详解Dijkstra算法原理及其C++实现
目录
- 什么是最短路径问题
- Dijkstra算法
- 实现思路
- 案例分析
- 代码实现
什么是最短路径问题
如果从图中某一顶点(称为源点)到达另一顶点(称为终点)的路径可能不止一条,如何找到一条路径使得沿此路径上各边上的权值总和达到最小。
单源最短路径问题是指对于给定的图G=(V,E),求源点v0到其它顶点vt的最短路径。
Dijkstra算法
Dijkstra算法用于计算一个节点到其他节点的最短路径。Dijkstra是一种按路径长度递增的顺序逐步产生最短路径的方法,是一种贪婪算法。
Dijkstra算法的核心思想是首先求出长度最短的一条最短路径,再参照它求出长度次短的一条最短路径,依次类推,直到从源点v0到其它各顶点的最短路径全部求出为止。
具体来说:图中所有顶点分成两组,第一组是已确定最短路径的顶点,初始只包含一个源点,记为集合S;第二组是尚未确定最短路径的顶点,记为集合U。
按最短路径长度递增的顺序逐个把U中的顶点加到S中去,同时动态更新U集合中源点到各个顶点的最短距离,直至所有顶点都包括到S中。
实现思路
1.初始时,S集合只包含起点v0;U集合包含除v0外的其他顶点vt,且U中顶点的距离为起点v0到该顶点的距离。(U 中顶点vt的距离为(v0,vt)的长度,如果v0和vt不相邻,则vt的最短距离为∞)
2.从U中选出距离最短的顶点vt′,并将顶点vt′加入到S中;同时,从U中移除顶点vt′。
3.更新U中各个顶点vt到起点v0的距离以及最短路径中当前顶点的前驱顶点。之所以更新U中顶点的距离以及前驱顶点是由于上一步中确定了vt′是求出最短路径的顶点,从而可以利用vt′来更新U中其它顶点vt的距离,因为存在(v0,vt)的距离可能大于(v0,vt')+(vt',vt)距离的情况,从而也需要更新其前驱顶点
4.重复步骤(2)和(3),直到遍历完所有顶点
案例分析


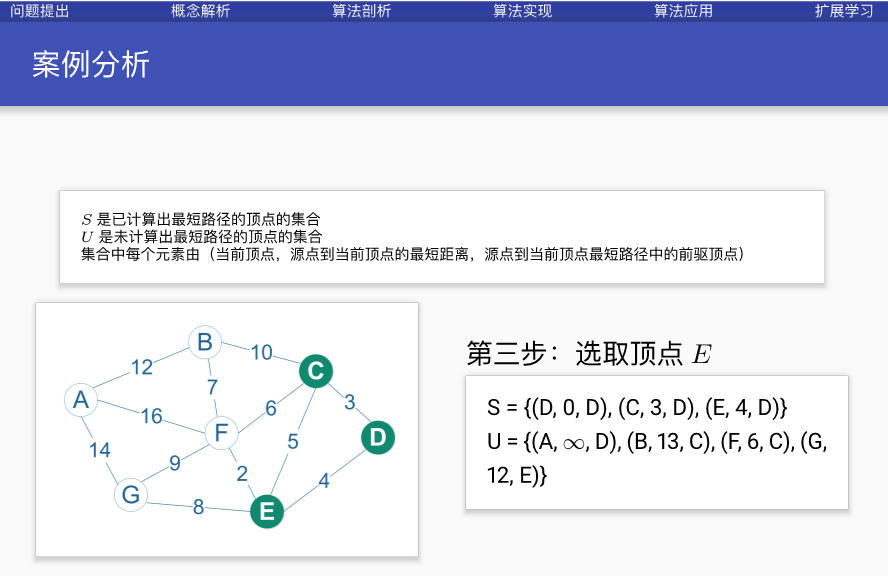




代码实现
使用了部分C++11特性,注释丰富,读起来应该不会太困难!
