使用nodejs爬取前程无忧前端技能排行
最近准备换工作,需要更新一下技能树。为做到有的放矢,想对招聘方的要求做个统计。正好之前了解过nodejs,所以做了个爬虫搜索数据。
具体步骤:
1. 先用fiddler分析请求需要的header和body。
2. 再用superagent构建上述数据发送客户端请求。
3. 最后对返回的数据使用cheerio整理。
折腾了几个晚上,只搞出了个架子,剩余工作等有时间再继续开发。
/*使用fiddler抓包,需要配置lan代理,且设置如下参数*/
process.env.https_proxy = "http://127.0.0.1:8888";
process.env.http_proxy = "http://127.0.0.1:8888";
process.env.NODE_TLS_REJECT_UNAUTHORIZED = "0";
/*使用到的模块*/
var request = require('superagent'); //发送客户端请求
require('superagent-proxy')(request); //使用代理发送请求
var cheerio = require('cheerio'); //以jq类似的方法操作返回的字符,不需要用正则
require('superagent-charset')(request);//node不支持gbk,gb2312,this will add request.Request.prototype.charset.
var async = require('async'); //异步流控制模块
var fs = require('fs');
/*相关参数,通过fiddler抓包后复制过来*/
var ws = fs.createWriteStream('res.html',{flags:'w+'}); //a+追加的读写模式,w+覆盖
var loginUrl = "https://login.51job.com/login.php";
var searchUrl = "http://search.51job.com/jobsearch/search_result.php";
var queryStrings = "fromJs=1&jobarea=020000&keyword=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&keywordtype=2&lang=c&stype=2&postchannel=0000&fromType=1&confirmdate=9";
var loginForms = {
lang: 'c',
action: 'save',
from_domain: 'i',
loginname: '***', //自己的用户名和密码
password: '***',
verifycode: '',
isread: 'on'
};
var searchForms = {
lang: 'c',
stype: '2',
postchannel: '0000',
fromType: '1',
line: '',
confirmdate: '9',
from: '',
keywordtype: '2',
keyword: '%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91',
jobarea: '020000',
industrytype: '',
funtype: ''
};
var searchFormsString='lang=c&stype=2&postchannel=0000&fromType=1&line=&confirmdate=9&from=&keywordtype=2&keyword=%C7%B0%B6%CB%BF%AA%B7%A2&jobarea=020000&industrytype=&funtype=';
var proxy0 = process.env.https_proxy;
var proxy = process.env.http_proxy;
const agent = request.agent(); //agent()方法产生的实例会保存cookie供后续使用
request.post(loginUrl).proxy(proxy0).send(loginForms).end(function (err,res0) {
agent.post(searchUrl)
.proxy(proxy) //proxy()方法需紧跟在method方法之后调用,否则fiddler抓不到数据包
.type('application/x-www-form-urlencoded')
.query(queryStrings) //使用字符串格式
.send(searchFormsString)
.charset('gbk') //通过charset可知编码字符格式,不设置会有乱码
.end(function (err, res) {
/* 以下是处理返回数据的逻辑代码*/
var $ = cheerio.load(res.text); //res.text是返回的报文主体
async.each($('.el.title').nextAll('.el'), function(v, callback) {
//将多余的内容删除,保留岗位、公司链接
$(v).prepend($(v).find('.t1 a'));
$(v).find('.t1').remove();
ws.write($.html(v), 'utf8');
}, function(err) {
console.log(err);
});
console.log('successful');
})
});
//jquery内置document元素为root,cheerio需要通过load方法传入,然后用选择器查找指定元素,再执行相应操作。
// $.html(el);静态方法,返回el元素的outerHtml
//TODO
// 1.当前只请求到一页数据,还需构建所有页数的请求列表
// 2.向每条数据的岗位链接发送请求,获取技能关键字,存入文件中
// 3.node中io操作是异步的,且没有锁的概念,如何并发地向同一个文件正确地写入数据
结果显示如下:
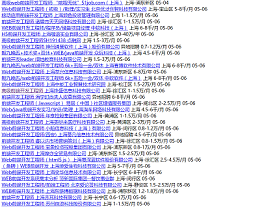
以上所述是小编给大家介绍的使用nodejs爬前程无忧前端技能排行,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-

node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Android.ios作为关键词进行爬取,爬到的数据以json格式储存到本地,为了方便观察,我将数据整理了一下供大家参考 数据结果 上述数据为3月13日22时爬取的数据,可大致反映各个城市对不同语言的需求量. 爬取过程展示 控制并发进行爬取 爬取到的数据文件 json数据文件 爬虫程序 实现思路 请求拉钩网的
-
node爬取微博的数据的简单封装库nodeweibo使用指南
一.前言 就在去年12月份,有个想法是使用node爬取微博的数据,于是简单的封装了一个nodeweibo这个库.时隔一年,没有怎么维护,中途也就将函数形式改成了配置文件.以前做的一些其他的项目也下线了,为了是更加专注前端 & node.js.偶尔看到下载量一天超过60多,持续不断的有人在用这个库,但是看下载量很少也就没有更新.但是昨天,有人pull request这个分支了,提出一些中肯的建议和有用的代码.于是就认真回顾了下nodeweibo,发布了v2.0.3这个版本. 二.什么是nodewe
-
node+experss实现爬取电影天堂爬虫
上周写了一个node+experss的爬虫小入门.今天继续来学习一下,写一个爬虫2.0版本. 这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂.因为每个周末都会在电影天堂下载一部电影来看看. talk is cheap,show me the code! 抓取页面分析 我们的目标: 1.抓取电影天堂首页,获取左侧最新电影的169条链接 2.抓取169部新电影的迅雷下载链接,并且并发异步抓取. 具体分析如下: 1.我们不需要抓取迅雷的所有东西,只需要下载最新发布的电影即可,比如下面的左侧栏.一共有
-
Node.js环境下编写爬虫爬取维基百科内容的实例分享
基本思路 思路一(origin:master):从维基百科的某个分类(比如:航空母舰(key))页面开始,找出链接的title属性中包含key(航空母舰)的所有目标,加入到待抓取队列中.这样,抓一个页面的代码及其图片的同时,也获取这个网页上所有与key相关的其它网页的地址,采取一个类广度优先遍历的算法来完成此任务. 思路二(origin:cat):按分类进行抓取.注意到,维基百科上,分类都以Category:开头,由于维基百科有很好的文档结构,很容易从任一个分类,开始,一直把其下的所有分类全都抓
-
利用Node.js制作爬取大众点评的爬虫
前言 Node.js天生支持并发,但是对于习惯了顺序编程的人,一开始会对Node.js不适应,比如,变量作用域是函数块式的(与C.Java不一样):for循环体({})内引用i的值实际上是循环结束之后的值,因而引起各种undefined的问题:嵌套函数时,内层函数的变量并不能及时传导到外层(因为是异步)等等. 一. API分析 大众点评开放了查询餐馆信息的API,这里给出了城市与cityid之间的对应关系, 链接:http://m.api.dianping.com/searchshop.json
-
利用node.js写一个爬取知乎妹纸图的小爬虫
