机器深度学习二分类电影的情感问题
二分类问题可能是应用最广泛的机器学习问题。今天我们将学习根据电影评论的文字内容将其划分为正面或负面。
一、数据集来源
我们使用的是IMDB数据集,它包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论。为了避免模型过拟合只记住训练数据,我们将数据集分为用于训练的25000条评论与用于测试的25000条评论,训练集和测试集都包含50%的正面评论和50%的负面评论。
与MNIST数据集一样,IMDB数据集也内置于Keras库。它已经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
通过以下代码加载数据集并限制每条评论最多取前一万个常用的word,以便于我们进行向量处理。
import tensorflow as tf imdb = tf.keras.datasets.imdb (train_data, train_labels),(test_data, test_labels) = imdb.load_data(num_words=10000) print(train_data[0]) print(train_labels[0])
通过输出可以看到,train_data和test_data是评论记录的集合,每条评论记录又是由众多的单词索引组成的集合。
train_labels和test_labels是针对评论的分类的集合,其中0表示负面评论,1表示正面评论。
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32] 1
我们可以通过word与编号的映射关系将评论的内容转化为具体的文本
def get_text(comment_num):
"""将数字形式的评论转化为文本"""
# word_index = tf.keras.datasets.imdb.get_word_index()
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
text = ' '.join([reverse_word_index.get(i - 3, '?') for i in comment_num])
return text
comment = get_text(train_data[0])
print(comment)
第一条电影评论的内容
? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ?
二、格式化输入数据
由于我们无法直接将整数序列输入神经网络,所以需要将其转换为张量。可以通过以下两种方式进行转化
填充列表,使其具有相同的长度,然后将列表转化为(samples, word_index)的2D形状的整数张量。对列表进行one-hot编码,将其转化为0和1组成的向量。
这里我们采用one-hot进行编码处理
def vectorize_sequences(sequences, diamension = 10000):
results = np.zeros((len(sequences), diamension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1
return results
x_train = vectorize_sequences(train_data)
print(x_train[0])
print(len(x_train[0]))
x_test = vectorize_sequences(test_data)
print(x_test[0])
print(len(x_test[0]))
转化完成的输入结果
[0. 1. 1. ... 0. 0. 0.]
10000
[0. 1. 1. ... 0. 0. 0.]
将标签进行向量化处理
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
三、构建神经网络
针对这里二分类单标签,我们可以直接使用带有relu激活函数的全连接层的简单堆叠。
我们使用了两个具有16个隐藏单元的中间层和具有一个隐藏单元的层。中间层使用的relu激活函数负责将所有的负值归零,最后一层使用sigmoid函数将任意值压缩到[0,1]之间并作为预测结果的概率。