#include <cstdio>
#include <iostream>
#include <vector>
#include <list>
#include <stack>
using namespace std;
using Matrix = vector<vector<uint>>; // 连接矩阵(使用嵌套的vector表示)
using SNodes = vector<tuple<uint, uint, uint>>; // 已计算出最短路径的顶点集合S(类似一个动态数组)
using UNodes = list<tuple<uint, uint, uint>>; // 未进行遍历的顶点集合U(使用list主要是方便元素删除操作)
using ENode = tuple<uint, uint, uint>; // 每个节点包含(顶点编号,当前顶点到起始点最短距离,最短路径中当前顶点的上一个顶点)信息
/***
* 从未遍历的U顶点集合中找到下一个离起始顶点距离最短的顶点
* @param unvisitedNodes 未遍历的U顶点集合
* 每个元素是(顶点编号,当前顶点到起始点最短距离,最短路径中当前顶点的上一个顶点)的tuple
* @return 下一个离起始顶点距离最短的顶点
*/
ENode searchNearest(const UNodes &unvisitedNodes) {
uint minDistance = UINT_MAX;
ENode nearest;
for (const auto &node: unvisitedNodes) {
if (get<1>(node) <= minDistance) {
minDistance = get<1>(node);
nearest = node;
}
}
return nearest;
}
/***
* 迪克斯特拉算法的实现
* @param graph 连接矩阵(使用嵌套的vector表示)
* @param startNodeIndex 起始点编码(从0开始)
* @return 返回一个vector,每个元素是到起始顶点的距离排列的包含(顶点编号,当前顶点到起始点最短距离,最短路径中当前顶点的上一个顶点)的tuple
*/
SNodes dijkstra(const Matrix &graph, uint startNodeIndex) {
const uint numOfNodes = graph.size(); // 图中顶点的个数
// S是已计算出最短路径的顶点的集合(顶点编号,当前顶点到起始点最短距离,最短路径中当前顶点的上一个顶点)
SNodes visitedNodes;
// U是未计算出最短路径的顶点的集合(其中的key为顶点编号,value为到起始顶点最短距离和最短路径中上一个节点编号组成的pair)
UNodes unvisitedNodes;
// 对S和U集合进行初始化,起始顶点的距离为0,其他顶点的距离为无穷大
// 最短路径中当前顶点的上一个顶点初始化为起始顶点,后面会逐步进行修正
for (auto i = 0; i < numOfNodes; ++i) {
if (i == startNodeIndex) visitedNodes.emplace_back(i, 0, startNodeIndex);
else unvisitedNodes.emplace_back(i, graph[startNodeIndex][i], startNodeIndex);
}
while (!unvisitedNodes.empty()) {
// 从U中找到距离起始顶点距离最短的顶点,加入S,同时从U中删除
auto nextNode = searchNearest(unvisitedNodes);
unvisitedNodes.erase(find(unvisitedNodes.begin(), unvisitedNodes.end(), nextNode));
visitedNodes.emplace_back(nextNode);
// 更新U集合中各个顶点的最短距离以及最短路径中的上一个顶点
for (auto &node: unvisitedNodes) {
// 更新的判断依据就是起始顶点到当前顶点(nextNode)距离加上当前顶点到U集合中顶点的距离小于原来起始顶点到U集合中顶点的距离
// 更新最短距离的时候同时需要更新最短路径中的上一个顶点为nextNode
if (graph[get<0>(nextNode)][get<0>(node)] != UINT_MAX &&
graph[get<0>(nextNode)][get<0>(node)] + get<1>(nextNode) < get<1>(node)) {
get<1>(node) = graph[get<0>(nextNode)][get<0>(node)] + get<1>(nextNode);
get<2>(node) = get<0>(nextNode);
}
}
}
return visitedNodes;
}
/***
* 对使用迪克斯特拉算法求解的最短路径进行打印输出
* @param paths vector表示的最短路径集合
* 每个元素是到起始顶点的距离排列的包含(顶点编号,当前顶点到起始点最短距离,最短路径中当前顶点的上一个顶点)的tuple
*/
void print(const SNodes &paths) {
stack<int> tracks; //从尾部出发,使用stack将每个顶点的最短路径中的前一个顶点入栈,然后出栈的顺序就是最短路径顺序
// 第一个元素是起始点,从第二个元素进行打印输出
for (auto it = ++paths.begin(); it != paths.end(); ++it) {
// 打印头部信息
printf("%c -> %c:\t Length: %d\t Paths: %c",
char(get<0>(paths[0]) + 65),
char(get<0>(*it) + 65),
get<1>(*it),
char(get<0>(paths[0]) + 65));
auto pointer = *it;
// 如果当前指针pointer指向的节点有中途节点(判断的条件是最短路径中的前一个节点不是起始点)
while (get<2>(pointer) != get<0>(paths[0])) {
tracks.push(get<0>(pointer));
// Lambda表达式,使用find_if函数把当前顶点的前一个顶点从paths中找出来继续进行循环直到前一个节点就是起始点
auto condition = [pointer](tuple<uint, uint, uint> x) { return get<0>(x) == get<2>(pointer); };
pointer = *find_if(paths.begin(), paths.end(), condition);
}
tracks.push(get<0>(pointer));
// 以出栈的顺序进行打印输出
while (!tracks.empty()) {
printf(" -> %c", char(tracks.top() + 65));
tracks.pop();
}
printf("\n");
}
}
int main() {
Matrix graph = {
{0, 12, UINT_MAX, UINT_MAX, UINT_MAX, 16, 14},
{12, 0, 10, UINT_MAX, UINT_MAX, 7, UINT_MAX},
{UINT_MAX, 10, 0, 3, 5, 6, UINT_MAX},
{UINT_MAX, UINT_MAX, 3, 0, 4, UINT_MAX, UINT_MAX},
{UINT_MAX, UINT_MAX, 5, 4, 0, 2, 8},
{16, 7, 6, UINT_MAX, 2, 9, 9},
{14, UINT_MAX, UINT_MAX, UINT_MAX, 8, 9, 0}
}; // 图对应的连接矩阵
auto results = dijkstra(graph, uint('D' - 65)); // 选取顶点C(大写字母A的ASCII编码是65)
print(results); // 打印输出结果
return 0;
}
运行结果:
D -> C: Length: 3 Paths: D -> C
D -> E: Length: 4 Paths: D -> E
D -> F: Length: 6 Paths: D -> E -> F
D -> G: Length: 12 Paths: D -> E -> G
D -> B: Length: 13 Paths: D -> C -> B
D -> A: Length: 22 Paths: D -> E -> F -> A
以上就是详解Dijkstra算法原理及其C++实现的详细内容,更多关于C++ Dijkstra算法的资料请关注我们其它相关文章!
