Python 遍历列表里面序号和值的方法(三种)
三种遍历列表里面序号和值的方法:
最近学习python这门语言,感觉到其对自己的工作效率有很大的提升,特在情人节这一天写下了这篇博客,下面废话不多说,直接贴代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
if __name__ == '__main__':
list = ['html', 'js', 'css', 'python']
# 方法1
print '遍历列表方法1:'
for i in list:
print ("序号:%s 值:%s" % (list.index(i) + 1, i))
print '\n遍历列表方法2:'
# 方法2
for i in range(len(list)):
print ("序号:%s 值:%s" % (i + 1, list[i]))
# 方法3
print '\n遍历列表方法3:'
for i, val in enumerate(list):
print ("序号:%s 值:%s" % (i + 1, val))
# 方法3
print '\n遍历列表方法3 (设置遍历开始初始位置,只改变了起始序号):'
for i, val in enumerate(list, 2):
print ("序号:%s 值:%s" % (i + 1, val))
运行代码后的结果如下图所示:
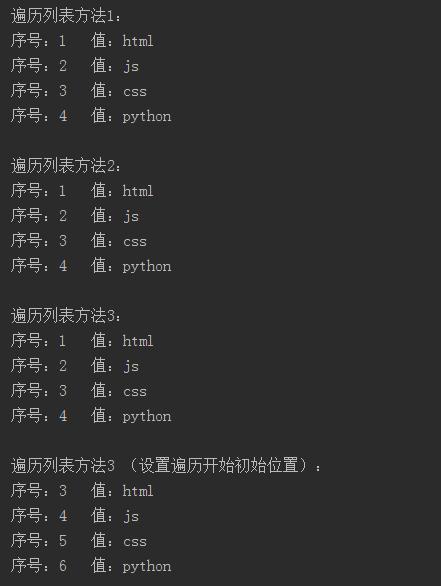
在此介绍一下enumerate()方法,通过查看help()函数来查看,查询结果如下:

最后提示一下,enumerate()函数的第二个参数只是改变了序号的起始值,并没有改变其他的东东
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-

Python实现遍历目录的方法【测试可用】
本文实例讲述了Python实现遍历目录的方法.分享给大家供大家参考,具体如下: # *-* coding=gb2312 *-* import os.path import shutil def traveltree(curPath,count): if not os.path.exists(curPath): return if os.path.isfile(curPath): fileName =os.path.basename(curPath) print '\t' *count+ '├─'
-
Python遍历目录中的所有文件的方法
os.walk生成器 os.walk(PATH), PATH是个文件夹路径,当然可以用.或者../这样啦. 返回的是个三元元组为元素的列表, 每个元素代表了一个文件夹下的内容.第一个就是当前文件夹下内容. 返回的三元元组代表(该工作文件夹, 该文件夹下的文件夹的列表, 该文件夹下文件的列表). 所以, 获得所有子文件夹, 就是(d代表这三元元组): os.path.join(d[0],d[1]); 获得所有子文件, 就是: os.path.join(d[0],d[2]); 以下例子使用了两套循环
-
Python多维/嵌套字典数据无限遍历的实现
最近拾回Django学习,实例练习中遇到了对多维字典类型数据的遍历操作问题,Google查询没有相关资料-毕竟是新手,到自己动手时发现并非想象中简单,颇有两次曲折才最终实现效果,将过程记录下来希望对大家有用. 实例数据(多重嵌套): person = {"male":{"name":"Shawn"}, "female":{"name":"Betty","age":23
-
遍历python字典几种方法总结(推荐)
如下所示: aDict = {'key1':'value1', 'key2':'value2', 'key3':'value3'} print '-----------dict-------------' for d in aDict: print "%s:%s" %(d, aDict[d]) print '-----------item-------------' for (k,v) in aDict.items(): print '%s:%s' %(k, v) #效率最高 prin
-
Python 遍历子文件和所有子文件夹的代码实例
最近看ECShop到网上找资料,发现好多说明ECShop的文件结构不全面,于是想自己弄个出来.但这是个无聊耗时的工作,自己就写了个Python脚本,可以递归遍历目录下的所有文件和所有子目录,并将结果记录到一个.xml文件中(因为想使用Notepad++的代码折叠功能,所以使用.xml文件). 下面就是Python代码: # -*- coding: cp936 -*- ############################################# # Written By Qian_F
-
Python简单遍历字典及删除元素的方法
本文实例讲述了Python简单遍历字典及删除元素的方法.分享给大家供大家参考,具体如下: 这种方式是一定有问题的: d = {'a':1, 'b':2, 'c':3} for key in d: d.pop(key) 会报这个错误:RuntimeError: dictionary changed size during iteration 这种方式Python2可行,Python3还是报上面这个错误. d = {'a':1, 'b':2, 'c':3} for key in d.keys():
-
python 遍历字符串(含汉字)实例详解
python 遍历字符串(含汉字)实例详解 s = "中国china" for j in s: print j 首先一个,你这个'a'是什么编码?可能不是你所想的gbk >>> a='中国' >>> a 这样试试看,如果出来是6个字(word),说明是utf-8,如果是4个字,说明gbk. 另外,不管是utf-8还是gbk,都不能这样遍历,因为这里它会一个字一个字拿出来.虚拟机把a当成一个长度为len(a)的字符串了. 接下来是遍历问题. Linux
-
python 循环遍历字典元素的简单方法
