C#词法分析器之词法分析的使用详解
虽然文章的标题是词法分析,但首先还是要从编译原理说开来。编译原理应该很多人都听说过,虽然不一定会有多么了解。
简单的说,编译原理就是研究如何进行编译——也就如何从代码(*.cs 文件)转换为计算机可以执行的程序(*.exe 文件)。当然也有些语言如 JavaScript 是解释执行的,它的代码是直接被执行的,不需要生成可执行程序。
编译过程是很复杂的,它涉及到很多步骤,直接拿《编译原理》(Compilers: Principles, Techniques and Tools,红龙书)上的图来看:
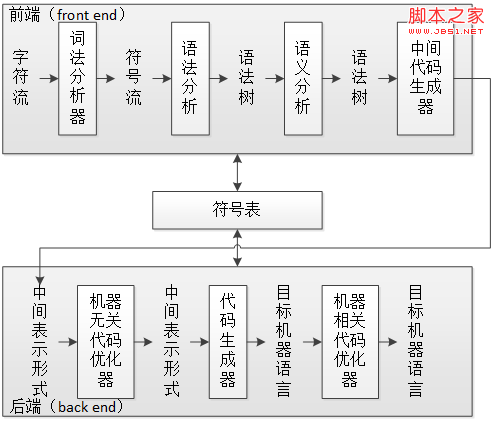
图 1 编译器的各个步骤,其实是我根据书上的图综合了一下后画的
这里给出了 7 个步骤(后面的优化步骤是可选的),其中前 4 个步骤是分析部分(也被称为前端 front end),是把源程序分解为多个组成要素,并在这些要素上加上语法结构,最后把信息存放在符号表(symbol table)中。后三个步骤是综合部分(也成为后端 back end),它们根据中间表示和符号表中的信息构造期待的目标程序。
将编译器分为这么多步骤,其好处就是使得每个步骤更加简单,从而使编译器更加容易设计,也可以利用很多现有的工具——例如词法分析器可以用 Lex 或 Flex 生成,语法分析器可以用 Yacc 或 Bison 生成,几乎不用做太多编码工作就能得到一颗语法树,前端的工作也就完成的差不多了。而至于后端,也有很多现有的技术可以使用,例如现成的虚拟机(CLR 或 Java,只要翻译成相应的 IL 就可以了)。
这个系列的文章,说的就是编译原理的第一步:语法分析。大部分算法和理论都来自《编译原理》,其余的部分则是自己搞出来的,或者是参考了 Flex 的实现(这里的 Flex 是指 fast lexical analyzer generator,一种著名的提供词法分析的程序,而不是 Adobe 的 Flex)。
我会尽量完整的介绍词法分析器的编写过程,包括一些细节的实现。当然,目前只能根据正则表达式定义得到一个可以用来进行词法分析的对象,要想达到 Flex 那样直接根据词法定义文件生成词法分析器源代码,还有很多工作要做,不是短期内能够搞定的。
本篇文章作为系列的第一篇,将会对词法分析做综合的概述,介绍一下其中用到的技术和大致的流程。
一、词法分析介绍
词法分析(lexical analysis)或扫描(scanning)是编译器的第一个步骤。词法分析器读入组成源程序的字符流,并且将它们组织成有意义的词素(lexeme)的序列,并对每个词素产生词法单元(token)作为输出。
简单的来说,词法分析就是将源程序(可以认为是一个很长的字符串)读进来,并且“切”成小段(每一段就是一个词法单元 token),每个单元都是有具体的意义的,例如表示某个特定的关键词,或者代表一个数字。而这个词法单元在源程序中对应的文本,就叫做“词素”。
以计算器来举例,12+34*9 这一段“源程序”的词法分析过程如下所示:
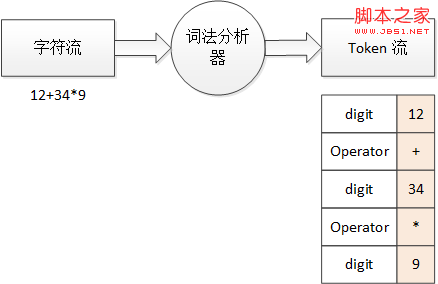
图 2 算式的词法分析过程
一段对计算机来说豪无意义的字符串,经过语法分析后就得到了略微有意义的 Token 流。digit 就表示这个词法单元对应的是数字,operator 则表示操作符,后面相应的数字和符号(粉色背景)就是词素。同时,程序中一些不必要的空白、注释也可以由词法分析器来过滤掉,这样,之后的语法分析等步骤处理起来就会容易得多。
在实际的程序中,词法单元都会以枚举或数字来表示这是哪一类词法单元。我的 Token.cs 定义如下所示:
里面的 Index 和 Text 属性不必多做解释,Start 和 End 是用来在源文件中定位的(索引,行数和列数),Value 则仅仅是为了方便传递一些值而设。
二、如何描述词素
