一个关于JS正则匹配的踩坑记录
最近发现在JS里的正则匹配有一个坑,而且当时很莫名奇妙,一度让我怀疑出现了灵异事件。
下面是踩坑代码
var str=["二七1","二七2","金水","二七3","二七4","二七5"]
var reg=new RegExp("二七","g");
for(var i=0;i<str.length;i++){
if(reg.test(str[i])){
console.log(str[i])
}
}
我用正则对str进行全局匹配,当满足的时候打印出来,于是乎我就得到了这个

莫名的少了两个,然后我对它进行单独的判断
var str=["二七1","二七2","金水","二七3","二七4","二七5"]
var reg=new RegExp("二七","g");
for(var i=0;i<str.length;i++){
if(reg.test(str[i])){
console.log(str[i])
}
if(i==1){
console.log(reg.test(str[i]))
}
if(i==4){
console.log(reg.test(str[i]))
}
}
于是我得到了这个
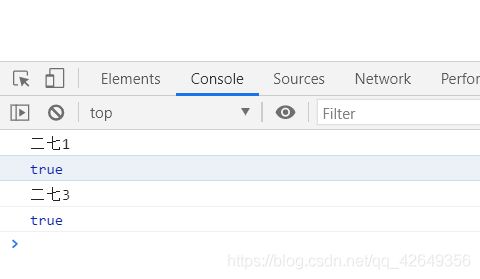
又少了一个,但可以看到之前所缺失的两个是满足正则判断的,然后我在网上找到了下面这段话:
如果在正则匹配中成功匹配到字符串,lastIndex会被设置为第一次匹配到的字符串的位置,以作为字符串全局匹配下次检索的起点,如果后面字段还能匹配成功,那么lastIndex会被反复重新赋值,直到匹配失败,它会被重置为0;
但我去请教了一下我的老师,他告诉我的是匹配到后是将lastIndex+1返回过去,也就是当我第一次匹配到后,lastIndex是2,这个2是字符串里的下标,而不是数组的下标,所以在对str[1]进行判断时是从字符串下标为2的开始,而不是从0开始,所以第二次判断为false,这时匹配失败,lastIndex被置为0,所以第三次可以匹配成功。
所以在判断结果为true后将lastIndex置为0,这样数据就正常了。
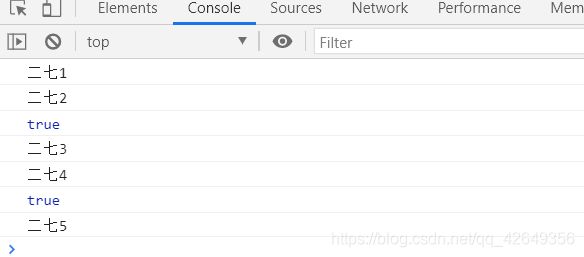
数据就正常了。
总结
如果使用全局匹配,那么在每一次查到后将lastIndex置零,或者不使用全局匹配,直接匹配即可。
这里奉上网友的总结:
lastIndex从字面上来讲就是最后一个索引,实际上它的意思是正则表达式开始下一次查找的索引位置,第一次的时候总是为0的,第一次查找完了的时候会把lastIndex的值设为匹配到得字符串的最后一个字符的索引位置加1,第二次查找的时候会从lastIndex这个位置开始,后面的以此类推。如果没有找到,则会把lastIndex重置为0。要注意的是,lastIndex属性只有在有全局标志正则表达式中才有作用,如果我们把上面代码中正则表达式的g标志去掉,那么三次弹出的就都是true了。
需要的朋友可以参考下,到此这篇关于一个关于JS正则匹配的踩坑记录的文章就介绍到这了,更多相关JS正则匹配踩坑内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
正则匹配密码只能是数字和字母组合字符串功能【php与js实现】
本文实例讲述了正则匹配密码只能是数字和字母组合字符串功能.分享给大家供大家参考,具体如下: 密码要求: 1. 不能全部是数字 2. 不能全部是字母 3. 必须是数字和字母组合 4. 不包含特殊字符 5. 密码长度6-30位的字符串 /** * @desc get_pwd_strength()im:根据密码字符串判断密码结构 * @param (string)$mobile * return 返回:$msg */ function get_pwd_strength($pwd){ if (strle
-

js 正则表达式学习笔记之匹配字符串
今天看了第5章几个例子,有点收获,记录下来当作回顾也当作分享. 关于匹配字符串问题,有很多种类型,今天讨论 js 代码里的字符串匹配.(因为我想学完之后写个语法高亮练手,所以用js代码当作例子) 复制代码 代码如下: var str1 = "我是字符串1哦,快把我取走", str2 = "我是字符串2哦,快把我取走"; 比如这样一个字符串,匹配起来很简单 /"[^"]*"/g 即可. PS: 白色截图是 chrome 34 控制台中
