Java中Prime算法的原理与实现详解
目录
- Prim算法介绍
- 1.点睛
- 2.算法介绍
- 3. 算法步骤
- 4.图解
- Prime 算法实现
- 1.构建后的图
- 2.代码
- 3.测试
Prim算法介绍
1.点睛
在生成树的过程中,把已经在生成树中的节点看作一个集合,把剩下的节点看作另外一个集合,从连接两个集合的边中选择一条权值最小的边即可。
2.算法介绍

首先任选一个节点,例如节点1,把它放在集合 U 中,U={1},那么剩下的节点为 V-U={2,3,4,5,6,7},集合 V 是图的所有节点集合。
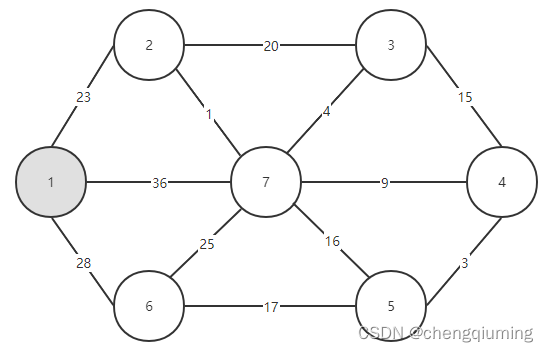
现在只需要看看连接两个集合(U 和 V-U)的边中,哪一条边的权值最小,把权值最小的边关联的节点加入集合 U 中。从上图可以看出,连接两个集合的 3 条边中,1-2 边的权值最小,选中它,把节点 2 加入集合 U 中,U={1,2},V - U={3,4,5,6},如下图所示。

再从连接两个集合(U 和 V-U)的边中选择一条权最小的边。从上图看出,在连接两个集合的4条边中,节点2到节点7的边权值最小,选中这条边,把节点7加入集合U={1,2,7}中,V-U={3,4,5,6}。
如此下去,直到 U=V 结束,选中的边和所有的节点组成的图就是最小生成树。这就是 Prim 算法。
直观地看图,很容易找出集合 U 到 集合 U-V 的边中哪条边的权值是最小的,但在程序中穷举这些边,再找最小值,则时间复杂度太高。可以通过设置数组巧妙解决这个问题,closet[j] 表示集合 V-U 中的节点 j 到集合 U 中的最邻近点,lowcost[j] 表示集合 V-U 中节点 j 到集合 U 中最邻近点的边值,即边(j,closest[j]) 的权值。
例如在上图中,节点 7 到集合 U 中的最邻近点是2,cloeest[7]=2。节点 7 到最邻近点2 的边值为1,即边(2,7)的权值,记为 lowcost[7]=1,如下图所示。

所以只需在集合 V - U 中找到 lowcost[] 只最小的节点即可。
3. 算法步骤
1.初始化
令集合 U={u0},u0 属于 V,并初始化数组 closest[]、lowcost[]和s[]。
2.在集合 V-U 中找 lowcost 值最小的节点t,即 lowcost[t]=min{lowcost[j]},j 属于 V-U,满足该公式的节点 t 就是集合 V-U 中连接 U 的最邻近点。
3.将节点 t 加入集合 U 中。
4.如果集合 V - U 为空,则算法结束,否则转向步骤 5。
5.对集合 V-U 中的所有节点 j 都更新其 lowcost[] 和 closest[]。if(C[t][j]<lowcost[j]){lowcost[j]=C[t][j];closest[j]=t;},转向步骤2。
按照上面步骤,最终可以得到一棵权值之和最小的生成树。
4.图解
图 G=(V,E)是一个无向连通带权图,如下图所示。

1 初始化。假设 u0=1,令集合 U={1},集合 V-U={2,3,4,5,6,7},s[1]=true,初始化数组 closest[]:除了节点1,其余节点均为1,表示集合 V-U 中的节点到集合 U 的最邻近点均为1.lowcost[]:节点1到集合 V-U 中节点的边值。closest[] 和 lowcost[] 如下图所示。
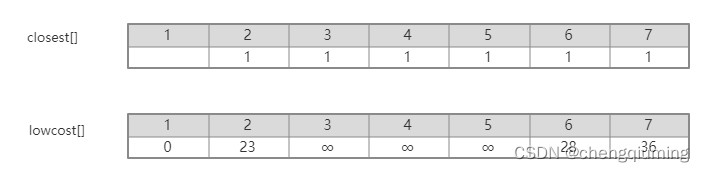
初始化后的图为:

