python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站——拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助。
完成的效果
爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中。最后中的效果示意图如下:

控制台输入
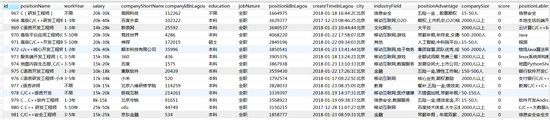
数据库显示
准备工作
首先需要安装python,这个网上已经有很多的教程了,这里就默认已经安装python,博主使用的是python3.6,然后安装了requests、pymysql(连接数据库使用)和Mysql数据库。
分析拉勾网
首先我们打开拉勾网,打开控制台,搜索java关键词搜索职位,选取北京地区,然后查看network一栏中的数据分析,查看第一个,是不是感觉它很像我们要拿到的请求地址,事实上不是的,这个打开之后是一个html,如果我们访问这个接口,拉钩会返回给我们一个结果,提示我们操作太频繁,也就是被拦截了。不过从这个页面可以看到,拉钩的网页用到了模板,这种加载数据的方式更加快速(大幅度提升),建议大家可以尝试使用一下(个人拙见)

不要气馁,我们接着往下找,可以看到一个“positionAjax”开头的请求,没错就它“ https://www.lagou.com/jobs/positionAjax.jsonpx=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0 ”,还是看图说话吧

找到请求地址之后,我们就开始写代码了。
先是导入requests和pymysql,然后requests的post方法访问上面找到的url,但是直接访问这个地址是会被拦截的,因为我们缺少所要传输的数据,和设置请求头,会被认为是非自然人请求的,加入请求头和数据,
headers = {'Referer':'https://www.lagou.com/jobs/list_'+position+'?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput=', 'Origin':'https://www.lagou.com', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
'Accept':'application/json, text/javascript, */*; q=0.01',
'Cookie':'JSESSIONID=ABAAABAAAGFABEFE8A2337F3BAF09DBCC0A8594ED74C6C0; user_trace_token=20180122215242-849e2a04-ff7b-11e7-a5c6-5254005c3644; LGUID=20180122215242-849e3549-ff7b-11e7-a5c6-5254005c3644; index_location_city=%E5%8C%97%E4%BA%AC; _gat=1; TG-TRACK-CODE=index_navigation; _gid=GA1.2.1188502030.1516629163; _ga=GA1.2.667506246.1516629163; LGSID=20180122215242-849e3278-ff7b-11e7-a5c6-5254005c3644; LGRID=20180122230310-5c6292b3-ff85-11e7-a5d5-5254005c3644; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516629163,1516629182; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516633389; SEARCH_ID=8d3793ec834f4b0e8e680572b83eb968'
}
dates={'first':'true',
'pn': page,#页数
'kd': position#搜索的职位
}
加入请求头之后就可以请求了,控制台输出数据,可以看出是一个json数据,使用json方法处理之后,一步步找到我们想要的数据,可以看出全在“result”里面,那么我们就只拿到他就行了,
result=resp.json()['content']['positionResult']['result']
这个时候可以看到数据非常多,有30个左右,不过不用担心,都是英文单词,基本上可以才出意思。接下来我们就要怕这些数据存储到数据库中,以备日后分析使用。
连接mysql我使用的是pymysql,先建好数据库和数据表,然后在代码中加入配置信息
config={
"host":"127.0.0.1",
"user":"root",
"password":"",
"database":databaseName,
"charset":"utf8"#防止中文乱码
}
加载配置文件,连接数据库
db = pymysql.connect(**config) cursor = db.cursor() sql=""#insert语句 cursor.execute() db.commit() #提交数据 cursor.close() db.close()#用完记得关闭连接
大功告成,这个时候拉钩的职位信息已经静静地躺在了你的数据库中,静待你的宠幸,拿到这些数据,你就可以进行一些分析了,比如平均工资水平、职位技能要求等。
因为篇幅有限,有些代码并没有粘贴出来,比如sql语句(这个sql写的挺长的),但是别担心,楼主已经把这个程序放入到github上面了,大家可以自行下载,github地址:https://github.com/wudb1993/pythonDemo如果觉得不错的话请在github上面点一下star,手打不易谢谢啦,欢迎大神拍砖。
总结
以上所述是小编给大家介绍的python爬取拉勾网职位数据的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

简单实现Python爬取网络图片
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下 代码: import urllib import urllib.request import re #打开网页,下载器 def open_html ( url): require=urllib.request.Request(url) reponse=urllib.request.urlopen(require) html=reponse.read() return html #下载图片 def load_imag
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-
Python3获取拉勾网招聘信息的方法实例
前言 为了了解跟python数据分析有关行业的信息,大概地了解一下对这个行业的要求以及薪资状况,我决定从网上获取信息并进行分析.既然想要分析就必须要有数据,于是我选择了拉勾,冒着危险深入内部,从他们那里得到了信息.不得不说,拉勾的反爬技术还挺厉害的,稍后再说明.话不多说,直接开始. 一.明确目的 每次爬虫都要有明确的目的,刚接触随便找东西试水的除外.我想要知道的是python数据分析的要求以及薪资状况,因此,薪资.学历.工作经验以及一些任职要求就是我的目的. 既然明确了目的,我们就要看一下它们在
-
Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它- 进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome. 右键图片>>检查 发现我们需要的图片src是在img标签下的,于是先试着用
-
python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页.我使用的是学信网,好了,网站截图如下: 网站的代码如下: <form method="get" name="form1" id="form1" action="/cet/query"> <table border=&qu
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
Python实现爬取需要登录的网站完整示例
本文实例讲述了Python爬取需要登录的网站实现方法.分享给大家供大家参考,具体如下: import requests from lxml import html # 创建 session 对象.这个对象会保存所有的登录会话请求. session_requests = requests.session() # 提取在登录时所使用的 csrf 标记 login_url = "https://bitbucket.org/account/signin/?next=/" result = se
-
python完成FizzBuzzWhizz问题(拉勾网面试题)示例
拉勾网面试题 1. 你首先说出三个不同的特殊数,要求必须是个位数,比如3.5.7.2. 让所有学生拍成一队,然后按顺序报数.3. 学生报数时,如果所报数字是第一个特殊数(3)的倍数,那么不能说该数字,而要说Fizz:如果所报数字是第二个特殊数(5)的倍数,那么要说Buzz:如果所报数字是第三个特殊数(7)的倍数,那么要说Whizz.4. 学生报数时,如果所报数字同时是两个特殊数的倍数情况下,也要特殊处理,比如第一个特殊数和第二个特殊数的倍数,那么不能说该数字,而是要说FizzBuzz, 以此类推
-
python3对拉勾数据进行可视化分析的方法详解
前言 上回说到我们如何把拉勾的数据抓取下来的,既然获取了数据,就别放着不动,把它拿出来分析一下,看看这些数据里面都包含了什么信息. (本次博客源码地址:https://github.com/MaxLyu/Lagou_Analyze (本地下载)) 下面话不多说了,来一起看看详细的介绍吧 一.前期准备 由于上次抓的数据里面包含有 ID 这样的信息,我们需要将它去掉,并且查看描述性统计,确认是否存在异常值或者确实值. read_file = "analyst.csv" # 读取文件获得数据