相关推荐
-

C++实现Dijkstra算法的示例代码
目录 一.算法原理 二.具体代码 1.graph类 2.PathFinder类 3. main.cpp 三.示例 一.算法原理 链接: Dijkstra算法及其C++实现参考这篇文章 二.具体代码 1.graph类 graph类用于邻接表建立和保存有向图. graph.h: #ifndef GRAPH_H #define GRAPH_H #include <iostream> #include <string> #include <vector> #include &l
-
C++用Dijkstra(迪杰斯特拉)算法求最短路径
算法介绍 迪杰斯特拉算法是由荷兰计算机科学家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉算法.是从一个顶点到其余各顶点的最短路径算法,解决的是有向图中最短路径问题.迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低. 算法思想 按路径长度递增次序产生算法: 把顶点集合V分成两组: (1)S:已求出的顶点的集合(初始时只含有源点V0) (2)V-S=T:尚未确定的顶点集合 将T中顶点按递增
-
C++实现Dijkstra算法
本文实例为大家分享了C++实现Dijkstra算法的具体代码,供大家参考,具体内容如下 #include <iostream> #include <limits> using namespace std; struct Node { //定义表结点 int adjvex; //该边所指向的顶点的位置 int weight;// 边的权值 Node *next; //下一条边的指针 }; struct HeadNode{ // 定义头结点 int nodeName; // 顶点信息
-
Dijkstra算法最短路径的C++实现与输出路径
某个源点到其余各顶点的最短路径 这个算法最开始心里怕怕的,不知道为什么,花了好长时间弄懂了,也写了一遍,又遇到时还是出错了,今天再次写它,心里没那么怕了,耐心研究,懂了之后会好开心的,哈哈 Dijkstra算法: 图G 如图:若要求从顶点1到其余各顶点的最短路径,该咋求: 迪杰斯特拉提出"按最短路径长度递增的次序"产生最短路径. 首先,在所有的这些最短路径中,长度最短的这条路径必定只有一条弧,且它的权值是从源点出发的所有弧上权的最小值,例如:在图G中,从源点1出发有3条弧,其中以弧(1
-
C++简单实现Dijkstra算法
本文实例为大家分享了C++简单实现Dijkstra算法的具体代码,供大家参考,具体内容如下 // Dijkstra.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> #include <stack> #define MAX_VALUE 1000 using namespace std; struct MGraph { int *edges[MAX_VALUE]; int iVertex
-
C++实现Dijkstra(迪杰斯特拉)算法
Dijkstra算法 Dijkstra(迪杰斯特拉)算法是典型的最短路径路由算法,是广度优先算法的一种,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.其基本原理是:每次新扩展一个距离最短的点,更新与其相邻的点的距离.当所有边权都为正时,由于不会存在一个距离更短的没扩展过的点,所以这个点的距离永远不会再被改变,因而保证了算法的正确性.不过根据这个原理,用Dijkstra求最短路的图不能有负权边,因为扩展到负权边的时候会产生更短的距离,有可能就破
-
详解Dijkstra算法原理及其C++实现
目录 什么是最短路径问题 Dijkstra算法 实现思路 案例分析 代码实现 什么是最短路径问题 如果从图中某一顶点(称为源点)到达另一顶点(称为终点)的路径可能不止一条,如何找到一条路径使得沿此路径上各边上的权值总和达到最小. 单源最短路径问题是指对于给定的图G=(V,E),求源点v0到其它顶点vt的最短路径. Dijkstra算法 Dijkstra算法用于计算一个节点到其他节点的最短路径.Dijkstra是一种按路径长度递增的顺序逐步产生最短路径的方法,是一种贪婪算法. Dijkstra算法
-
详解Dijkstra算法之最短路径问题
一.最短路径问题介绍 问题解释: 从图中的某个顶点出发到达另外一个顶点的所经过的边的权重和最小的一条路径,称为最短路径 解决问题的算法: 迪杰斯特拉算法(Dijkstra算法) 弗洛伊德算法(Floyd算法) SPFA算法 这篇博客,我们就对Dijkstra算法来做一个详细的介绍 二.Dijkstra算法介绍 2.1.算法特点 迪科斯彻算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树.该算法常用于路由算法或者作为其他图算法的一个子模块. 2.2.算法的
-
图文详解感知机算法原理及Python实现
