python数据预处理 :数据共线性处理详解
何为共线性:
共线性问题指的是输入的自变量之间存在较高的线性相关度。共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间
共线性产生原因:
变量出现共线性的原因:
数据样本不够,导致共线性存在偶然性,这其实反映了缺少数据对于数据建模的影响,共线性仅仅是影响的一部分
多个变量都给予时间有共同或相反的演变趋势,例如春节期间的网络销售量和销售额都相对与正常时间有下降趋势。
多个变量存在一定的推移关系,但总体上变量间的趋势一致,只是发生的时间点不一致,例如广告费用和销售额之间,通常是品牌广告先进行大范围的曝光和信息推送,经过一定时间传播之后,才会在销售额上做出反映。
多变量之间存在线性的关系。例如y代表访客数,用x代表展示广告费用,那么二者的关系很可能是y=2*x + b
如何检验共线性:
检验共线性:
容忍度(Tolerance):容忍度是每个自变量作为因变量对其他自变量进行回归建模时得到的残差比例,大小用1减得到的决定系数来表示。容忍度值越小说明这个自变量与其他自变量间越可能存在共线性问题。
方差膨胀因子 VIF是容忍度的倒数,值越大则共线性问题越明显,通常以10作为判断边界。当VIF<10,不存在多重共线性;当10<=VIF<100,存在较强的多重共线性;当VIF>=100, 存在严重多重共线性。
特征值(Eigenvalue):该方法实际上就是对自变量做主成分分析,如果多个维度的特征值等于0,则可能有比较严重的共线性。
相关系数:如果相关系数R>0.8时就可能存在较强相关性
如何处理共线性:
处理共线性:
增大样本量:增大样本量可以消除犹豫数据量不足而出现的偶然的共线性现象,在可行的前提下这种方法是需要优先考虑的
岭回归法(Ridge Regression):实际上是一种改良最小二乘估计法。通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价来获得更实际和可靠性更强的回归系数。因此岭回归在存在较强共线性的回归应用中较为常用。
逐步回归法(Stepwise Regression):每次引入一个自变量进行统计检验,然后逐步引入其他变量,同时对所有变量的回归系数进行检验,如果原来引入的变量由于后面变量的引入而变得不再显著,那么久将其剔除,逐步得到最有回归方程。
主成分回归(Principal Components Regression):通过主成分分析,将原始参与建模的变量转换为少数几个主成分,么个主成分是原变量的线性组合,然后基于主成分做回归分析,这样也可以在不丢失重要数据特征的前提下避开共线性问题。
人工去除:结合人工经验,对自变量进行删减,但是对操作者的业务能力、经验有很高的要求。
部分方法python代码实现
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
# 导入数据
df = pd.read_csv('https://raw.githubusercontent.com/ffzs/dataset/master/boston/train.csv')
# 切分自变量
X = df.iloc[:, 1:-1].values
# 切分预测变量
y = df.iloc[:, [-1]].values
# 使用岭回归处理
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
n_alphas = 20
alphas = np.logspace(-1,4,num=n_alphas)
coefs = []
for a in alphas:
ridge = Ridge(alpha=a, fit_intercept=False)
ridge.fit(X, y)
coefs.append(ridge.coef_[0])
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
handles, labels = ax.get_legend_handles_labels()
plt.legend(labels=df.columns[1:-1])
plt.xlabel('alpha')
plt.ylabel('weights')
plt.axis('tight')
plt.show()
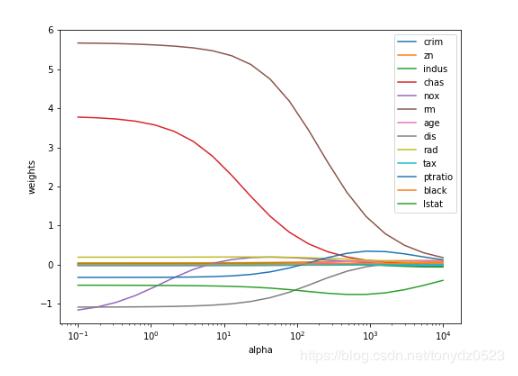
只有nox有些许波动。
# 主成分回归进行回归分析 pca_model = PCA() data_pca = pca_model.fit_transform(X) # 得到所有主成分方差 ratio_cumsum = np.cumsum(pca_model.explained_variance_ratio_) # 获取方差占比超过0.8的索引值 rule_index = np.where(ratio_cumsum > 0.9) # 获取最小的索引值 min_index = rule_index[0][0] # 根据最小索引值提取主成分 data_pca_result = data_pca[:, :min_index+1] # 建立回归模型 model_liner = LinearRegression() # 训练模型 model_liner.fit(data_pca_result, y) print(model_liner.coef_) #[[-0.02430516 -0.01404814]]
以上这篇python数据预处理 :数据共线性处理详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch数据预处理错误的解决
出错: Traceback (most recent call last): File "train.py", line 305, in <module> train_model(model_conv, criterion, optimizer_conv, exp_lr_scheduler) File "train.py", line 145, in train_model for inputs, age_labels, gender_labels in
-

python数据预处理方式 :数据降维
数据为何要降维 数据降维可以降低模型的计算量并减少模型运行时间.降低噪音变量信息对于模型结果的影响.便于通过可视化方式展示归约后的维度信息并减少数据存储空间.因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理. 数据降维有两种方式:特征选择,维度转换 特征选择 特征选择指根据一定的规则和经验,直接在原有的维度中挑选一部分参与到计算和建模过程,用选择的特征代替所有特征,不改变原有特征,也不产生新的特征值. 特征选择的降维方式好处是可以保留原有维度特征的基础上进行降维,既能满足后续数据
-
python数据预处理 :数据抽样解析
何为数据抽样: 抽样是数据处理的一种基本方法,常常伴随着计算资源不足.获取全部数据困难.时效性要求等情况使用. 抽样方法: 一般有四种方法: 随机抽样 直接从整体数据中等概率抽取n个样本.这种方法优势是,简单.好操作.适用于分布均匀的场景:缺点是总体大时无法一一编号 系统抽样 又称机械.等距抽样,将总体中个体按顺序进行编号,然后计算出间隔,再按照抽样间隔抽取个体.优势,易于理解.简便易行.缺点是,如有明显分布规律时容易产生偏差. 群体抽样 总体分群,在随机抽取几个小群代表总体.优点是简单易行.便
-
python优化数据预处理方法Pandas pipe详解
我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用.Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法. import numpy as np import pandas as pd df = pd.DataFrame({ "id": [100, 100, 101, 102, 103, 104, 105, 106], "A": [1, 2, 3, 4, 5, 2, np.nan, 5], "B":
-
python数据预处理 :数据共线性处理详解
何为共线性: 共线性问题指的是输入的自变量之间存在较高的线性相关度.共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间 共线性产生原因: 变量出现共线性的原因: 数据样本不够,导致共线性存在偶然性,这其实反映了缺少数据对于数据建模的影响,共线性仅仅是影响的一部分 多个变量都给予时间有共同或相反的演变趋势,例如春节期间的网络销售量和销售额都相对与正常时间有下降趋势. 多个变量存在一定的推移关系,但总体上变量间的趋势一致,只是发生的时间点不一致,例如广告费用和销售
-
python类:class创建、数据方法属性及访问控制详解
在Python中,可以通过class关键字定义自己的类,然后通过自定义的类对象类创建实例对象. python中创建类 创建一个Student的类,并且实现了这个类的初始化函数"__init__": class Student(object): count = 0 books = [] def __init__(self, name): self.name = name 接下来就通过上面的Student类来看看Python中类的相关内容. 类构造和