model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
这里的Dense层实现了如下的张量计算,传入Dense层的参数16表示隐藏单元的个数,同时也表示这个层输出的数据的维度数量。隐藏单元越多,网络越能够学习到更加复杂的表示,但是网络计算的代价就越高。
output = relu(dot(W, input) + b)
我们使用rmsprop优化器和binary_crossentropy损失函数来配置模型。
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
四、训练模型
将训练数据分出一小部分作为校验数据,同时将512个样本作为一批量处理,并进行20轮的训练,同时出入validation_data来监控校验样本上的损失和计算精度。
x_val = x_train[:10000] partial_x_train = x_train[10000:] y_val = y_train[:10000] partial_y_train = y_train[10000:] history = model.fit(partial_x_train, partial_y_train, epochs= 20, batch_size=512, validation_data=(x_val, y_val))
调用fit()返回的history对象包含训练过程的所有数据
history_dict = history.history print(history_dict.keys())
字典中包含4个条目,对应训练过程和校验过程的指标,其中loss是训练过程中损失指标,accuracy是训练过程的准确性指标,而val_loss是校验过程的损失指标,val_accuracy是校验过程的准确性指标。
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
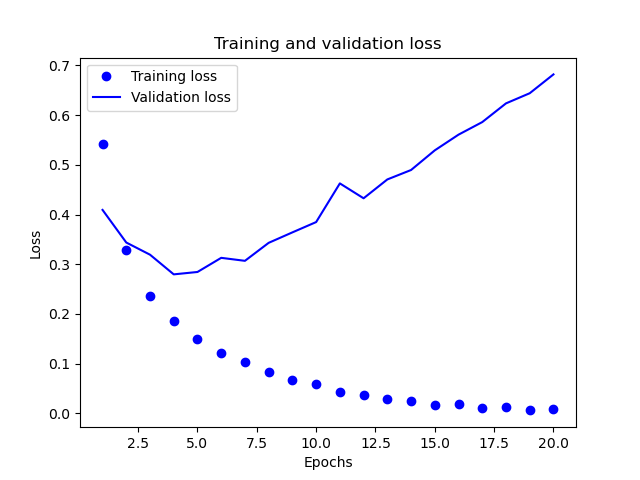
我们使用Matplotlib画出训练损失和校验损失的情况
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
从图中可以看到整个训练过程,损失函数值一直在不断的变小,但是校验过程的损失函数值却先变小后变大,在2.5-5之间的某个点达到最小值。
我们使用Matplotlib画出训练精度和校验精度的情况
plt.clf()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
从图中可以看到整个训练过程,准确度值一直在不断的升高,但是校验过程的精度数值却在不断的进行波动,在2.5-5之间的某个点达到最大值。
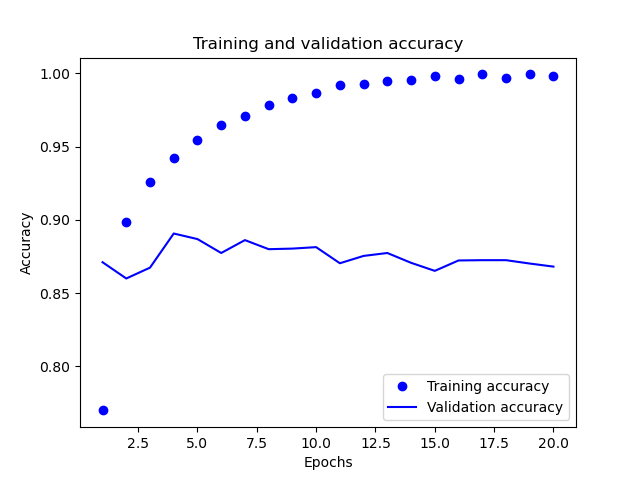
通过对训练和校验指标的分析,可以看到训练的损失每轮都在降低,训练的精度每轮都在提升。但是校验损失和校验精度基本上在第4轮左右达到最佳值。为了防止这种过拟合的情况,我们可以在第四轮完成之后直接停止训练。
history = model.fit(partial_x_train, partial_y_train, epochs= 4, batch_size=512, validation_data=(x_val, y_val)) results = model.evaluate(x_test, y_test) print(results)
重新执行可以看到模型的精度可以达到87%
782/782 [==============================] - 1s 876us/step - loss: 0.3137 - accuracy: 0.8729 [0.3137112557888031, 0.8728799819946289]
五、使用测试数据预测结果
使用训练的模型对test数据集进行预测
result = model.predict(x_test) print(result)
[[0.31683978]
[0.9997941 ]
[0.9842608 ]
...