现在知道了词法分析可以将词素分割开来,那么词素是怎么描述的?或者说,为什么 12、+ 和 34 都是词素,而 1、 2+3 和 4 就不是词素呢?这就需要用到模式了。
模式(pattern)描述了一个词法单元的词素可能具有的形式。
也就是说,我定义了 digit 模式为“由一个或多个数字组成的序列”,和 operator 模式为“单个 + 或 * 字符”,词法分析器就知道 12 是一个词素,而 2+3 则不是词素了。
现在,模式一般都是用正则表达式(regular expression)表示的,这里所谓的正则表达式,与平常所说的正则表达式(例如 System.Text.RegularExpressions.Regex 类)形式完全相同,功能却更有限,它只包含了字符串的匹配能力,而没有分组、引用和替换的能力。简单的举个例子,a+ 这个正则表达式就表示“由一个或多个字符 a 组成的序列”。关于正则表达式更多详细信息,我会在后面的文章中列出来,当然,有限的参考一下 System.Text.RegularExpressions.Regex 也是可以的。
在本系列之后的文章中所提的正则表达式,都指的是这种只具有字符串匹配能力的正则表达式,大家一定要注意不要与 System.Text.RegularExpressions.Regex 相混淆。
三、如何构造词法分析器
说完了词素的描述,就到如何根据词素的描述来构造词法分析器了。大致的流程如下:
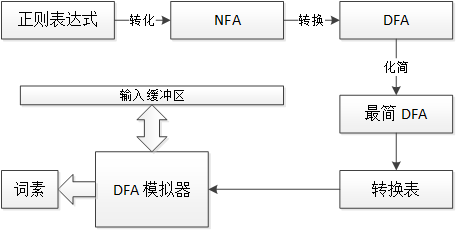
图 3 构造词法分析器
从上图来看,定义了模式的正则表达式,经过 NFA 转换、DFA 转换和 DFA 化简,得到了一张转换表。这张转换表再加上一个固定的 DFA 模拟器,就组成了词法分析器。它不断的从输入缓冲区中读取字符,利用自动机来识别词素并输出。可以说,词法分析的精华就是如何得到这张转换表。
说了这么多,词法分析算是简单的介绍完了,从下一篇开始,就是如何一步一步实现完整的词法分析器。
相关推荐
-

javascript 词法作用域和闭包分析说明
复制代码 代码如下: var classA = function(){ this.prop1 = 1; } classA.prototype.func1 = function(){ var that = this, var1 = 2; function a(){ return function(){ alert(var1); alert(this.prop1); }.apply(that); }; a(); } var objA = new ClassA(); objA.func1(); 大家应
-
C#词法分析器之输入缓冲和代码定位的应用分析
一.输入缓冲 在介绍如何进行词法分析之前,先来说说一个不怎么被提及的问题--怎么从源文件中读取字符流.为什么这个问题这么重要呢?是因为在词法分析中,对字符流是有要求的,它必须能够支持回退操作(就是将多个字符放回到流中,以后会再次被读取). 先来解释下为什么需要支持回退操作,举个简单的例子来说,现在要对两个模式进行匹配: 图 1 流的回退过程 上面是一个简单的匹配过程,仅为了展示回退过程,在后面实现 DFA 模拟器时会详细解释是如何匹配词素的. 现在来看看 C# 中与输入相关的类,有 Stream
-
java 字符串词频统计实例代码
复制代码 代码如下: package com.gpdi.action; import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map; public class WordsStatistics { class Obj { int count ; Obj(int count)
-
java使用Nagao算法实现新词发现、热门词的挖掘
