Zabbix对Kafka topic积压数据监控的解决方案
目录
- Kafka
- 需求
- 解决方案
- 1.监控分析
- 2.监控思路
- (1) 消费者组管理
- (2)分区自动发现
- (3)获取监控项“test-group/test/分区X”的Lag
- (4)最终脚本
- 3.Zabbix 自动发现配置
- 4.告警信息
Kafka
Apache Kafka是一个分布式发布-订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。
Kafka适合离线和在线消息消费。
Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。Kafka构建在ZooKeeper同步服务之上。它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
需求
虽然我们在生产环境中可以使用Kafka对业务进行解耦,但这并不意味着业务系统就高枕无忧了。消费者的消费速度是否能够匹配生产速度、过多的消息积压这些都可能影响业务系统的正常运行。
关于业务系统运行状态,虽然我们可以通过业务监控来确定,但是业务监控一般是要对数据进行聚合分析并达到一定的阈值才能触发告警。因此业务监控告警通知时,业务实际已经有问题一段时间了。为应对这种情况,我们一般需要和系统监控进行互补。系统监控会周期性的对硬件、网络、服务器、应用等不同维度进行监控告警,一旦某个组件的状态有问题,那么系统监控会先预警,然后业务系统才可能进一步预警。经过不同监控系统的告警升级,才更能准确的反映业务系统的运行状态。
话说回来,对于上线后的Kafka集群,我们除了要对服务的可用性进行监控外,还要对Topic的消费情况进一步监控。
解决方案
1.监控分析
Lag作为监控指标,它直接反映了一个消费者的运行情况。一个正常工作的消费者,它的Lag值应该很小,甚至是接近于0的,这表示该消费者能够及时地消费生产者生产出来的消息,滞后程度很小。
因此我们将Topic作为我们的监控项,当相关的Topic Lag达到某一阈值时进行多渠道告警。
另经过Kafka运行机制的我们知道:
- 每个Topic内部需要按照Partition进行再次分区
- 同一个topic的partition只能由同一个消费者组(group)内的一个consumer来消费,分区数决定了同组消费者个数的上限

通过以上“Topic-Partition-消费者组(group)”之间的关系,为了便于我们通过告警信息更快的定位故障点:
- 监控项命名规则:消费者组(Group)/Topic/Partition,三者组成唯一的监控项;
- 监控项Lag值:获取业务系统中某个消费者组的特定Topic所有分区的Lag值进行告警;
2.监控思路
(1) 消费者组管理
通过Kafka自带的kafka-consumer-groups.sh脚本,我们可以轻松获取查看指定消费组 消费的所有Topic、及所在分区、最新消费offset、Log最新数据offset、Lag还未消费数量、消费者ID等等信息
# 查看消费者组的topic 消费状态 bash kafka-consumer-groups.sh --bootstrap-server 192.168.3.55:9090 --describe --group test2_consumer_group TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID test 0 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1 test 1 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1 test 2 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1 test 3 1000000 1000000 0 consumer-1-8688633a-2f88-4c41-89ca-fd0cd6d19ec7 /127.0.0.1 consumer-1
(2)分区自动发现
对于Kafka topic的监控我们使用Zabbix监控平台,考虑到后续业务系统的持续性接入,我们通过Zabbix自动发现实现对特定消费者组(Group)和Topic下所有分区自动发现:
# 自动发现
vim consumer-groups.conf
#按消费者组(Group)|Topic格式,写入自动发现配置文件
test-group|test
# 执行脚本自动发现指定消费者和topic的分区
bash consumer-groups.sh discovery
{
"data": [
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"0" },
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"1" },
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"3" },
{ "{#GROUP}":"test-group", "{#TOPICP}":"test", "{#PARTITION}":"2" }
]
}
自动发现中的GROUP、TOPIC、PARTITION 这三个信息可以用于进一步过滤不同的分区的Lag值和监控系统中的监控项名称:
- test-group/test/分区0
- test-group/test/分区1
- test-group/test/分区2
- test-group/test/分区3
- 等其他 test-group/test相关的所有分区
(3)获取监控项“test-group/test/分区X”的Lag
# 获取分区0 lag bash consumer-groups.sh lag 0 # 获取分区1 lag bash consumer-groups.sh lag 1 # 获取分区2 lag bash consumer-groups.sh lag 2 # 获取分区3 lag bash consumer-groups.sh lag 3
(4)最终脚本
vim consumer-groups.sh
#!/bin/bash
#comment: 根据消费者组监控topic lag,进行监控告警
#配置文件说明
#消费者组|Topic
#test-group|test
#获取topic 信息
cal_topic() {
if [ $# -ne 2 ]; then
