Python爬虫文件下载图文教程
而今天我们要说的内容是:如果在网页中存在文件资源,如:图片,电影,文档等。怎样通过Python爬虫把这些资源下载下来。
1、怎样在网上找资源:
就是百度图片为例,当你如下图在百度图片里搜索一个主题时,会为你跳出一大堆相关的图片。
还有如果你想学英语,找到一个网站有很多mp3的听力资源,这些可能都是你想获取的内容。
现在是一个互联网的时代,只要你去找,基本上能找到你想要的任何资源。

2、怎样识别网页中的资源:
以上面搜索到的百度图片为例。找到了这么多的内容,当然你可以通过手动一张张的去保存,但这样做既费力又费事。你当然更希望通过程序自动去下载所找到的资源。要想代码识别这些资源,就要告诉代码这些资源有哪些特征,怎样在网页中找到它们。
打开浏览器的调试功能(不同浏览器可能有差别,不知道的百度一下吧)。找出网页中你想要下载资源的路径,如下图所示。如果有许多类似资源需要下载,则要找到识别这些资源地址的规律,然后告诉代码。
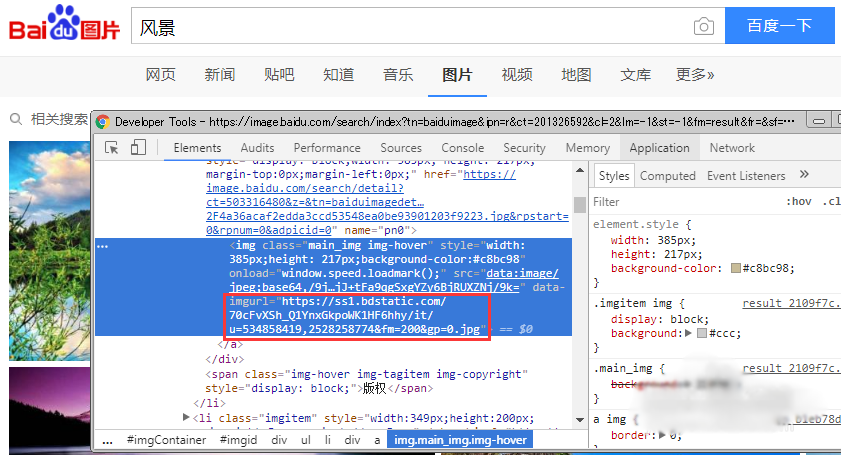
3、资源下载方法一:
代码很简单,直接上代码:
from urllib.request import urlretrieve
urlretrieve("图片URL", "./image.jpg")
直接通过urlretrieve函数就把URL对应的图片给下载到当前文件夹(./)中了,并把图片命名为image.jpg。
4、资源下载方法二:
还是直接看代码:
import requests
resource = requests.get("图片URL")
with open("./image.jpg", mode="wb") as fh:
fh.write(resource.content)
此下载方法要安装python的requests库。从功能上来说与下载方法一是一样的。python库的安装方法用pip就好。很简单,这里都不啰嗦了。
5、资源下载方法三:
看代码:
import requests
resource = requests.get("图片URL", stream=True)
with open("./image.jpg", mode="wb") as fh:
for chunk in resource.iter_content(chunk_size=100):
fh.write(chunk)
此方法与下载方法二的不同之处在于在get方法调用时使用了参数【stream=True】。而在写入的文件的时候是分块写入的。
什么意思呢:
前两种方法是把一个文件全部下载到内存后,再一起写入到硬盘文件中。
方法三是下载一定的量(这里指的是100字节)后,就写入到硬盘文件中,直到全部写完。
第三种方法的好处是,如果在下载大容量文件时,不会造成内存的过度使用。
6、资源下载说明一:
上述的代码都是通过下载图片资源为例子的,但所有其它资源,如文档,电影等的下载方式是一样的。关键是要正确的识别出网页中资源所对应的URL地址才能够正确的下载(因为有些资源是用的相对路径或加密后的路径)。
7、资源下载说明二:
上面例子中的代码都是下载单一资源的。如果要在同一网页中下载多个资源的思路如下:
1. 找出要下载资源的URL,并形成一个资源集合;
2. 把下载函数中的资源URL与保存路径参数化;
3. 遍历资源集合,依靠循环调用下载函数来达到多个资源下载的目的。
总结:以上就是本次介绍关于Python爬虫下载文件的所有知识点内容,感谢大家的阅读。
相关推荐
-

Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每
-
python3爬虫怎样构建请求header
写一个爬虫首先就是学会设置请求头header,这样才可以伪装成浏览器.下面小编我就来给大家简单分析一下python3怎样构建一个爬虫的请求头header. 1.python3跟2有了细微差别,所以我们先要引入request,python2没有这个request哦.然后复制网址给url,然后用一个字典来保存header,这个header怎么来的?看第2步. 2.打开任意浏览器某一页面(要联网),按f12,然后点network,之后再按f5,然后就会看到"name"这里,我们点击name里
-
Python3爬虫全国地址信息
PHP方式写的一团糟所以就用python3重写了一遍,所以因为第二次写了,思路也更清晰了些. 提醒:可能会有502的错误,所以做了异常以及数据库事务处理,暂时没有想到更好的优化方法,所以就先这样吧.待更懂python再进一步优化哈 欢迎留言赐教~ #!C:\Users\12550\AppData\Local\Programs\Python\Python37\python.exe # -*- coding: utf-8 -*- from urllib.request import urlopen
-
python3.4爬虫demo
python 3.4 所写爬虫 仅仅是个demo,以百度图片首页图片为例.能跑出图片上的图片: 使用 eclipse pydev 编写: from SpiderSimple.HtmLHelper import * import imp import sys imp.reload(sys) #sys.setdefaultencoding('utf-8') html = getHtml('http://image.baidu.com/') try: getImage(html) exit() exc
-
python爬虫获取百度首页内容教学
由传智播客教程整理,我们这里使用的是python2.7.x版本,就是2.7之后的版本,因为python3的改动略大,我们这里不用它.现在我们尝试一下url和网络爬虫配合的关系,爬浏览器首页信息. 1.首先我们创建一个urllib2_test01.py,然后输入以下代码: 2.最简单的获取一个url的信息代码居然只需要4行,执行写的python代码: 3.之后我们会看到一下的结果 4. 实际上,如果我们在浏览器上打开网页主页的话,右键选择"查看源代码",你会发现,跟我们刚打印出来的是一模
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-
python爬虫获取新浪新闻教学
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言,我们这篇文章来讲下爬虫,爬取新浪新闻 1. 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 2.首先,我们要写爬虫,可以借鉴
-
python构建基础的爬虫教学
爬虫具有域名切换.信息收集以及信息存储功能. 这里讲述如何构建基础的爬虫架构. 1. urllib库:包含从网络请求数据.处理cookie.改变请求头和用户处理元数据的函数.是python标准库.urlopen用于打开读取一个从网络获取的远程对象.能轻松读取HTML文件.图像文件及其他文件流. 2. beautifulsoup库:通过定位HTML标签格式化和组织复杂的网络信息,用python对象展现XML结构信息.不是标准库,可用pip安装.常用的对象是BeautifulSoup对象. 1.基础
-
Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验.(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到) 1.划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数.代理可以根据自己需要选择,当然免费的也是有
-
python爬虫超时的处理的实例
如下所示: #coding:utf-8 ''''' Created on 2014-7-24 @author: Administrator ''' import urllib2 try: url = "http://www.baidu.com" f = urllib2.urlopen(url, timeout=0) #timeout设置超时的时间 result = f.read() # print len(result) print result except Exception,e: