Python编程快速上手——疯狂填词程序实现方法分析
本文实例讲述了Python疯狂填词程序实现方法。分享给大家供大家参考,具体如下:
题目如下:
- 创建一个疯狂填词程序,它将读入文件,并让用户在该文本文件中出现ADJECTIVE,NOUN,ADVERB,VERB等单词的地方,加上它们自己的文本。
- 例如源文本如下: The ADJECTIVE panda walked to the NOUN and then VERB. A nearby NOUN was unaffected by these events.
- 程序将找到这些出现的单词,提示用户取代他们
Enter an adjective:
silly
Enter a noun:
chandelier
Enter a verb:
screamed
Enter a noun:
pickup truck
思路如下:
- 程序需要做以下事情:
读入文本文件
在相应单词的地方让用户输入替换
保存修改后的文本文件,并将结果打印到屏幕 - 代码需要做以下事情:
导入模块re
编写函数,创建正则表达式对象
函数内调用Regex.findall()方法,返回匹配到的所有结果列表
打开文本文件,导入到变量
for循环控制输入
字符串replace方法进行替换
print()显示更改后的文本到屏幕
open.write()保存到新文件
代码如下:
import re
def madLibs(longStr):
madLibsRex = re.compile(r'ADJECTIVE|NOUN|ADVERB|VERB') #正则表达式对象
print(madLibsRex.findall(longStr)) #验证是否模式匹配正确
return madLibsRex.findall(longStr)
openFile = open('123.txt','r')
longStr = openFile.read() #将文本内容读入变量longStr
print("源文本如下:",longStr)
for i in madLibs(longStr): #循环遍历函数返回的匹配对象列表
print("Enter an {0}:".format(i))
longStr = longStr.replace(i,input()) #调用字符串的replace()方法输入替换,再赋值给longStr
print(longStr)
resultFile = open('new123.txt','w') #在当前工作目录创建一个新的文件
resultFile.write(longStr) #将字符串变量写入resultFile对象
openFile.close()
resultFile.close()
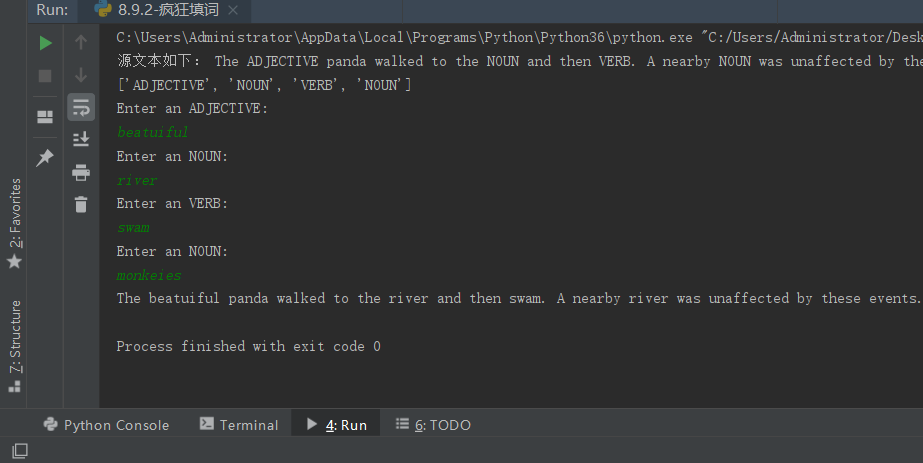
结果如下:
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python列表(list)操作技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-

Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
python实现中文分词FMM算法实例
本文实例讲述了python实现中文分词FMM算法.分享给大家供大家参考.具体分析如下: FMM算法的最简单思想是使用贪心算法向前找n个,如果这n个组成的词在词典中出现,就ok,如果没有出现,那么找n-1个...然后继续下去.假如n个词在词典中出现,那么从n+1位置继续找下去,直到句子结束. import re def PreProcess(sentence,edcode="utf-8"): sentence = sentence.decode(edcode) sentence=re.s
-
python TF-IDF算法实现文本关键词提取
TF(Term Frequency)词频,在文章中出现次数最多的词,然而文章中出现次数较多的词并不一定就是关键词,比如常见的对文章本身并没有多大意义的停用词.所以我们需要一个重要性调整系数来衡量一个词是不是常见词.该权重为IDF(Inverse Document Frequency)逆文档频率,它的大小与一个词的常见程度成反比.在我们得到词频(TF)和逆文档频率(IDF)以后,将两个值相乘,即可得到一个词的TF-IDF值,某个词对文章的重要性越高,其TF-IDF值就越大,所以排在最前面的几个词就
-
Python自然语言处理之词干,词形与最大匹配算法代码详解
本文主要对词干提取及词形还原以及最大匹配算法进行了介绍和代码示例,Python实现,下面我们一起看看具体内容. 自然语言处理中一个很重要的操作就是所谓的stemming和lemmatization,二者非常类似.它们是词形规范化的两类重要方式,都能够达到有效归并词形的目的,二者既有联系也有区别. 1.词干提取(stemming) 定义:Stemmingistheprocessforreducinginflected(orsometimesderived)wordstotheirstem,base
-
python通过BF算法实现关键词匹配的方法
本文实例讲述了python通过BF算法实现关键词匹配的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: #!/usr/bin/python # -*- coding: UTF-8 # filename BF import time """ t="this is a big apple,this is a big apple,this is a big apple,this is a big apple." p="apple&q
-
python实现机械分词之逆向最大匹配算法代码示例
逆向最大匹配方法 有正即有负,正向最大匹配算法大家可以参阅http://www.jb51.net/article/127404.htm 逆向最大匹配分词是中文分词基本算法之一,因为是机械切分,所以它也有分词速度快的优点,且逆向最大匹配分词比起正向最大匹配分词更符合人们的语言习惯.逆向最大匹配分词需要在已有词典的基础上,从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(分词所确定的阈值i)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配.而且选择的阈值越大,分词越慢,但准确性
-
python中文分词教程之前向最大正向匹配算法详解
前言 大家都知道,英文的分词由于单词间是以空格进行分隔的,所以分词要相对的容易些,而中文就不同了,中文中一个句子的分隔就是以字为单位的了,而所谓的正向最大匹配和逆向最大匹配便是一种分词匹配的方法,这里以词典匹配说明. 最大匹配算法是自然语言处理中的中文匹配算法中最基础的算法,分为正向和逆向,原理都是一样的. 正向最大匹配算法,故名思意,从左向右扫描寻找词的最大匹配. 首先我们可以规定一个词的最大长度,每次扫描的时候寻找当前开始的这个长度的词来和字典中的词匹配,如果没有找到,就缩短长度继续寻找,直
-
Python基于动态规划算法计算单词距离
本文实例讲述了Python基于动态规划算法计算单词距离.分享给大家供大家参考.具体如下: #!/usr/bin/env python #coding=utf-8 def word_distance(m,n): """compute the least steps number to convert m to n by insert , delete , replace . 动态规划算法,计算单词距离 >>> print word_distance("
-
python制作填词游戏步骤详解
如何用PYTHON制作填词游戏 新建一个PYTHON文档.用JUPYTER NOTEBOOK打开即可. print("Heart is " + color) print(noun + " are red") print("I like " + food) 我们首先确定一下填词的大概方向. color = input("Please enter a color: ") noun = input("Please ente
-
python实现协同过滤推荐算法完整代码示例
测试数据 http://grouplens.org/datasets/movielens/ 协同过滤推荐算法主要分为: 1.基于用户.根据相邻用户,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表进行推荐 2.基于物品.如喜欢物品A的用户都喜欢物品C,那么可以知道物品A与物品C的相似度很高,而用户C喜欢物品A,那么可以推断出用户C也可能喜欢物品C. 不同的数据.不同的程序猿写出的协同过滤推荐算法不同,但其核心是一致的: 1.收集用户的偏好 1)不同行为分组 2)不同分组进行加权计算用