-
js正则学习小记之匹配字符串字面量
今天看了第5章几个例子,有点收获,记录下来当作回顾也当作分享. 关于匹配字符串问题,有很多种类型,今天讨论 js 代码里的字符串匹配.(因为我想学完之后写个语法高亮练手,所以用js代码当作例子) var str1 = "我是字符串1哦,快把我取走", str2 = "我是字符串2哦,快把我取走"; 比如这样一个字符串,匹配起来很简单 /"[^"]*"/g 即可. PS: 白色截图是 chrome 34 控制台中运行的结果,深灰色是 su
-
String字符串匹配javascript 正则表达式
在JavaScript代码中使用正则表达式进行模式匹配经常会用到String对象和RegExp对象的一些方法,例如replace.match.search等方法,下面所述是对相关方法使用的总结,需要的朋友参考下. String对象中支持正则表达式有4种方法,分别是:search.replace.match.split str.search(regexp) 定义:search()方法将在字符串str中检索与表达式regexp相匹配的字串,并且返回第一个匹配字串的第一个字符的位置.如果没有找到任何匹
-
JavaScript正则表达式匹配字符串字面量
第一次遇到这个问题, 是大概两年前写代码高亮, 从当时的解决方案到现在一共有三代, 嘎嘎. 觉得还是算越来越好的. 第一代: //那个时候自己正则还不算很精通, 也没有(?:...)这种习惯, 是以寻找结束引号为入口写出的这个正则. 思路混乱, 也存在错误. //比如像字面量 "abc\\\"", 则会匹配为 "abc\\\", 而正确的结果应该是 "abc\\\"". var re = /('('|.*?([^\\]'|\\
-
js 正则学习小记之匹配字符串字面量优化篇
昨天在<js 正则学习小记之匹配字符串字面量>谈到 /"(?:\\.|[^"])*"/ 是个不错的表达式,因为可以满足我们的要求,所以这个表达式可用,但不一定是最好的. 从性能上来说,他非常糟糕,为什么这么说呢,因为 传统型NFA引擎 遇到分支是从左往右匹配的, 所以它会用 \\. 去匹配每一个字符,发现不对后才用 [^"] 去匹配. 比如这样一个字符串: "123456\'78\"90" 共 16 个字符,除了第一个 &q
-
一个关于JS正则匹配的踩坑记录
最近发现在JS里的正则匹配有一个坑,而且当时很莫名奇妙,一度让我怀疑出现了灵异事件. 下面是踩坑代码 var str=["二七1","二七2","金水","二七3","二七4","二七5"] var reg=new RegExp("二七","g"); for(var i=0;i<str.length;i++){ if(reg.test(str
-
JS正则匹配中文的方法示例
本文实例讲述了JS正则匹配中文的方法.分享给大家供大家参考,具体如下: 需求:使用JS正则的方式将字符串 "[微笑][撇嘴][发呆][得意][流泪]" 中的汉字进行匹配输出. 示例代码: <script> var pattern1 = /[\u4e00-\u9fa5]+/g; var pattern2 = /\[[\u4e00-\u9fa5]+\]/g; var contents = "[微笑][撇嘴][发呆][得意][流泪]"; content = c
-
js正则匹配出所有图片及图片地址src的方法
本文实例讲述了js正则匹配出所有图片及图片地址src的方法.分享给大家供大家参考.具体分析如下: 有很多时候我们需要用到文章里面的图片,而且主要是用到它的图片地址,这个时候我们需要通过正则匹配出图片标签,然后做到我们需要的数据 平时也没怎么用正则,一不学就忘,最近项目需要,然后又去goole了,好乱!一搜一大堆,也不是我想要的,最后把自己留一个已被后用: 实现:通过js正则匹配出所有图片及所有图片地址src. 思路:1.匹配出图片img标签(即匹配出所有图片),过滤其他不需要的字符 从匹配出来的
-