echo "parameter num error, 读取topic信息失败"
exit 1
else
/usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.3.55:9092 --describe --group $1 |grep -w $2
fi
}
#topic+分区自动发现
topic_discovery() {
printf "{\n"
printf "\t\"data\": [\n"
for line in `cat /data/scripts/consumer-groups.conf`
do
group=`echo ${line} | awk -F'|' '{print $1}'`
topic=`echo ${line} | awk -F'|' '{print $2}'`
cal_topic $group $topic > /tmp/consumer-group-tmp
count=`cat /tmp/consumer-group-tmp|wc -l`
n=0
while read line
do
n=`expr $n + 1`
#判断最后一行
if [ $n -eq $count ]; then
topicp=`echo $line | awk '{print $1}'`
partition=`echo $line | awk '{print $2}'`
printf "\t\t{ \"{#GROUP}\":\"${group}\", \"{#TOPICP}\":\"${topicp}\", \"{#PARTITION}\":\"${partition}\" }\n"
else
topicp=`echo $line | awk '{print $1}'`
partition=`echo $line | awk '{print $2}'`
printf "\t\t{ \"{#GROUP}\":\"${group}\", \"{#TOPICP}\":\"${topicp}\", \"{#PARTITION}\":\"${partition}\" },\n"
fi
done < /tmp/consumer-group-tmp
done
printf "\t]\n"
printf "}\n"
}
if [ $1 == "discovery" ]; then
topic_discovery
elif [ $1 == "lag" ];then
cat /tmp/consumer-group-tmp |awk -v p=$2 '{if($2==p){print $5}}'
else
echo "Usage: /data/scripts/consumer-group.sh discovery | lag"
fi
3.Zabbix 自动发现配置
1.自动发现配置

2.监控项原型 通过消费者组、Topic、Partition 组成监控项名称,告警信息中的名称能够帮助我们快定位故障点。

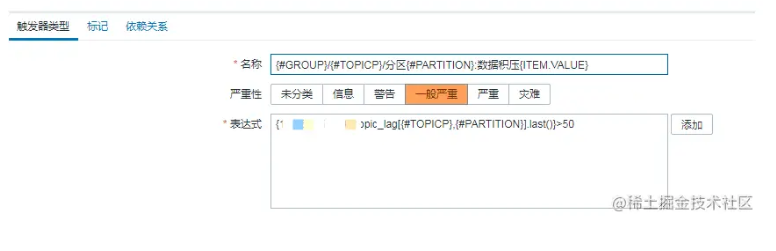
3.触发器 我们lag的初始阈值设置为50,可根据时间情况进行调整。
4.告警信息
告警主机:Kafka_192.168.3.55 主机IP:192.168.3.55 主机组:Kafka 告警时间:2022.03.21 00:23:10 告警等级:Average 告警信息:test-group/test/分区1:数据积压62 告警项目:topic_lag[test,1] 问题详情: test-group/test/1: 62
到此这篇关于Zabbix对Kafka topic积压数据监控的文章就介绍到这了,更多相关Zabbix Kafka 监控内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

zabbix配置nginx监控的实现
目录 案例:zabbix 配置 nginx 监控 1. 修改配置文件 2. 编写 nginx 监控脚本 3. 修改 zabbix 配置文件 4. 服务端验证 5. 添加模块 6. 创建应用集 7. 创建监控项 8. 定义触发器 9. 关联主机 10. nginx 模板文件 案例:zabbix 配置 nginx 监控 1. 修改配置文件 stub_status 模块可参考: https://www.jb51.net/article/248979.htm vim /usr/local/nginx/c
-
zabbix监控mysql的实例方法
1.监控规划 在创建监控项之前要尽量考虑清楚要监控什么,怎么监控,监控数据如何存储,监控数据如何展现,如何处理报警等.要进行监控的系统规划需要对Zabbix很了解,这里只是提出监控的需求. 需求一:监控MySQL的状态,当状态发生异常,发出报警: 需求二:监控MySQL的操作,并用图表展现: 2.自定义脚本监控扩展Agent Zabbix Server与Agent之间监控数据的采集主要是通过Zabbix Server主动向Agent询问某个Key的值,Agent会根据Key去调用相应的函数去获取
-
关于zabbix自定义监控项和触发器问题
目录 一.监控端口 关系说明 操作 二.监控服务 关系说明 操作 三.模板的导入和导出 一.监控端口 关系说明 触发器: 根据客户端的脚本获取值,当客户端的某项值达到要求后,将发出告警 监控项:根据客户端的脚本获取值,可设定采集值得间隔时间,将值保留记录下来,可形成曲线图 应用集:用来分类存放监控项,比如将监控80,8080等web服务的监控项放在WEB应用集中,将监控22,21等小服务的监控项放入SMALL应用集中. 模板:模板是一套定义好的监控项的合集,任何主机连接模板,则将模板中的监控项等
-
zabbix监控vmware exsi主机的图文步骤
1.进入虚拟化vcenter中,用浏览器登录(客户端没找到地方设置),新建一个只读用户zabbix. 2. 登录vcenter客户端,将新建用户授权为只读 授权过后可以使用新账号登录测试一下. 3.开启exsi主机Managed Object Browser (MOB)功能,没有就默认开着的. 去web client主机系统高级设置里面打开 Config.HostAgent.plugins.solo.enableMob 4.打开zabbix,配置server参数,按照以下参数,没有的就添加进去
-
详解ZABBIX监控ESXI主机的问题