前言 说起写node爬虫的原因,真是羞羞呀.一天,和往常一样,晚上吃过饭便刷起知乎来,首页便是推荐的你见过最漂亮的女生长什么样?,点进去各种漂亮的妹纸爆照啊!!!,看的我好想把这些好看的妹纸照片都存下来啊!一张张点击保存,就在第18张得时候,突然想起.我特么不是程序员么,这种手动草做的事,怎么能做,不行我不能丢程序员的脸了,于是便开始这次爬虫之旅. 原理 初入爬虫的坑,没有太多深奥的理论知识,要获取知乎上帖子中的一张图片,我把它归结为以下几步. 准备一个url(当然是诸如你见过最漂亮的女生长什么
-
利用node.js爬取指定排名网站的JS引用库详解
前言 本文给大家介绍的爬虫将从网站爬取排名前几的网站,具体前几名可以具体设置,并分别爬取他们的主页,检查是否引用特定库.下面话不多说了,来一起看看详细的介绍: 所用到的node主要模块 express 不用多说 request http模块 cheerio 运行在服务器端的jQuery node-inspector node调试模块 node-dev 修改文件后自动重启app 关于调试Node 在任意一个文件夹,执行node-inspector,通过打开特定页面,在页面上进行调试,然后运行app
-
使用nodejs爬取前程无忧前端技能排行
最近准备换工作,需要更新一下技能树.为做到有的放矢,想对招聘方的要求做个统计.正好之前了解过nodejs,所以做了个爬虫搜索数据. 具体步骤: 1. 先用fiddler分析请求需要的header和body. 2. 再用superagent构建上述数据发送客户端请求. 3. 最后对返回的数据使用cheerio整理. 折腾了几个晚上,只搞出了个架子,剩余工作等有时间再继续开发. /*使用fiddler抓包,需要配置lan代理,且设置如下参数*/ process.env.https_proxy
-
nodejs实现爬取网站图片功能
通过实例给大家讲解nodejs实现爬取网站图片功能,以下就是全部内容: 原理: 爬虫是最明显的IO密集型应用场景,显然用node,使得I/O等待开销小数据挖掘比较方便 借助express模块来搭建node服务 并使用request模块获取目标页面的html代码 下载cheerio模块对html代码做处理(cheerio类似jQuery的语法,所以好用又方便) 环境配置: npm install express request cheerio --save (1)引入各个模块 var http =
-
nodejs+axios爬取html出现中文乱码并解决示例
目录 一.乱码原因 二.解决办法 一.乱码原因 当使用 nodejs + axios 来爬取某个 url 对应的 html 时,出现中文乱码. 在 HTML 页面的 head 中没有设置 <meta charset="UTF-8"> ,而 html 页面默认是 GBK 的编码. 使用 axios 发送请求 responseEncoding 默认是 utf8,造成编码不一致,导致最后获取到的 html 内容出现中文乱码. 二.解决办法 以二进制流的形式获取 HTML 内容,再
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi
-
使用python爬取抖音视频列表信息
如果看到特别感兴趣的抖音vlogger的视频,想全部dump下来,如何操作呢?下面介绍介绍如何使用python导出特定用户所有视频信息 抓包分析 Chrome Deveploer Tools Chrome 浏览器开发者工具 在抖音APP端,复制vlogger主页地址, 比如: http://v.douyin.com/kGcU4y/ , 在PC端用chrome浏览器打卡,并模拟手机,这里选择iPhone, 然后把复制的主页地址,放到浏览器进行访问,页面跳转到 https://www.iesdouy
-
如何利用Node.js做简单的图片爬取
目录 介绍 安装引入 创建实例 元素捕获 下载图片 结语 介绍 爬虫的主要目的是收集互联网上公开的一些特定数据.利用这些数据我们可以能进行分析一些趋势对比,或者训练模型做深度学习等等.本期我们就将介绍一个专门用于网络抓取的 node.js 包—— node-crawler ,并且我们将用它完成一个简单的爬虫案例来爬取网页上图片并下载到本地. node-crawler 是一个轻量级的 node.js 爬虫工具,兼顾了高效与便利性,支持分布式爬虫系统,支持硬编码,支持http前级代理.而且,它完全是
-
用.NET Core写爬虫爬取电影天堂
自从上一个项目从.NET迁移到.NET core之后,磕磕碰碰磨蹭了一个月才正式上线到新版本. 然后最近又开了个新坑,搞了个爬虫用来爬dy2018电影天堂上面的电影资源.这里也借机简单介绍一下如何基于.NET Core写一个爬虫. PS:如有偏错,敬请指明- PPS:该去电影院还是多去电影院,毕竟美人良时可无价. 准备工作(.NET Core准备) 首先,肯定是先安装.NET Core咯.下载及安装教程在这里: http://www.jb51.net/article/87907.htm http