js正则匹配table,img及去除各种标签问题
核心代码 //获取公示栏内容 s = "$row.detail$"; mainContent =s; //如果有多个table使用下面注释的正则只会匹配成一个table //var tabReg = /<table[^>]*>((?!table).)*<\/table>/gi; //匹配单个table var tabReg = /<table[^>]*>\s*(<tbody[^>]*>)?(\s*<tr[^>
-
js正则匹配markdown里的图片标签的实现
其实前端后端需要将markdown文本转换为html文本都有相应的库,几句代码就ok,但有时我们又必须获取到markdown里的某个标签来进行相应的转换,有几种办法,可以从已经转换好的html文本里获取,还有的就是直接从markdown文本里获取,这里说的是第二种. 1. 一个markdown里只有一个图片的情况 const str = "asddsadasdasddasd"; //一段markdown文本,包含一个图片""
-
JS正则匹配URL网址的方法(可匹配www,http开头的一切网址)
本文实例讲述了JS正则匹配URL网址的方法.分享给大家供大家参考,具体如下: 最强的匹配网址-url的正则表达式:匹配www,http开头的一切网址 直接插入正则表达式: [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? 完整的js方法: function isURL(domain) { var name = /[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z
-
js正则匹配多个全部数据问题
需求:获取所有title里的内容 正则表达式后面加g表示多次匹配 方式一:match 返回数组 方式二 exec <script> var str='<a href="//www.aliexpress.com/store/product/OOOT-BAORJCT-174296-22mm-10yard-lot-cartoon-Ribbons-Thermal-transfer-Printed-grosgrain-Wedding-Accessories-DIY-handmade/23
-
Echarts在Taro微信小程序开发中的踩坑记录
背景 近期笔者在使用Taro进行微信小程序开发,当引入Echarts图表库时,微信检测单包超限2M的一系列优化措施的踩坑记录,期望能指导读者少走一些弯路. 为什么选择Echarts? 微信小程序目录市面上使用最多的两款图表库,如下: echarts-for-weixin--echarts微信小程序版本 wx-charts--基于微信小程序的图表库 对比两款图表库优缺点刚好相反. echarts-for-weixin:功能强大,但体积非常大 wx-charts:功能相对简单,但体积小 由于笔者对e
-
JavaScript深拷贝的一些踩坑记录
前言 之前去一家公司面试的时候,面试官问了我一个问题,说:"如何才能深拷贝一个对象".当时我心里有些窃喜,这么简单的问题还用想吗?于是脱口而出:"平时常用的有两种办法,第一种用JSON.parse(JSON.stringify(obj)),第二种可以使用for...in加递归完成".面试官听了以后点了点头觉得挺满意的. 当时我也并没有太过在乎这个问题,直到前段时间又想起这个问题,发现上面说的两种方法都是有Bug的. 提出问题 那么上面所说的Bug是什么呢? 特殊对象
-
关于Vue3过渡动画的踩坑记录
目录 背景 问题定位 进一步分析 总结 背景 在我的 <Vue 3 开发企业级音乐 App>课程问答区,有个同学提了个问题,在歌手列表到歌手详情页面到转场动画中,只有进入动画,却没有离场动画: 该学生确实在这个问题上研究了有一段时间,而且从他的描述,我一时半会儿也想不出哪有问题,于是让他把代码传到 GitHub 上,毕竟直接从代码层面定位问题是最靠谱的. 问题定位 一般遇到此类问题的时候,我的第一反应是他用的 Vue 3 版本可能有问题,毕竟 Vue 3 还在不断迭代过程,某个版本有一些小 b