Python 爬虫学习笔记之单线程爬虫
介绍
本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图

怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学院的全部课程信息,像下面这样

这个时候进行翻页,观看网址的变化,首先,第一页的网址是 http://www.maiziedu.com/course/list/, 第二页变成了 http://www.maiziedu.com/course/list/all-all/0-2/, 第三页变成了 http://www.maiziedu.com/course/list/all-all/0-3/ ,可以看到,每次翻一页,0后面的数字就会递增1,然后就有人会想到了,拿第一页呢?我们尝试着将 http://www.maiziedu.com/course/list/all-all/0-1/ 放进浏览器的地址栏,发现可以打开第一栏,那就好办了,我们只需要使用 re.sub() 就可以很轻松的获取到任何一页的内容。获取到网址链接之后,下面要做的就是获取网页的源代码,首先右击查看审查或者是检查元素,就可以看到以下界面
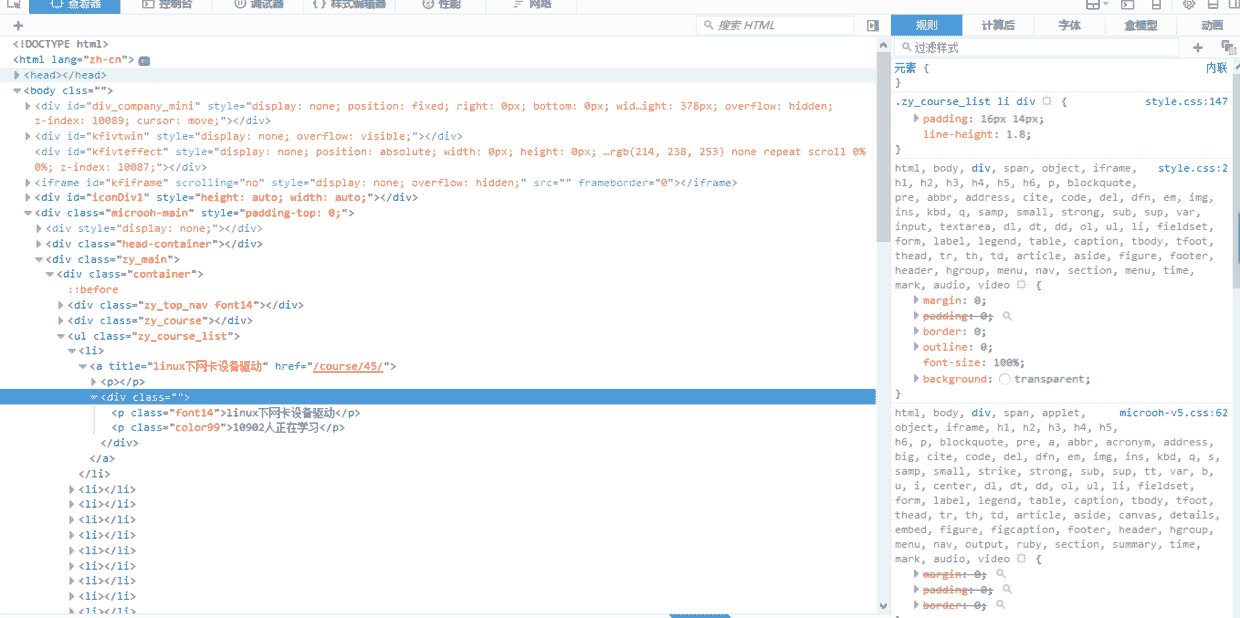
找到课程所在的位置以后,就可以很轻松的利用正则表达式将我们需要的内容提取出来,至于怎么提取,那就要靠你自己了,尝试着自己去找规律才能有更大的收获。如果你实在不知道怎么提取,那么继续往下,看我的源代码吧
实战源代码
# coding=utf-8
import re
import requests
import sys
reload(sys)
sys.setdefaultencoding("utf8")
class spider():
def __init__(self):
print "开始爬取内容。。。"
def changePage(self, url, total_page):
nowpage = int(re.search('/0-(\d+)/', url, re.S).group(1))
pagegroup = []
for i in range(nowpage, total_page + 1):
link = re.sub('/0-(\d+)/', '/0-%s/' % i, url, re.S)
pagegroup.append(link)
return pagegroup
def getsource(self, url):
html = requests.get(url)
return html.text
def getclasses(self, source):
classes = re.search('<ul class="zy_course_list">(.*?)</ul>', source, re.S).group(1)
return classes
def geteach(self, classes):
eachclasses = re.findall('<li>(.*?)</li>', classes, re.S)
return eachclasses
def getinfo(self, eachclass):
info = {}
info['title'] = re.search('<a title="(.*?)"', eachclass, re.S).group(1)
info['people'] = re.search('<p class="color99">(.*?)</p>', eachclass, re.S).group(1)
return info
def saveinfo(self, classinfo):
f = open('info.txt', 'a')
for each in classinfo:
f.writelines('title : ' + each['title'] + '\n')
f.writelines('people : ' + each['people'] + '\n\n')
f.close()
if __name__ == '__main__':
classinfo = []
url = 'http://www.maiziedu.com/course/list/all-all/0-1/'
maizispider = spider()
all_links = maizispider.changePage(url, 30)
for each in all_links:
htmlsources = maizispider.getsource(each)
classes = maizispider.getclasses(htmlsources)
eachclasses = maizispider.geteach(classes)
for each in eachclasses:
info = maizispider.getinfo(each)
classinfo.append(info)
maizispider.saveinfo(classinfo)
以上代码并不难懂,基本就是正则表达式的使用,然后直接运行就可以看到开头我们的截图内容了,由于这是单线程爬虫,所以运行速度感觉有点慢,接下来还会继续更新多线程爬虫。
应小伙伴们的要求,下面附上requests爬虫库的安装和简单示例
首先安装pip包管理工具,下载get-pip.py. 我的机器上安装的既有python2也有python3。
安装pip到python2:
python get-pip.py
安装到python3:
python3 get-pip.py
pip安装完成以后,安装requests库开启python爬虫学习。
安装requests
pip3 install requests
我使用的python3,python2可以直接用pip install requests.
入门例子
import requests
html=requests.get("http://gupowang.baijia.baidu.com/article/283878")
html.encoding='utf-8'
print(html.text)
第一行引入requests库,第二行使用requests的get方法获取网页源代码,第三行设置编码格式,第四行文本输出。
把获取到的网页源代码保存到文本文件中:
import requests
import os
html=requests.get("http://gupowang.baijia.baidu.com/article/283878")
html_file=open("news.txt","w")
html.encoding='utf-8'
print(html.text,file=html_file)
相关推荐
-
python实现单线程多任务非阻塞TCP服务端
本文实例为大家分享了python实现单线程多任务非阻塞TCP服务端的具体代码,供大家参考,具体内容如下 # coding:utf-8 from socket import * # 1.创建服务器socket sock = socket(AF_INET, SOCK_STREAM) # 2.绑定主机和端口 addr = ('', 7788) # sock.bind(addr) # 3. 设置最大监听数目,并发 sock.listen(10) # 4. 设置成非阻塞 sock.setblocking(
-
python实现socket客户端和服务端简单示例
复制代码 代码如下: import socket#socket通信客户端def client(): mysocket=socket.socket(socket.AF_INET,socket.SOCK_STREAM) mysocket.connect(('127.0.0.1',8000)) mysocket.send('hello') while 1: data=mysocket.recv(1024) if data: pri
-
python单线程实现多个定时器示例
单线程实现多个定时器 NewTimer.py 复制代码 代码如下: #!/usr/bin/env python from heapq import *from threading import Timerimport threadingimport uuidimport timeimport datetimeimport sysimport math global TimerStampglobal TimerTimes class CancelFail(Exception): pass c
-

Python 爬虫学习笔记之单线程爬虫
介绍 本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图 怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学院的全部课程信息,像下面这样 这个时候进行翻页,观看网址的变化,首先,第一页的网址是 http://www.maiziedu.com/course/list/, 第二页变成了 http://www.maiziedu.com/course/list/all-all/0-2/, 第三页变成了 http://www.ma
-
Python 爬虫学习笔记之多线程爬虫
XPath 的安装以及使用 1 . XPath 的介绍 刚学过正则表达式,用的正顺手,现在就把正则表达式替换掉,使用 XPath,有人表示这太坑爹了,早知道刚上来就学习 XPath 多省事 啊.其实我个人认为学习一下正则表达式是大有益处的,之所以换成 XPath ,我个人认为是因为它定位更准确,使用更加便捷.可能有的人对 XPath 和正则表达式的区别不太清楚,举个例子来说吧,用正则表达式提取我们的内容,就好比说一个人想去天安门,地址的描述是左边有一个圆形建筑,右边是一个方形建筑,你去找吧,而使
-
python爬虫学习笔记之Beautifulsoup模块用法详解