采用Nagao算法统计各个子字符串的频次,然后基于这些频次统计每个字符串的词频.左右邻个数.左右熵.交互信息(内部凝聚度). 名词解释: Nagao算法:一种快速的统计文本里所有子字符串频次的算法.详细算法可见http://www.doc88.com/p-664123446503.html 词频:该字符串在文档中出现的次数.出现次数越多越重要. 左右邻个数:文档中该字符串的左边和右边出现的不同的字的个数.左右邻越多,说明字符串成词概率越高. 左右熵:文档中该字符串的左边和右边出现的不
-
C#词法分析器之转换DFA详解
在上一篇文章中,已经得到了与正则表达式等价的 NFA,本篇文章会说明如何从 NFA 转换为 DFA,以及对 DFA 和字符类进行化简. 一.DFA 的表示 DFA 的表示与 NFA 比较类似,不过要简单的多,只需要一个添加新状态的方法即可.Dfa 类的代码如下所示: 复制代码 代码如下: namespace Cyjb.Compiler.Lexer { class Dfa { // 在当前 DFA 中创建一个新状态. DfaState NewState()
-
Python的词法分析与语法分析
词法分析(Lexical Analysis):分析由字符组成的单词是否合法,如果没有问题的话,则产生一个单词流. 语法分析(Syntactic Analysis):分析由单词组成的句子是否合法,如果没有问题的话,则产生一个语法树. 在词法分析器分析源代码文本的时候,有一个概念需要明确: 1.物理行:由回车字符序列(在Windows上是CR LF,在Unix上是LF)结尾的字符序列组成一个物理行. 2.逻辑行:由一个或者多个物理行组成,可以明确地使用反斜杠(\)来连接多个物理行使之成为一个逻辑行:
-
JavaEE Filter敏感词过滤的方法实例详解
我们在聊天的时候的或者留言的时候,有部分词是不允许发表出来.我们可以采用过滤器实现这个功能. 我们只是简单利用过滤器实现这个过滤的功能,有些地方没写的很全 前台代码: <body> <form action="<c:url value='/WordServlet'/>" method="post"> 姓名:<input type="text" name="name"/><b
-
C#词法分析器之正则表达式的使用
正则表达式是一种描述词素的重要表示方法.虽然正则表达式并不能表达出所有可能的模式(例如"由等数量的 a 和 b 组成的字符串"),但是它可以非常高效的描述处理词法单元时要用到的模式类型. 一.正则表达式的定义正则表达式可以由较小的正则表达式按照规则递归地构建.每个正则表达式 r 表示一个语言 L(r) ,而语言可以认为是一个字符串的集合.正则表达式有以下两个基本要素: 1.ϵ 是一个正则表达式, L(ϵ)=ϵ ,即该语言只包含空串(长度为 0 的字符串).2.如果 a 是一个字符
-
C#词法分析器之构造NFA详解
有了上一节中得到的正则表达式,那么就可以用来构造 NFA 了.NFA 可以很容易的从正则表达式转换而来,也有助于理解正则表达式表示的模式. 一.NFA 的表示方法 在这里,一个 NFA 至少具有两个状态:首状态和尾状态,如图 1 所示,正则表达式 $t$ 对应的 NFA 是 N(t),它的首状态是 $H$,尾状态是 $T$.图中仅仅画出了首尾两个状态,其它的状态和状态间的转移都没有表示出来,这是因为在下面介绍的递归算法中,仅需要知道 NFA 的首尾状态,其它的信息并不需要关心. 图 1 NFA
-
利用Java实现简单的词法分析器实例代码
首先看下我们要分析的代码段如下: 输出结果如下: 输出结果(a).PNG 输出结果(b).PNG 输出结果(c).PNG 括号里是一个二元式:(单词类别编码,单词位置编号) 代码如下: package Yue.LexicalAnalyzer; import java.io.*; /* * 主程序 */ public class Main { public static void main(String[] args) throws IOException { Lexer lexer = new