C++ 数据结构 堆排序的实现
堆排序(heapsort)是一种比较快速的排序方式,它的时间复杂度为O(nlgn),并且堆排序具有空间原址性,任何时候只需要有限的空间来存储临时数据。我将用c++实现一个堆来简单分析一下。
堆排序的基本思想为:
1、升序排列,保持大堆;降序排列,保持小堆;
2、建立堆之后,将堆顶数据与堆中最后一个数据交换,堆大小减一,然后向下调整;直到堆中只剩下一个有效值;
下面我将简单分析一下:
第一步建立堆:
1、我用vector顺序表表示数组;
2、用仿函数实现大小堆随时切换,实现代码复用;
3、实现向下调整算法,时间复杂度为O(lgn);
下面是我用某教材中的一个建最小堆的过程图,希望能更直观一些:
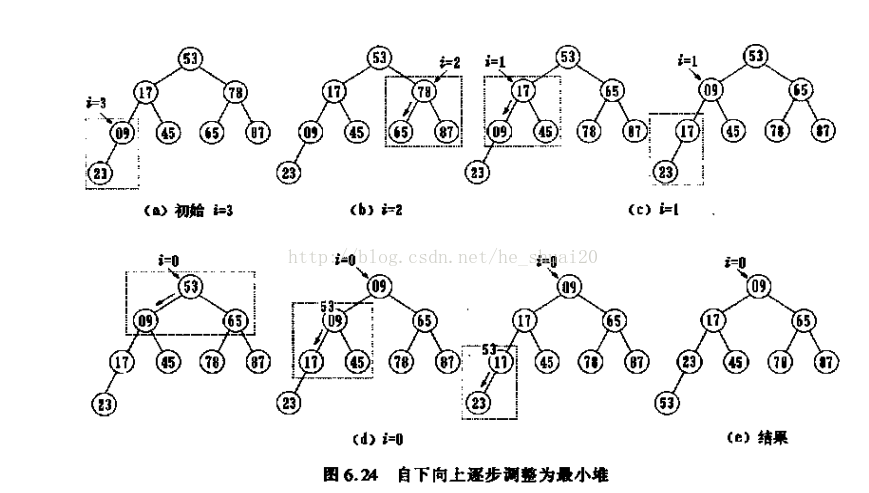
为了保证复用性,用仿函数重载了(),下面是复用的向下调整算法:
void _AdjustDown(int root,int size)
{
Camper camper; //仿函数
int parent = root;
int child = parent * 2 + 1;
while (child <= size) //保证访问不越界
{
if (child < size && camper(_vec[child+1] , _vec[child])) //保证存在右子树、同时判断右子树是否大于或小于左子树
{
child++;
}
if (camper(_vec[child], _vec[parent]))
{
swap(_vec[parent], _vec[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
排序算法思想:
1、将堆顶数据与堆中最后一个数据交换;
2、堆大小减一,然后调用向下调整算法;
3、结束条件:堆中剩下一个有效值;
排序算法实现:
void Sort()
{
size_t size = _vec.size(); //数据数量
while (size > 1)
{
swap(_vec[0], _vec[size - 1]);
size--;
_AdjustDown(size);
}
}
仿函数的实现:
template<class T>
struct Greater //大于
{
bool operator ()(const T& l, const T& p)
{
return l > p;
}
};
template<class T>
struct Less //小于
{
bool operator () (const T&l, const T& p)
{
return l < p;
}
};
完整的代码实现:
#include<iostream>
using namespace std;
#include<vector>
template<class T>
struct Greater //大于
{
bool operator ()(const T& l, const T& p)
{
return l > p;
}
};
template<class T>
struct Less //小于
{
bool operator () (const T&l, const T& p)
{
return l < p;
}
};
template<class T,class Camper>
class HeapSort //建大堆
{
public:
HeapSort()
{}
HeapSort(T* arr, size_t n)
{
_vec.reserve(n);
if (arr != NULL)
{
for (size_t i = 0; i < n; i++)
{
_vec.push_back(arr[i]);
}
}
_AdjustDown(_vec.size());
}
void Sort()
{
size_t size = _vec.size(); //数据数量
while (size > 1)
{
swap(_vec[0], _vec[size - 1]);
size--;
_AdjustDown(size);
}
}
void Print()
{
for (size_t i = 0; i < _vec.size(); i++)
{
cout << _vec[i] <<" ";
}
cout << endl;
}
protected:
void _AdjustDown(int size)
{