本文实例讲述了python爬虫学习笔记之Beautifulsoup模块用法.分享给大家供大家参考,具体如下: 相关内容: 什么是beautifulsoup bs4的使用 导入模块 选择使用解析器 使用标签名查找 使用find\find_all查找 使用select查找 首发时间:2018-03-02 00:10 什么是beautifulsoup: 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(官方) beautif
-
python爬虫学习笔记之pyquery模块基本用法详解
本文实例讲述了python爬虫学习笔记之pyquery模块基本用法.分享给大家供大家参考,具体如下: 相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css操作 Dom操作 CSS操作 一个利用pyquery爬取豆瓣新书的例子 首发时间:2018-03-09 21:26 pyquery的介绍 pyquery允许对xml.html文档进行jQuery查询
-
python OpenCV学习笔记之绘制直方图的方法
本篇文章主要介绍了python OpenCV学习笔记之绘制直方图的方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考.一起跟随小编过来看看吧 官方文档 – https://docs.opencv.org/3.4.0/d1/db7/tutorial_py_histogram_begins.html 直方图会让你对图像的强度分布有一个全面的认识.它是一个在x轴上带有像素值(从0到255,但不总是),在y轴上的图像中对应的像素数量的图. 这只是理解图像的另一种方式.通过观察图像的直方图,你可以直
-
python OpenCV学习笔记实现二维直方图
本文介绍了python OpenCV学习笔记实现二维直方图,分享给大家,具体如下: 官方文档 – https://docs.opencv.org/3.4.0/dd/d0d/tutorial_py_2d_histogram.html 在前一篇文章中,我们计算并绘制了一维的直方图.它被称为一维,因为我们只考虑一个特性,即像素的灰度强度值.但是在二维直方图中,你可以考虑两个特征.通常它用于寻找颜色直方图,其中两个特征是每个像素的色调和饱和度值. 有一个python样例(samples/python/c
-
python OpenCV学习笔记直方图反向投影的实现
本文介绍了python OpenCV学习笔记直方图反向投影的实现,分享给大家,具体如下: 官方文档 – https://docs.opencv.org/3.4.0/dc/df6/tutorial_py_histogram_backprojection.html 它用于图像分割或寻找图像中感兴趣的对象.简单地说,它创建一个与我们的输入图像相同大小(但单通道)的图像,其中每个像素对应于属于我们对象的像素的概率.输出图像将使我们感兴趣的对象比其余部分更白. 该怎么做呢?我们创建一个图像的直方图,其中包
-
详解python OpenCV学习笔记之直方图均衡化
本文介绍了python OpenCV学习笔记之直方图均衡化,分享给大家,具体如下: 官方文档 – https://docs.opencv.org/3.4.0/d5/daf/tutorial_py_histogram_equalization.html 考虑一个图像,其像素值仅限制在特定的值范围内.例如,更明亮的图像将使所有像素都限制在高值中.但是一个好的图像会有来自图像的所有区域的像素.所以你需要把这个直方图拉伸到两端(如下图所给出的),这就是直方图均衡的作用(用简单的话说).这通常会改善图像的
-
Python树莓派学习笔记之UDP传输视频帧操作详解
本文实例讲述了Python树莓派学习笔记之UDP传输视频帧操作.分享给大家供大家参考,具体如下: 因为我在自己笔记本电脑上没能成功安装OpenCV-Contrib模块,因此不能使用人脸识别等高级功能,不过已经在树莓派上安装成功了,所以我想实现把树莓派上采集的视频帧传输到PC的功能,这样可以省去给树莓派配显示屏的麻烦,而且以后可能可以用在远程监控上. 1 UDP还是TCP 首先考虑用哪种传输方式,平常TCP用的非常多,但是像视频帧这种数据用TCP不是太合适,因为视频数据的传输最先要考虑的是速度而不
-
python OpenCV学习笔记
图像翻转 使用Python的一个包,imutils.使用下面的指令可以安装. pip install imutils imutils包的Github地址:https://github.com/jrosebr1/imutils CSDN镜像:https://codechina.csdn.net/mirrors/jrosebr1/imutils 可以在上面这个地址里面学习更多的使用方式. import cv2 import imutils ''' imutils.rotate 第一个参数是翻转的图像