[0.18170357]
[0.23360077]
六、小结
- 需要对原始数据进行预处理并转化为符合要求的张量。
- 对于二分类问题,最后一层使用sigmoid作为激活函数,并输出0-1的标量来表示结果出现的概率。
- 对于二分类问题的sigmoid标量输出,应该使用binary_crossentropy损失函数。
- 随着训练过程的进行,很容易出现过拟合现象,我们需要时刻监控模型在非训练数据集的表现。
到此这篇关于机器深度学习之电影的二分类情感问题的文章就介绍到这了,更多相关深度学习内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深度学习详解之初试机器学习
机器学习可应用在各个方面,本篇将在系统性进入机器学习方向前,初步认识机器学习,利用线性回归预测波士顿房价: 原理简介 利用线性回归最简单的形式预测房价,只需要把它当做是一次线性函数y=kx+b即可.我要做的就是利用已有数据,去学习得到这条直线,有了这条直线,则对于某个特征x(比如住宅平均房间数)的任意取值,都可以找到直线上对应的房价y,也就是模型的预测值. 从上面的问题看出,这应该是一个有监督学习中的回归问题,待学习的参数为实数k和实数b(因为就只有一个特征x),从样本集合sample中取出一对
-
吴恩达机器学习练习:神经网络(反向传播)
1 Neural Networks 神经网络 1.1 Visualizing the data 可视化数据 这部分我们随机选取100个样本并可视化.训练集共有5000个训练样本,每个样本是20*20像素的数字的灰度图像.每个像素代表一个浮点数,表示该位置的灰度强度.20×20的像素网格被展开成一个400维的向量.在我们的数据矩阵X中,每一个样本都变成了一行,这给了我们一个5000×400矩阵X,每一行都是一个手写数字图像的训练样本. import numpy as np import matpl
-
深度学习小工程练习之tensorflow垃圾分类详解
介绍 这是一个基于深度学习的垃圾分类小工程,用深度残差网络构建 软件架构 使用深度残差网络resnet50作为基石,在后续添加需要的层以适应不同的分类任务 模型的训练需要用生成器将数据集循环写入内存,同时图像增强以泛化模型 使用不包含网络输出部分的resnet50权重文件进行迁移学习,只训练我们在5个stage后增加的层 安装教程 需要的第三方库主要有tensorflow1.x,keras,opencv,Pillow,scikit-learn,numpy 安装方式很简单,打开terminal,例
-
深度学习tensorflow基础mnist
软件架构 mnist数据集的识别使用了两个非常小的网络来实现,第一个是最简单的全连接网络,第二个是卷积网络,mnist数据集是入门数据集,所以不需要进行图像增强,或者用生成器读入内存,直接使用简单的fit()命令就可以一次性训练 安装教程 使用到的主要第三方库有tensorflow1.x,基于TensorFlow的Keras,基础的库包括numpy,matplotlib 安装方式也很简答,例如:pip install numpy -i https://pypi.tuna.tsinghua.edu
-
机器深度学习二分类电影的情感问题
二分类问题可能是应用最广泛的机器学习问题.今天我们将学习根据电影评论的文字内容将其划分为正面或负面. 一.数据集来源 我们使用的是IMDB数据集,它包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论.为了避免模型过拟合只记住训练数据,我们将数据集分为用于训练的25000条评论与用于测试的25000条评论,训练集和测试集都包含50%的正面评论和50%的负面评论. 与MNIST数据集一样,IMDB数据集也内置于Keras库.它已经过预处理:评论(单词序列)已经被转换为整数序列,其中
-
Tensorflow深度学习使用CNN分类英文文本
目录 前言 源码与数据 源码 数据 train.py 源码及分析 data_helpers.py 源码及分析 text_cnn.py 源码及分析 前言 Github源码地址 本文同时也是学习唐宇迪老师深度学习课程的一些理解与记录. 文中代码是实现在TensorFlow下使用卷积神经网络(CNN)做英文文本的分类任务(本次是垃圾邮件的二分类任务),当然垃圾邮件分类是一种应用环境,模型方法也可以推广到其它应用场景,如电商商品好评差评分类.正负面新闻等. 源码与数据 源码 - data_helpers
-
理解深度学习之深度学习简介