int parent = (size - 2) / 2;
while (parent >= 0)
{
_AdjustDown(parent, size - 1);
parent--;
}
}
void _AdjustDown(int root,int size)
{
Camper camper; //仿函数
int parent = root;
int child = parent * 2 + 1;
while (child <= size) //保证访问不越界
{
if (child < size && camper(_vec[child+1] , _vec[child])) //保证存在右子树、同时判断右子树是否大于或小于左子树
{
child++;
}
if (camper(_vec[child], _vec[parent]))
{
swap(_vec[parent], _vec[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
private:
vector<T> _vec;
};
测试用例代码:
void TextSort()
{
int a[] = { 10, 11, 13, 12, 16, 18, 15, 17, 14, 19 };
HeapSort<int,Greater<int>> h(a, sizeof(a) / sizeof(a[0]));
h.Print();
h.Sort();
h.Print();
}
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-
C++归并排序算法实例
归并排序 归并排序算法是采用分治法的一个非常典型的应用.归并排序的思想是将一个数组中的数都分成单个的:对于单独的一个数,它肯定是有序的,然后,我们将这些有序的单个数在合并起来,组成一个有序的数列.这就是归并排序的思想.它的时间复杂度为O(N*logN). 代码实现 复制代码 代码如下: #include <iostream> using namespace std; //将有二个有序数列a[first...mid]和a[mid...last]合并. void mergearray(int
-

C++堆排序算法的实现方法
本文实例讲述了C++实现堆排序算法的方法,相信对于大家学习数据结构与算法会起到一定的帮助作用.具体内容如下: 首先,由于堆排序算法说起来比较长,所以在这里单独讲一下.堆排序是一种树形选择排序方法,它的特点是:在排序过程中,将L[n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素. 一.堆的定义 堆的定义如下:n个关键字序列L[n]成为堆,当且仅当该序列满足: ①L(i) <= L(2i)且L(i) <= L(2
-
C++冒泡排序算法实例
冒泡排序 大学学习数据结构与算法最开始的时候,就讲了冒泡排序:可见这个排序算法是多么的经典.冒泡排序是一种非常简单的排序算法,它重复地走访过要排序的数列,每一次比较两个数,按照升序或降序的规则,对比较的两个数进行交换.比如现在我要对以下数据进行排序: 10 3 8 0 6 9 2 当使用冒泡排序进行升序排序时,排序的步骤是这样的: 3 10 8 0 6 9 2 // 10和3进行对比,10>3,交换位置 3 8 10 0 6 9 2 // 10再和8进行对比,10>8,交换位置 3 8 0
-
C++实现各种排序算法类汇总
C++可实现各种排序算法类,比如直接插入排序.折半插入排序.Shell排序.归并排序.简单选择排序.基数排序.对data数组中的元素进行希尔排序.冒泡排序.递归实现.堆排序.用数组实现的基数排序等. 具体代码如下: #ifndef SORT_H #define SORT_H #include <iostream> #include <queue> using namespace std; // 1.直接插入排序 template<class ElemType> void
-
C++堆排序算法实例详解
本文实例讲述了C++堆排序算法.分享给大家供大家参考,具体如下: 堆中元素的排列方式分为两种:max-heap或min-heap,前者每个节点的key都大于等于孩子节点的key,后者每个节点的key都小于等于孩子节点的key. 由于堆可以看成一个完全二叉树,可以使用连续空间的array来模拟完全二叉树,简单原始的实现如下: #include<iostream> int heapsize=0;//全局变量记录堆的大小 void heapSort(int array[],int n){ void
