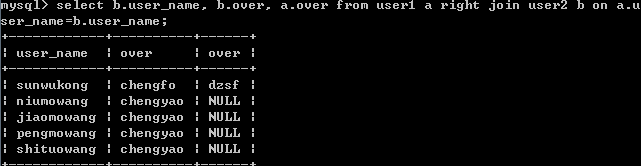
select b.user_name, b.over, a.over from user1 a right join user2 b on a.user_name=b.user_name;
结果:
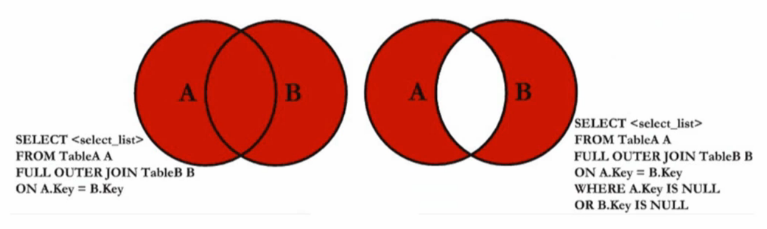
c.全外连接:full join 或 full outer join
(1)完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
(2)右外连接维恩图:
(3)sql语句
select a.id, a.user_name, b.over from user1 a full join user2 b on a.user_name=b.user_name
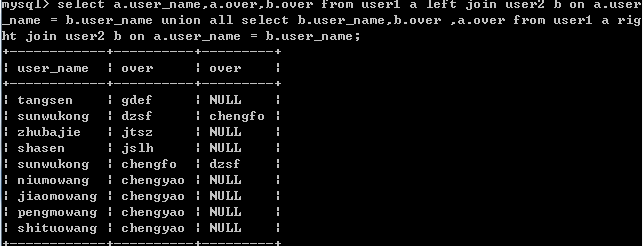
在mysql中查询全连接会报1064的错误,mysql不支持全连接查询,代替语句:
select a.user_name,a.over,b.over from user1 a left join user2 b on a.user_name = b.user_name union all select b.user_name,b.over ,a.over from user1 a right join user2 b on a.user_name = b.user_name;
结果:
3. 笛卡尔连接(交叉连接)
1.概念:没有 WHERE 子句的交叉联接将产生联接所涉及的表的笛卡尔积。第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小。(user1和user2交叉连接产生4*4=16条记录)
2.交叉连接:cross join (不带条件on)
3.sql语句:
select a.user_name,b.user_name, a.over, b.over from user1 a cross join user2 b;
二.使用技巧
1. 使用join更新表
我们使用下面语句将user1表中同时存在user1表和user2表中记录的over字段更新为 ‘qtda'。
update user1 set over='qtds'where user1.user_name in (select b.user_name from user1 a inner join user2 b on a.user_name = b.user_name);
这条语句在sql server, oracle中都可以正确执行,在mysql却报错,mysql不支持更新子查询的表,那么我们使用下面语句可以在做到。
update user1 a join (select b.user_name from user1 a join user2 b on a.user_name = b.user_name) b on a.user_name = b.user_name set a.over = ‘qtds'
2. 使用join优化子查询
子查询效率比较低效,使用下面语句进行查询
select a.user_name, a.over,(select over from user2 b where a.user_name=b.user_name) as over2 from user1 a;
使用join优化子查询,可以实现同样的效果
select a.user_name, a.over, b.over as over2 from user1 a left join user2
b on a.user_name = b.user_name;
3. 使用join优化聚合子查询
引入一张新表:user_kills
create table user_kills(user_id int, timestr varchar(20), kills int(10));
insert into user_kills values(2, ‘2015-5-12', 20);
insert into user_kills values(2, ‘2015-5-15', 18);
insert into user_kills values(3, ‘2015-5-11', 16);
insert into user_kills values(3, ‘2015-5-14', 13);
insert into user_kills values(3, ‘2015-5-16', 17);
insert into user_kills values(4, ‘2015-5-12', 16);
insert into user_kills values(4, ‘2015-5-10', 13);
查询user1中每人对应user_kills表中kills最大的日期,使用聚合子查询语句:
select a.user_name,b.timestr, b.kills from user1 a join user_kills b on a
.id = b.user_id where b.kills = (select MAX(c.kills) from user_kills c where c.user_id = b.user_id);
使用join优化聚合子查询(避免子查询)
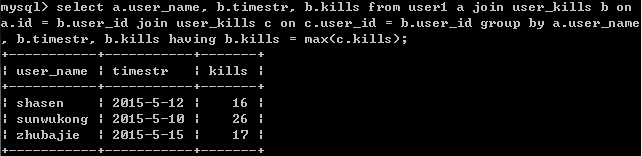
select a.user_name, b.timestr, b.kills from user1 a join user_kills b on
a.id = b.user_id join user_kills c on c.user_id = b.user_id group by a.user_name, b.timestr, b.kills having b.kills = max(c.kills);
结果:
4. 实现分组选择数据
要求查询出user1中每个人kills对多的前两天。
首先,我们可以通过下面语句查询出某个人kills最多的两天;
select a.user_name, b.timestr, b.kills from user1 a join user_kills b on
a.id = b.user_id where a.user_name ='sunwukong' order by b.kills desc limit 2;
那么如何通过一个语句查询出所有人kills最多的两天的呢?看下面的语句:
WITH tmp AS (select a.user_name, b.timestr, b.kills, ROW_NUMBER() over(partition by a.user_name order by b.kills) cnt from user1 a join user_kills b on a.id = b.user_id) select * from tmp where cnt <= 2;
上面的语句在sql server和oracle都是支持的,但是mysql不支持分组排序函数ROW_NUMBER(),下面提供一种替代方法:
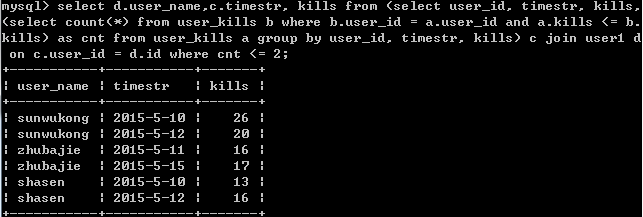
select d.user_name,c.timestr, kills from (select user_id, timestr, kills, (select count(*) from user_kills b where b.user_id = a.user_id and a.kills <= b.kills) as cnt from user_kills a group by user_id, timestr, kills) c join user1 d on c.user_id = d.id where cnt <= 2;
结果:
到此这篇关于SQL之Join的使用详解的文章就介绍到这了,更多相关SQL之Join内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SQL之Join的使用详解
一.基本概念 关于sql语句中的连接(join)关键字,是较为常用而又不太容易理解的关键字,下面这个例子给出了一个简单的解释 –建表user1,user2: table1 : create table user2(id int, user_name varchar(10), over varchar(10)); insert into user1 values(1, 'tangseng', 'dtgdf'); insert into user1 values(2, 'sunwukong', 'd
-
SQL update select结合语句详解及应用
QL update select语句 最常用的update语法是: UPDATE TABLE_NAME SET column_name1 = VALUE WHRER column_name2 = VALUE 如果我的更新值Value是从一条select语句拿出来,而且有很多列的话,用这种语法就很麻烦 第一,要select出来放在临时变量上,有很多个很难保存. 第二,再将变量进行赋值. 列多起来非常麻烦,能不能像Insert那样,把整个Select语句的结果进行插入呢? 就好象下面:: INSER
-

Apache Doris Join 优化原理详解
目录 背景 & 目标 Doris 数据划分 Partition Bucket Join 方式 总览 Broadcast / Shuffle Join Bucket Shuffle Join Plan Rule Colocate Join Runtime Filter 优化 Join Reorder 优化 Join 调优建议 背景 & 目标 掌握 Apache Doris Join 优化手段及其实现原理 为代码阅读提供理论基础 Doris 数据划分 不同的 Join 方式非常依赖于对 Dor
-
MyBatis 动态SQL和缓存机制实例详解
有的时候需要根据要查询的参数动态的拼接SQL语句 常用标签: - if:字符判断 - choose[when...otherwise]:分支选择 - trim[where,set]:字符串截取,其中where标签封装查询条件,set标签封装修改条件 - foreach: if案例 1)在EmployeeMapper接口文件添加一个方法 public Student getStudent(Student student); 2)如果要写下列的SQL语句,只要是不为空,就作为查询条件,如下所示,这样
-
JavaScript中push(),join() 函数 实例详解
定义和用法 push方法 可向数组的末尾添加一个或多个元素,并返回一个新的长度. join方法 用于把数组中所有元素添加到一个指定的字符串,元素是通过指定的分隔符进行分割的. 语法 arrayObject.push(newelement1,newelement2,....,newelementX) arrayObject.join(separator). 参数描述newelement1必需.要添加到数组的第一个元素.newelement2可选.要添加到数组的第二个元素.newelementX可选
-
javaScript之split与join的区别(详解)
共同点:split与join函数通常都是对字符或字符串的操作: 两者的区别: (1)split()用于分割字符串,返回一个数组, 例如 var string="hello world?name=xiaobai"; var splitString = string.split("?"); console.log(splitString);//["hello world","name=xiaobai"] split()只有一个参数
-
SQL的常用数据类型列表详解
数据类型 描述 CHARACTER(n) 字符/字符串.固定长度 n. VARCHAR(n) 或 CHARACTER VARYING(n) 字符/字符串.可变长度.最大长度 n. BINARY(n) 二进制串.固定长度 n. BOOLEAN 存储 TRUE 或 FALSE 值 VARBINARY(n) 或 BINARY VARYING(n) 二进制串.可变长度.最大长度 n. INTEGER(p) 整数值(没有小数点).精度 p. SMALLINT 整数值(没有小数点).精度 5. 存储数据的范
-
mybatis防止SQL注入的方法实例详解
SQL注入是一种很简单的攻击手段,但直到今天仍然十分常见.究其原因不外乎:No patch for stupid.为什么这么说,下面就以JAVA为例进行说明: 假设数据库中存在这样的表: table user( id varchar(20) PRIMARY KEY , name varchar(20) , age varchar(20) ); 然后使用JDBC操作表: private String getNameByUserId(String userId) { Connection conn
-
对python 多线程中的守护线程与join的用法详解
多线程:在同一个时间做多件事 守护线程:如果在程序中将子线程设置为守护线程,则该子线程会在主线程结束时自动退出,设置方式为thread.setDaemon(True),要在thread.start()之前设置,默认是false的,也就是主线程结束时,子线程依然在执行. thread.join():在子线程完成运行之前,该子线程的父线程(一般就是主线程)将一直存在,也就是被阻塞 实例: #!/usr/bin/python # encoding: utf-8 import threading fro
-
SQL中的开窗函数详解可代替聚合函数使用
在没学习开窗函数之前,我们都知道,用了分组之后,查询字段就只能是分组字段和聚合的字段,这带来了极大的不方便,有时我们查询时需要分组,又需要查询不分组的字段,每次都要又到子查询,这样显得sql语句复杂难懂,给维护代码的人带来很大的痛苦,然而开窗函数出现了,曙光也来临了.如果要想更具体了解开窗函数,请看书<程序员的SQL金典>,开窗函数在mysql不能使用. 开窗函数与聚合函数一样,都是对行的集合组进行聚合计算.它用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不