一个简单的for语句就能循环字典的所有键,就像处理序列一样: In [1]: d = {'x':1, 'y':2, 'z':3} In [2]: for key in d: ...: print key, 'corresponds to', d[key] ...: y corresponds to 2 x corresponds to 1 z corresponds to 3 在python2.2之前,还只能用beys等字典方法来获取键(因为不允许直接迭代字典).如果只需要值,可以使用d.val
-
Python 遍历列表里面序号和值的方法(三种)
三种遍历列表里面序号和值的方法: 最近学习python这门语言,感觉到其对自己的工作效率有很大的提升,特在情人节这一天写下了这篇博客,下面废话不多说,直接贴代码 #!/usr/bin/env python # -*- coding: utf-8 -*- if __name__ == '__main__': list = ['html', 'js', 'css', 'python'] # 方法1 print '遍历列表方法1:' for i in list: print ("序号:%s 值:%s&
-
python 遍历列表提取下标和值的实例
如下所示: for index,value in enumerate(['apple', 'oppo', 'vivo']): print(index,value) 以上这篇python 遍历列表提取下标和值的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
在python带权重的列表中随机取值的方法
1 random.choice python random模块的choice方法随机选择某个元素 foo = ['a', 'b', 'c', 'd', 'e'] from random import choice print choice(foo) 2 random.sample 使用python random模块的sample函数从列表中随机选择一组元素 list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] slice = random.sample(list, 5)
-
如何利用python实现列表嵌套字典取值
目录 一.实例 二.解决思路 三.代码示例 一.实例 将以下列表的backup_unit_id全部提取出来 示例: dbs = [{ "backup_unit_id": 163, "data_node_id": 2, "attribute": { "convertor_id": 4, "channel_num":
-
Python遍历列表时删除元素案例
tk在科学养猪群里问bluerust.scz是否碰上过这个Python坑, 示例1: bas = [ 'ba1', 'ba2', 'ba3', 'ba4', 'ba5' ] for ba in bas : print( ba ) if ( ba.find( 'ba' ) != -1 ) : bas.remove( ba ) print( bas ) print( bas ) 即遍历list的过程中动态删除元素. 上述代码输出如下: ba1 ['ba2', 'ba3', 'ba4', 'ba5']
-
详解Python遍历列表时删除元素的正确做法
一.问题描述 这是在工作中遇到的一段代码,原理大概和下面类似(判断某一个元素是否符合要求,不符合删除该元素,最后得到符合要求的列表): a = [1,2,3,4,5,6,7,8] for i in a: if i>5: pass else: a.remove(i) print(a) 运行结果: 二.问题分析 因为删除元素后,整个列表的元素会往前移动,而i却是在最初就已经确定了,是不断增大的,所以并不能得到想要的结果. 三.解决方法 1.遍历在新的列表操作,删除是在原来的列表操作 a = [1,2
-
Python实现列表转换成字典数据结构的方法
本文实例讲述了Python实现列表转换成字典数据结构的方法.分享给大家供大家参考,具体如下: ''' [ {'symbol': 101, 'sort': 1, 'name': 'aaaa'}, {'symbol': 102, 'sort': 2, 'name': 'bbbb'}, {'symbol': 103, 'sort': 3, 'name': 'cccc'}, {'symbol': 104, 'sort': 4, 'name': 'dddd'}, {'symbol': 105, 'sort
-
Python找出列表中出现次数最多的元素三种方式
通过三种方式给大家介绍,具体详情如下所示: 方式一: 原理:创建一个新的空字典,用循环的方式来获取列表中的每一个元素,判断获取的元素是否存在字典中的key,如果不存在的话,将元素作为key,值为列表中元素的count # 字典方法 words = [ 'my', 'skills', 'are', 'poor', 'I', 'am', 'poor', 'I', 'need', 'skills', 'more', 'my', 'ability', 'are', 'so', 'poor' ] dict
-
Python使用迭代器捕获Generator返回值的方法
本文实例讲述了Python使用迭代器捕获Generator返回值的方法.分享给大家供大家参考,具体如下: 用for循环调用generator时,发现拿不到generator的return语句的返回值.如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中: #!/usr/bin/env python # -*- coding: utf-8 -*- def fib(max): n, a, b = 0, 0, 1 while n < max:
-
python实现计算资源图标crc值的方法
本文实例讲述了python实现计算资源图标crc值的方法,分享给大家供大家参考.具体方法如下: 实现该功能的关键在于解析资源信息,找到icon的数据,然后计算这些数据的crc 具体实现代码如下: def _get_iconcrc(self, file_path): """ Generates the crc32 hash of the icon of the file. @return: str, the str value of the file's icon "