-
解读堆排序算法及用C++实现基于最大堆的堆排序示例
1.堆排序定义 n个关键字序列Kl,K2,-,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质): (1) ki≤K2i且ki≤K2i+1 或(2)Ki≥K2i且ki≥K2i+1(1≤i≤ ) 若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字. [例]关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1
-
C++插入排序算法实例
插入排序 没事喜欢看看数据结构和算法,增加自己对数据结构和算法的认识,同时也增加自己的编程基本功.插入排序是排序中比较常见的一种,理解起来非常简单.现在比如有以下数据需要进行排序: 10 3 8 0 6 9 2 当使用插入排序进行升序排序时,排序的步骤是这样的: 10 3 8 0 6 9 2 // 取元素3,去和10进行对比 3 10 8 0 6 9 2 // 由于10比3大,将10向后移动,将3放置在原来10的位置:再取8与前一个元素10进行对比 3 8 10 0 6 9 2 // 同理移动1
-
C++选择排序算法实例
选择排序 选择排序是一种简单直观的排序算法,它的工作原理如下.首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾.以此类推,直到所有元素均排序完毕. 选择排序的主要优点与数据移动有关.如果某个元素位于正确的最终位置上,则它不会被移动.选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多n-1次交换.在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常
-
C++中十种内部排序算法的比较分析
C++中十种内部排序算法的比较分析 #include<iostream> #include<ctime> #include<fstream> using namespace std; #define MAXSIZE 1000 //可排序表的最大长度 #define SORTNUM 10 //测试10中排序方法 #define max 100 //基数排序时数据的最大位数不超过百位: typedef struct node { int data3; int next; }
-
C语言植物大战数据结构堆排序图文示例
目录 TOP.堆排序前言 一.向下调整堆排序 1.向下调整建堆 建堆的技巧 建堆思路代码 2.向下调整排序 调整思路 排序整体代码 3.时间复杂度(难点) 向下建堆O(N) 向下调整(N*LogN) 二.向上调整堆排序 1.向上调整建堆 2.建堆代码 “大弦嘈嘈如急雨,小弦切切如私语”“嘈嘈切切错杂弹,大珠小珠落玉盘” TOP.堆排序前言 什么是堆排序?假如给你下面的代码让你完善堆排序,你会怎么写?你会怎么排? void HeapSort(int* a, int n) { } int main(
-
C语言 数据结构堆排序顺序存储(升序)
堆排序顺序存储(升序) 一: 完全二叉树的概念:前h-1层为满二叉树,最后一层连续缺失右结点! 二:首先堆是一棵全完二叉树: a:构建一个堆分为两步:⑴创建一棵完全二叉树 ⑵调整为一个堆 (标注:大根堆为升序,小根堆为降序) b:算法描述:①创建一棵完全二叉树 ②while(有双亲){ A:调整为大根堆: B:交换根和叶子结点: C:砍掉叶子结点: } c:时间复杂度为 O(nlogn) ,空间复杂度为 O(1), 是不稳定排序! 代码实现: /*堆排序思想:[完全二叉树的定义:前
-
C++ 数据结构 堆排序的实现
堆排序(heapsort)是一种比较快速的排序方式,它的时间复杂度为O(nlgn),并且堆排序具有空间原址性,任何时候只需要有限的空间来存储临时数据.我将用c++实现一个堆来简单分析一下. 堆排序的基本思想为: 1.升序排列,保持大堆:降序排列,保持小堆: 2.建立堆之后,将堆顶数据与堆中最后一个数据交换,堆大小减一,然后向下调整:直到堆中只剩下一个有效值: 下面我将简单分析一下: 第一步建立堆: 1.我用vector顺序表表示数组: 2.用仿函数实现大小堆随时切换,实现代码复用: 3.实现向下