目录 写在前面 1.什么是线性模型 2.感知机概述 3.手推感知机原理 4.Python实现 4.1 创建感知机类 4.2 更新权重与偏置 4.3 判断误分类点 4.4 训练感知机 4.5 动图可视化 5.总结 写在前面 机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用.“深”在详细推导算法模型背后的数学原理:“广”在分析多个机器学习模型:决策树.支持向量机.贝叶斯与马尔科夫决策.强化学习等. 本期目标:实现这样一个效果 1.什么是线性模型 线性模型的假设形式是属性权重.偏置与属性
-
详解堆排序算法原理及Java版的代码实现
概述 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义如下:具有n个元素的序列(k1,k2,...,kn), 当且仅当满足: 时称之为堆.由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)或最大项(大顶堆). 若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点(有子女的结点)的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的. (a)大顶堆序列:(96, 83, 27, 38, 11, 09) (b)小顶堆序列:(12, 36,
-
详解Bagging算法的原理及Python实现
目录 一.什么是集成学习 二.Bagging算法 三.Bagging用于分类 四.Bagging用于回归 一.什么是集成学习 集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组"个体学习器",再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking 也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策
-
详解MD5算法的原理以及C#和JS的实现
目录 一.简介 二.C# 代码实现 三.js 代码实现 一.简介 MD5 是哈希算法(散列算法)的一种应用.Hash 算法虽然被称为算法,但实际上它更像是一种思想.Hash 算法没有一个固定的公式,只要符合散列思想的算法都可以被称为是 Hash 算法. 算法目的就是,把任意长度的输入(又叫做预映射 pre-image),通过散列算法变换成固定长度的输出,该输出就是散列值. 注意,不同的输入可能会散列成相同的输出,所以不能从散列值来确定唯一的输入值. 散列函数简单的说就是:一种将任意长度的消息压缩
-
详解K-means算法在Python中的实现
K-means算法简介 K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低. K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法.k-means 算法接受输入量 k :然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高:而不同聚类中的对象相似度较小. 核心思想 通过迭代寻找
-
详解Unique SQL原理和应用
1.什么是Unique SQL 用户执行SQL语句时,每一个SQL语句文本都会进入解析器(Parser),生成"解析树"(parse tree).遍历解析树中各个结点,忽略其中的常数值,以一定的算法结合树中的各结点,计算出来一个整数值,用来唯一标识这一类SQL,这个整数值被称为Unique SQL ID,Unique SQL ID相同的SQL语句属于同一个"Unique SQL". 例如,用户先后输入如下两条SQL语句: select * from t1 where
-
详解编译器编译原理
详解编译器编译原理 什么是gcc 什么是gcc:gcc是GNU Compiler Collection的缩写.最初是作为C语言的编译器(GNU C Compiler),现在已经支持多种语言了,如C.C++.Java.Pascal.Ada.COBOL语言等. gcc支持多种硬件平台,甚至对Don Knuth 设计的 MMIX 这类不常见的计算机都提供了完善的支持 gcc主要特征 1)gcc是一个可移植的编译器,支持多种硬件平台 2)gcc不仅仅是个本地编译器,它还能跨平台交叉编译. 3)gcc
-
python实现连续变量最优分箱详解--CART算法
关于变量分箱主要分为两大类:有监督型和无监督型 对应的分箱方法: A. 无监督:(1) 等宽 (2) 等频 (3) 聚类 B. 有监督:(1) 卡方分箱法(ChiMerge) (2) ID3.C4.5.CART等单变量决策树算法 (3) 信用评分建模的IV最大化分箱 等 本篇使用python,基于CART算法对连续变量进行最优分箱 由于CART是决策树分类算法,所以相当于是单变量决策树分类. 简单介绍下理论: CART是二叉树,每次仅进行二元分类,对于连续性变量,方法是依次计算相邻两元素值的中位