2 找 lowcost 最小的节点,对应的 t=2,选中的边和节点如下图。

3 加入集合U中。将节点 t 加入集合 U 中,U={1,2},同时更新 V-U={3,4,5,6,7}
4 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 2 的邻接点是节点 3 和节点7。
C[2][3]=20<lowcost[3]=无穷大,更新最邻近距离 lowcost[3]=20,最邻近点 closest[3]=2;
C[2][7]=1<lowcost[7]=36,更新最邻近距离 lowcost[7]=1,最邻近点 closest[7]=2;
更新后的 closest[] 和 lowcost[] 如下图所示。

更新后的集合如下图所示:

5 找 lowcost 最小的节点,对应的 t=7,选中的边和节点如下图。

6 加入集合U中。将节点 t 加入集合 U 中,U={1,2,7},同时更新 V-U={3,4,5,6}
7 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 7 的邻接点是节点 3、4、5、6。
- C[7][3]=4<lowcost[3]=20,更新最邻近距离 lowcost[3]=4,最邻近点 closest[3]=7;
- C[7][4]=4<lowcost[4]=无穷大,更新最邻近距离 lowcost[3]=9,最邻近点 closest[4]=7;
- C[7][5]=4<lowcost[5]=无穷大,更新最邻近距离 lowcost[3]=16,最邻近点 closest[5]=7;
- C[7][6]=4<lowcost[6]=28,更新最邻近距离 lowcost[3]=25,最邻近点 closest[6]=7;
更新后的 closest[] 和 lowcost[] 如下图所示。

更新后的集合如下图所示:

8 找 lowcost 最小的节点,对应的 t=3,选中的边和节点如下图。

9 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,7},同时更新 V-U={4,5,6}
10 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 3 的邻接点是节点 4。
C[3][4]=15>lowcost[4]=9,不更新
closest[] 和 lowcost[] 数组不改变。
更新后的集合如下图所示:

11 找 lowcost 最小的节点,对应的 t=4,选中的边和节点如下图。

12 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,4,7},同时更新 V-U={5,6}
13 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 4 的邻接点是节点 5。
C[4][5]=3<lowcost[5]=16,更新最邻近距离 lowcost[5]=3,最邻近点 closest[5]=4;
更新后的 closest[] 和 lowcost[] 如下图所示。

更新后的集合如下图所示:

14 找 lowcost 最小的节点,对应的 t=5,选中的边和节点如下图。

15 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,4,5,7},同时更新 V-U={6}
16 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 5 的邻接点是节点 6。
C[5][6]=17<lowcost[6]=25,更新最邻近距离 lowcost[6]=17,最邻近点 closest[6]=5;
更新后的集合如下图所示:

17 找 lowcost 最小的节点,对应的 t=6,选中的边和节点如下图。
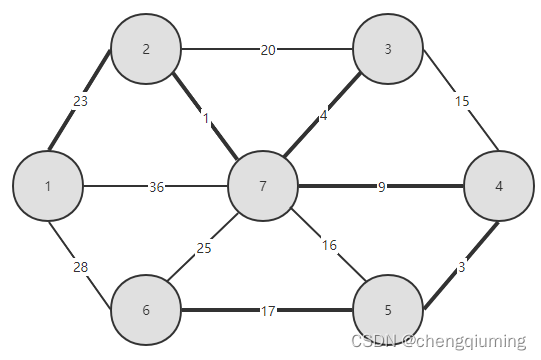
18 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,4,5,6,7},同时更新 V-U={}
19 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 6 在集合 V-U 中无邻接点。不用更新 closest[] 和 lowcost[] 。
20 得到的最小生成树如下。最小生成树的权值之和为 57.

Prime 算法实现
1.构建后的图

2.代码
package graph.prim;
import java.util.Scanner;
public class Prim {
static final int INF = 0x3f3f3f3f;
static final int N = 100;
// 如果s[i]=true,说明顶点i已加入U
static boolean s[] = new boolean[N];
static int c[][] = new int[N][N];
static int closest[] = new int[N];
static int lowcost[] = new int[N];
static void Prim(int n) {
// 初始时,集合中 U 只有一个元素,即顶点 1
s[1] = true;
for (int i = 1; i <= n; i++) {
if (i != 1) {
lowcost[i] = c[1][i];
closest[i] = 1;
s[i] = false;
} else
lowcost[i] = 0;
}
for (int i = 1; i < n; i++) {
int temp = INF;
int t = 1;
// 在集合中 V-u 中寻找距离集合U最近的顶点t
for (int j = 1; j <= n; j++) {
if (!s[j] && lowcost[j] < temp) {
t = j;
temp = lowcost[j];
}
}
if (t == 1)
break; // 找不到 t,跳出循环
s[t] = true; // 否则,t 加入集合U
for (int j = 1; j <= n; j++) { // 更新 lowcost 和 closest
if (!s[j] && c[t][j] < lowcost[j]) {
lowcost[j] = c[t][j];
closest[j] = t;
}
}
}
}
public static void main(String[] args) {
int n, m, u, v, w;
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
int sumcost = 0;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
c[i][j] = INF;
for (int i = 1; i <= m; i++) {
u = scanner.nextInt();
v = scanner.nextInt();
w = scanner.nextInt();
c[u][v] = c[v][u] = w;
}
Prim(n);
System.out.println("数组lowcost:");
for (int i = 1; i <= n; i++)
System.out.print(lowcost[i] + " ");
System.out.println();
for (int i = 1; i <= n; i++)
sumcost += lowcost[i];
System.out.println("最小的花费:" + sumcost);
}
}
3.测试