-
C语言数据结构之堆排序源代码
本文实例为大家分享了C语言堆排序源代码,供大家参考,具体内容如下 1. 堆排序 堆排序的定义及思想可以参考百度百科: 用一句概括,堆排序就是一种改进的选择排序,改进的地方在于,每次做选择的时候,不单单把最大的数字选择出来,而且把排序过程中的一些操作进行了记录,这样在后续排序中可以利用,并且有分组的思想在里面,从而提高了排序效率,其效率为O(n*logn). 2. 源代码 堆排序中有两个核心的操作,一个是创建大顶堆(或者小顶堆,这里用的是大顶堆),再一个就是对堆进行调整.这里需要注意的是,并没有真
-
Go 数据结构之堆排序示例详解
目录 堆排序 堆排序过程 动画显示 开始堆排序 代码实现 总结 堆排序 堆排序是一种树形选择排序算法. 简单选择排序算法每次选择一个关键字最小的记录需要 O(n) 的时间,而堆排序选择一个关键字最小的记录需要 O(nlogn)的时间. 堆可以看作一棵完全二叉树的顺序存储结构. 在这棵完全二叉树中,如果每个节点的值都大于等于左边孩子的值,称为大根堆(最大堆.又叫大顶堆).如果每个节点的值都小于等于左边孩子的值,称为小根堆(最小堆,小顶堆). 可以,用数学符号表示如下: 堆排序过程 构建初始堆 在输
-
C语言植物大战数据结构二叉树递归
目录 前言 一.二叉树的遍历算法 1.构造二叉树 2.前序遍历(递归图是重点.) 3.中序遍历 4.后序遍历 二.二叉树遍历算法的应用 1.求节点个数 3.求第k层节点个数 4.查找值为x的节点 5.二叉树销毁 6.前序遍历构建二叉树 7.判断二叉树是否是完全二叉树 8.求二叉树的深度 三.二叉树LeetCode题目 1.单值二叉树 2. 检查两颗树是否相同 3. 对称二叉树 4.另一颗树的子树 6.反转二叉树 " 梧桐更兼细雨,到黄昏.点点滴滴." C语言朱武大战数据结构专栏 C语言
-
C语言植物大战数据结构快速排序图文示例
目录 快速排序 一.经典1962年Hoare法 1.单趟排序 2.递归左半区间和右半区间 3.代码实现 二.填坑法(了解) 1.单趟思路 2.代码实现 三.双指针法(最佳方法) 1.单趟排序 2.具体思路 3.代码递归图 4.代码实现 四.三数取中优化(最终方案) 1.三数取中 2.代码实现(最终代码) 五.时间复杂度(重点) 1.最好情况下 2.最坏情况下 3.空间复杂度 六.非递归写法 1.栈模拟递归快排 2.队列实现快排 浅浅总结下 “田家少闲月,五月人倍忙”“夜来南风起,小麦覆陇黄” C
-
C语言植物大战数据结构希尔排序算法
目录 前言 一.插入排序 1.排序思路 2.单趟排序 详细图解 3.整体代码 4.时间复杂度 (1).最坏情况下 (2).最好情况下 (3).基本有序情况下(重点) 5.算法特点 二.希尔排序 1.希尔从哪个方面优化的插入排序? 2.排序思路 3.预排序 4.正式排序 5.整体代码 6.时间复杂度 (1).while循环的复杂度 (2).每组gap的时间复杂度 结论: “至若春和景明,波澜不惊,上下天光,一碧万顷,沙鸥翔集,锦鳞游泳,岸芷汀兰,郁郁青青.” C语言朱武大战数据结构专栏 C语言植物
-
C语言植物大战数据结构二叉树堆
目录 前言 堆的概念 创建结构体 初始化结构体 销毁结构体 向堆中插入数据 1.堆的物理结构和逻辑结构 2.完全二叉树下标规律 3.插入数据思路 依次打印堆的值 删除堆顶的值 判断堆是否为空 求堆中有几个元素 得到堆顶的值 堆排序 总体代码 Heap.h Heap.c Test.c “竹杖芒鞋轻胜马,谁怕?一蓑烟雨任平生” C语言朱武大战数据结构专栏 C语言植物大战数据结构快速排序图文示例 C语言植物大战数据结构希尔排序算法 C语言植物大战数据结构堆排序图文示例 C语言植物大战数据结构二叉树递归
-
java 数据结构之堆排序(HeapSort)详解及实例
1 堆排序 堆是一种重要的数据结构,分为大根堆和小根堆,是完全二叉树, 底层如果用数组存储数据的话,假设某个元素为序号为i(Java数组从0开始,i为0到n-1),如果它有左子树,那么左子树的位置是2i+1,如果有右子树,右子树的位置是2i+2,如果有父节点,父节点的位置是(n-1)/2取整.最大堆的任意子树根节点不小于任意子结点,最小堆的根节点不大于任意子结点. 所谓堆排序就是利用堆这种数据结构的性质来对数组进行排序,在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的性质可知,最大的