-
python 数据的清理行为实例详解
python 数据的清理行为实例详解 数据清洗主要是指填充缺失数据,消除噪声数据等操作,主要还是通过分析"脏数据"产生的原因和存在形式,利用现有的数据挖掘手段去清洗"脏数据",然后转化为满足数据质量要求或者是应用要求的数据. 1.try 语句还有另外一个可选的子句,它定义了无论在任何情况下都会执行的清理行为. 例如: >>>try: raiseKeyboardInterrupt finally: print('Goodbye, world!') G
-
基于Python的Post请求数据爬取的方法详解
为什么做这个 和同学聊天,他想爬取一个网站的post请求 观察 该网站的post请求参数有两种类型:(1)参数体放在了query中,即url拼接参数(2)body中要加入一个空的json对象,关于为什么要加入空的json对象,猜测原因为反爬虫.既有query参数又有空对象体的body参数是一件脑洞很大的事情. 一开始先在apizza网站 上了做了相关实验才发现上面这个规律的,并发现该网站的请求参数要为raw形式,要是直接写代码找规律不是一件容易的事情. 源码 import requests im
-
基于Python对数据shape的常见操作详解
这一阵在用python做DRL建模的时候,尤其是在配合使用tensorflow的时候,加上tensorflow是先搭框架再跑数据,所以调试起来很不方便,经常遇到输入数据或者中间数据shape的类型不统一,导致一些op老是报错.而且由于水平菜,所以一些常用的数据shape转换操作也经常百度了还是忘,所以想再整理一下. 一.数据的基本属性 求一组数据的长度 a = [1,2,3,4,5,6,7,8,9,10,11,12] print(len(a)) print(np.size(a)) 求一组数据的s
-
python产生模拟数据faker库的使用详解
简介 使用faker可以获取很多模拟数据,如:姓名.电话.地址.银行.汽车.条形码.公司.信用卡.email.user_agen等等 学会使用这个库,再也不用为制造假数据发愁了...... 同时,使用起来非常简单,只需要安装,导入库,并创建实例,即可使用,如下: 主要的方法分类 如上面例子,每次调用 fake 实例的 name()方法时,都会产生不同随机姓名.fake 实例还有很多方法可用,这些方法分为以下几类: address 地址 person 人物类:性别.姓名等 barcode 条码类
-
Python数据可视化之Pyecharts使用详解
目录 1. 安装Pyecharts 2. 图表基础 2.1 主题风格 2.2 图表标题 2.3 图例 2.4 提示框 2.5 视觉映射 2.6 工具箱 2.7 区域缩放 3. 柱状图 Bar模块 4. 折线图/面积图 Line模块 4.1 折线图 4.2 面积图 5.饼形图 5.1 饼形图 5.2 南丁格尔玫瑰图 6. 箱线图 Boxplot模块 7. 涟漪特效散点图 EffectScatter模块 8. 词云图 WordCloud模块 9. 热力图 HeatMap模块 10. 水球图 Liqu
-
Python实战实现爬取天气数据并完成可视化分析详解
1.实现需求: 从网上(随便一个网址,我爬的网址会在评论区告诉大家,dddd)获取某一年的历史天气信息,包括每天最高气温.最低气温.天气状况.风向等,完成以下功能: (1)将获取的数据信息存储到csv格式的文件中,文件命名为”城市名称.csv”,其中每行数据格式为“日期,最高温,最低温,天气,风向”: (2)在数据中增加“平均温度”一列,其中:平均温度=(最高温+最低温)/2,在同一张图中绘制两个城市一年平均气温走势折线图: (3)统计两个城市各类天气的天数,并绘制条形图进行对比,假设适合旅游的
-
基于DataFrame筛选数据与loc的用法详解
DataFrame筛选数据与loc用法 python中pandas下的DataFrame是一个很不错的数据结构,附带了许多操作.运算.统计等功能. 如何从一个DataFrame中筛选中出一个元素呢. 以tushare返回的交易日信息为例. df = ts.trade_cal() 数据如下: calendarDate isOpen 0 1990/12/19 1 1 1990/12/20 1 2 1990/12/21 1 3 1990/12/22 0 4 1990/12/23 0 5 1990/12