以上就是Java中Prime算法的原理与实现详解的详细内容,更多关于Java Prime算法的资料请关注我们其它相关文章!
相关推荐
-

Java实现Floyd算法的示例代码
目录 一 问题描述 二 代码 三 实现 一 问题描述 求节点0到节点2的最短路径. 二 代码 package graph.floyd; import java.util.Scanner; public class Floyd { static final int MaxVnum = 100; // 顶点数最大值 static final int INF = 0x3f3f3f3f; //无穷大 static final int dist[][] = new int[MaxVnum][MaxVnum
-
详解Java Bellman-Ford算法原理及实现
目录 一 点睛 二 算法步骤 三 算法实现 四 测试 一 点睛 如果遇到负权边,则在没有负环(回路的权值之和为负)存在时,可以采用 Bellman-Ford 算法求解最短路径.该算法的优点是变的权值可以是负数.实现简单,缺点是时间复杂度过高.但是该算法可以进行若干种优化,以提高效率. Bellman-Ford 算法与 Dijkstra 算法类似,都是以松弛操作作为基础.Dijkstra 算法以贪心法选取未被处理的具有最小权值的节点,然后对其进行松弛操作:而 Bellman-Ford 算法对所有边
-
Java实现Kruskal算法的示例代码
目录 介绍 一.构建后的图 二.代码 三.测试 介绍 构造最小生成树还有一种算法,即 Kruskal 算法:设图 G=(V,E)是无向连通带权图,V={1,2,...n};设最小生成树 T=(V,TE),该树的初始状态只有 n 个节点而无边的非连通图T=(V,{}),Kruskal 算法将这n 个节点看成 n 个孤立的连通分支.它首先将所有边都按权值从小到大排序,然后值要在 T 中选的边数不到 n-1,就做这样贪心选择:在边集 E 中选择权值最小的边(i,j),如果将边(i,j)加入集合 TE
-
Java贪心算法超详细讲解
目录 什么是贪心算法 通过场景理解算法 问题分析 总结 什么是贪心算法 在分析和求解某个问题时,在每一步的计算选择上都是最优的或者最好的,通过这种方式期望最终的计算的结果也是最优的.也就是说,算法通过先追求局部的最优解,从而寻求整体的最优解. 贪心算法的基本步骤: 1.首先定义问题,确定问题模型是不是适合使用贪心算法,即求解最值问题: 2.将求极值的问题进行拆解,然后对拆解后的每一个子问题进行求解,试图获得当前子问题的局部最优解: 3.所有子问题的局部最优解求解完成后,把这些局部最优解进行汇总合
-
Java实现Dijkstra算法的示例代码
目录 一 问题描述 二 实现 三 测试 一 问题描述 小明为位置1,求他到其他各顶点的距离. 二 实现 package graph.dijkstra; import java.util.Scanner; import java.util.Stack; public class Dijkstra { static final int MaxVnum = 100; // 顶点数最大值 static final int INF = 0x3f3f3f3f; //无穷大 static final int
-
Java贪心算法之Prime算法原理与实现方法详解
本文实例讲述了Java贪心算法之Prime算法原理与实现方法.分享给大家供大家参考,具体如下: Prime算法:是一种穷举查找算法来从一个连通图中构造一棵最小生成树.利用始终找到与当前树中节点权重最小的边,找到节点,加到最小生成树的节点集合中,直至所有节点都包括其中,这样就构成了一棵最小生成树.prime在算法中属于贪心算法的一种,贪心算法还有:Kruskal.Dijkstra以及哈夫曼树及编码算法. 下面具体讲一下prime算法: 1.首先需要构造一颗最小生成树,以及两个节点之间的权重数组,在
-
Java中Prime算法的原理与实现详解
目录 Prim算法介绍 1.点睛 2.算法介绍 3. 算法步骤 4.图解 Prime 算法实现 1.构建后的图 2.代码 3.测试 Prim算法介绍 1.点睛 在生成树的过程中,把已经在生成树中的节点看作一个集合,把剩下的节点看作另外一个集合,从连接两个集合的边中选择一条权值最小的边即可. 2.算法介绍 首先任选一个节点,例如节点1,把它放在集合 U 中,U={1},那么剩下的节点为 V-U={2,3,4,5,6,7},集合 V 是图的所有节点集合. 现在只需要看看连接两个集合(U 和 V-U)
-
图解Java中插入排序算法的原理与实现
目录 一.基本思想 二.算法分析 1.算法描述 2.过程分析 三.算法实现 一.基本思想 插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法.它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入. 二.算法分析 1.算法描述 一般来说,插入排序都采用in-place在数组上实现.具体算法描述如下: 从第一个元素开始,该元素可以认为已经被排序: 取出下一个元素,在已经排序的元素序列中从后向前扫描: 如果该元素(已排序)大于新元素,将