目录 一.环境 二.配置zabbix服務端 三.配置ESXI 四.添加主机监控 一.环境 Zabbix5.2 Centos8.2 ESXI6.5 二.配置zabbix服務端 1.编译安装Zabbix-server的应加上 –with-libxml2 和 –with-libcurl 编译选项 2.yum安装zabbix的是默认安装的 3.修改zabbix配置文件: vim /etc/zabbix/zabbix_server.conf # 找到以下参数取消注释并配置相应数值 StartVMwareC
-
Zabbix对Kafka topic积压数据监控的问题(bug优化)
目录 简述 分区自动发现 获取监控项“test-group/test/分区X”的Lag 最终优化后脚本 接入Zabbix 1.Zabbix配置文件 2.Zabbix自动发现 3.监控项配置 4.告警信息 简述 <Zabbix对Kafka topic积压数据监控>一文的目的是通过Zabbix自动发现实现对多个消费者组的Topic及Partition的Lag进行监控.因在实际监控中发现有问题,为给感兴趣的读者不留坑,特通过此文对监控进行优化调整. 分区自动发现 # 未优化前的计算方式: # 自动发
-
Zabbix对Kafka topic积压数据监控的解决方案
目录 Kafka 需求 解决方案 1.监控分析 2.监控思路 (1) 消费者组管理 (2)分区自动发现 (3)获取监控项“test-group/test/分区X”的Lag (4)最终脚本 3.Zabbix 自动发现配置 4.告警信息 Kafka Apache Kafka是一个分布式发布-订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点. Kafka适合离线和在线消息消费. Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失.Kafka构建在Zoo
-
Java Kafka 消费积压监控的示例代码
后端代码: Monitor.java代码: package com.suncreate.kafkaConsumerMonitor.service; import com.suncreate.kafkaConsumerMonitor.model.ConsumerInfo; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.KafkaConsumer; i
-
python每5分钟从kafka中提取数据的例子
我就废话不多说了,直接上代码吧! import sys sys.path.append("..") from datetime import datetime from utils.kafka2file import KafkaDownloader import os """ 实现取kafka数据,文件按照取数据的间隔命名 如每5分钟从kafka取数据写入文件中,文件名为当前时间加5 """ TOPIC = "rtz
-
分布式监控系统之Zabbix主动、被动及web监控的过程详解
前文我们了解了zabbix的网络发现功能,以及结合action实现自动发现主机并将主机添加到zabbix hosts中,链接指定模板进行监控:回顾请参考https://www.jb51.net/article/200678.htm:今天我们来了解下zabbix的主动监控.被动监控以及web监控相关话题: 1.什么是主动监控?什么是被动监控? 我们知道获取数据的方式有两种,一种是get,一种是push:在zabbix中描述主动监控和被动监控都是站在agent的一方来描述的:我们把agent主动将数
-
kafka topic 权限控制(设置删除权限)
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素. 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决. 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案.Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消
-
对python操作kafka写入json数据的简单demo分享
如下所示: 安装kafka支持库pip install kafka-python from kafka import KafkaProducer import json ''' 生产者demo 向test_lyl2主题中循环写入10条json数据 注意事项:要写入json数据需加上value_serializer参数,如下代码 ''' producer = KafkaProducer( value_serializer=lambda v: json.dumps(v).encode('utf-8'
-
Redis做数据持久化的解决方案及底层原理
目录 数据持久化 RDB 生成方法 save bgsave 优点 缺点 AOF AOF记录过程 ServerCron 作用 server.hz 写入策略 End 之前的文章介绍了Redis的简单数据结构的相关使用和底层原理,这篇文章我们就来聊一下Redis应该如何保证高可用. 数据持久化 我们知道虽然单机的Redis虽然性能十分的出色, 单机能够扛住10w的QPS,这是得益于其基于内存的快速读写操作,那如果某个时间Redis突然挂了怎么办?我们需要一种持久化的机制,来保存内存中的数据,否则数据就
-
浅谈Mysql大数据分页查询解决方案
目录 1.简介 2.分页插件使用 3.sql测试与分析 3.1 limit现象分析 3.2 解决之道 4 测试时走过的坑 4.1 百万数据内容都一样 4.2 写sql时,把"77"写成了77: 4.3 一个有趣的现象 总结 1.简介 之前,面阿里的时候,有个面试官问我有没有使用过分页查询,我说有,他说分页查询是有问题的,怎么解决:后来这个问题我没有回答出来:本着学习的态度,今天来解决一下这个问题: 2.分页插件使用 1.pom文件 <dependency> <grou
-
详解Swoole TCP流数据边界问题解决方案
目录 1. 数据发送过程 2. 什么是数据边界 2.1 代码演示 3.EOF 解决方案 3.1 open_eof_check 3.2 open_eof_split 3.3 open_eof_check 和 open_eof_split 差异 4. 固定包头 + 包体解决方案 5. 总结 6. 扩展知识 6.1 字节序 1. 数据发送过程 首先由客户端将数据发往缓冲区 (服务端并不是直接收到的), 对于客户端来说,这次的数据即是发送成功了, 对于服务端是否真正的收到他是不知道的, 然后再由服务端从