机器学习 在吴恩达老师的课程中,有过对机器学习的定义: ML:<P T E> P即performance,T即Task,E即Experience,机器学习是对一个Task,根据Experience,去提升Performance: 在机器学习中,神经网络的地位越来越重要,实践发现,非线性的激活函数有助于神经网络拟合分布,效果明显优于线性分类器: y=Wx+b 常用激活函数有ReLU,sigmoid,tanh: sigmoid将值映射到(0,1): tanh会将输入映射到(-1,1)区间: #激活
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
使用TensorFlow实现二分类的方法示例
使用TensorFlow构建一个神经网络来实现二分类,主要包括输入数据格式.隐藏层数的定义.损失函数的选择.优化函数的选择.输出层.下面通过numpy来随机生成一组数据,通过定义一种正负样本的区别,通过TensorFlow来构造一个神经网络来实现二分类. 一.神经网络结构 输入数据:定义输入一个二维数组(x1,x2),数据通过numpy来随机产生,将输出定义为0或1,如果x1+x2<1,则y为1,否则y为0. 隐藏层:定义两层隐藏层,隐藏层的参数为(2,3),两行三列的矩阵,输入数据通过隐藏层之
-
浅谈keras中自定义二分类任务评价指标metrics的方法以及代码
对于二分类任务,keras现有的评价指标只有binary_accuracy,即二分类准确率,但是评估模型的性能有时需要一些其他的评价指标,例如精确率,召回率,F1-score等等,因此需要使用keras提供的自定义评价函数功能构建出针对二分类任务的各类评价指标. keras提供的自定义评价函数功能需要以如下两个张量作为输入,并返回一个张量作为输出. y_true:数据集真实值组成的一阶张量. y_pred:数据集输出值组成的一阶张量. tf.round()可对张量四舍五入,因此tf.round(
-
keras分类之二分类实例(Cat and dog)
1. 数据准备 在文件夹下分别建立训练目录train,验证目录validation,测试目录test,每个目录下建立dogs和cats两个目录,在dogs和cats目录下分别放入拍摄的狗和猫的图片,图片的大小可以不一样. 2. 数据读取 # 存储数据集的目录 base_dir = 'E:/python learn/dog_and_cat/data/' # 训练.验证数据集的目录 train_dir = os.path.join(base_dir, 'train') validation_dir
-
python 深度学习中的4种激活函数
这篇文章用来整理一下入门深度学习过程中接触到的四种激活函数,下面会从公式.代码以及图像三个方面介绍这几种激活函数,首先来明确一下是哪四种: Sigmoid函数 Tahn函数 ReLu函数 SoftMax函数 激活函数的作用 下面图像A是一个线性可分问题,也就是说对于两类点(蓝点和绿点),你通过一条直线就可以实现完全分类. 当然图像A是最理想.也是最简单的一种二分类问题,但是现实中往往存在一些非常复杂的线性不可分问题,比如图像B,你是找不到任何一条直线可以将图像B中蓝点和绿点完全分开的,你必须圈出
-
Python深度学习之图像标签标注软件labelme详解
前言 labelme是一个非常好用的免费的标注软件,博主看了很多其他的博客,有的直接是翻译稿,有的不全面.对于新手入门还是有点困难.因此,本文的主要是详细介绍labelme该如何使用. 一.labelme是什么? labelme是图形图像注释工具,它是用Python编写的,并将Qt用于其图形界面.说直白点,它是有界面的, 像软件一样,可以交互,但是它又是由命令行启动的,比软件的使用稍微麻烦点.其界面如下图: 它的功能很多,包括: 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目
-
Python深度学习之简单实现猫狗图像分类
一.前言 本文使用的是 kaggle 猫狗大战的数据集 训练集中有 25000 张图像,测试集中有 12500 张图像.作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可. 通过使用更大.更复杂的模型,可以获得更高的准确率,预训练模型是一个很好的选择,我们可以直接使用预训练模型来完成分类任务,因为预训练模型通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务. tf.keras.applications中有一些预定义好的经典卷积神经网络结构(Applic