-
图解Java中归并排序算法的原理与实现
目录 一.基本思想 二.算法分析 1.算法描述 2.过程分析 3.动图演示 三.算法实现 一.基本思想 归并排序是建立在归并操作上的一种有效的排序算法.该算法是采用分治法(Divide and Conquer)的一个非常典型的应用.将已有序的子序列合并,得到完全有序的序列:即先使每个子序列有序,再使子序列段间有序.若将两个有序表合并成一个有序表,称为2-路归并. 二.算法分析 1.算法描述 把长度为n的输入序列分成两个长度为n/2的子序列:对这两个子序列分别采用归并排序:将两个排序好的子序列合并
-
基数排序算法的原理与实现详解(Java/Go/Python/JS/C)
目录 说明 实现过程 示意图 性能分析 代码 Java Python Go JS TS C C++ 链接 说明 基数排序(RadixSort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较.由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数.基数排序的发明可以追溯到1887年赫尔曼·何乐礼在列表机(Tabulation Machine)上的 基数排序的方式可以采用LSD(Least significant di
-
Matlab中图像数字水印算法的原理与实现详解
目录 一.背景意义 二.基本原理 三.算法介绍 3.1 数字水印嵌入 3.2 数字水印提取 四.程序实现 一.背景意义 数字水印技术作为信息隐藏技术的一个重要分支,是将信息(水印)隐藏于数字图像.视频.音频及文本文档等数字媒体中,从而实现隐秘传输.存储.标注.身份识别.版权保护和防篡改等目的. 随着 1996 年第一届信息隐藏国际学术研讨会的召开,数字水印技术的研究得到了迅速的发展,不少政府机构和研究部门加大了对其的研究力度,其中包括美国财政部.美国版权工作组.美国洛斯阿莫斯国家实验室.美国海陆
-
java中生成任意之间数的随机数详解
这篇文章主要介绍了java中生成任意之间数的随机数详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 public static int cssjs(int a,int b) { Random rand=new Random(); int zhi; zhi=rand.nextInt(b)%(b-a+1)+a; return zhi; } 我们观察其Random对象的nextInt(int)方法,发现这个发现这个方法将生成 0 ~ 参数之间随机取
-
Java web拦截器inteceptor原理及应用详解
这篇文章主要介绍了java web拦截器inteceptor原理及应用详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.简介 java里的拦截器提供的是非系统级别的拦截,也就是说,就覆盖面来说,拦截器不如过滤器强大,但是更有针对性. Java中的拦截器是基于Java反射机制实现的,更准确的划分,应该是基于JDK实现的动态代理.它依赖于具体的接口,在运行期间动态生成字节码. 拦截器是动态拦截Action调用的对象,它提供了一种机制可以使开发
-
Java中Validated、Valid 、Validator区别详解
目录 1. 结论先出 JSR 380 Valid VS Validated 不同点? Validator 2. @Valid和@Validated 注解 3. 例子 4.使用@Valid嵌套校验 5. 组合使用@Valid和@Validated 进行集合校验 6. 自定义校验 自定义约束注解 工作原理 结论 参考链接: 1. 结论先出 Valid VS Validated 相同点 都可以对方法和参数进行校验 @Valid和@Validated 两种注释都会导致应用标准Bean验证.
-
Java基础之Stream流原理与用法详解
目录 一.接口设计 二.创建操作 三.中间操作 四.最终操作 五.Collect收集 Stream简化元素计算 一.接口设计 从Java1.8开始提出了Stream流的概念,侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式:依旧先看核心接口的设计: BaseStream:基础接口,声明了流管理的核心方法: Stream:核心接口,声明了流操作的核心方法,其他接口为指定类型的适配: 基础案例:通过指定元素的值,返回一个序列流,元素的内容是字符串,并转换为Long类型,最终计算求和结果并
-
Java 中 Class Path 和 Package的使用详解
目录 一. 类路径 (class path) 二. 包 (package) 三. jar 文件 一. 类路径 (class path) 当你满怀着希望安装好了 java, 然后兴冲冲地写了个 hello world,然后编译,运行, 就等着那两个美好的单词出现在眼前, 可是不幸的是, 只看到了 Can't find class HelloWorld 或者 Exception in thread "main" java.lang.NoSuchMethodError : maain.为什么