Python+opencv 实现图片文字的分割的方法示例
实现步骤:
1、通过水平投影对图形进行水平分割,获取每一行的图像;
2、通过垂直投影对分割的每一行图像进行垂直分割,最终确定每一个字符的坐标位置,分割出每一个字符;
先简单介绍一下投影法:分别在水平和垂直方向对预处理(二值化)的图像某一种像素进行统计,对于二值化图像非黑即白,我们通过对其中的白点或者黑点进行统计,根据统计结果就可以判断出每一行的上下边界以及每一列的左右边界,从而实现分割的目的。
下面通过Python+opencv来实现该功能
首先来实现水平投影:
import cv2
import numpy as np
'''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection)
return h_
if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#水平投影
H = getHProjection(img)
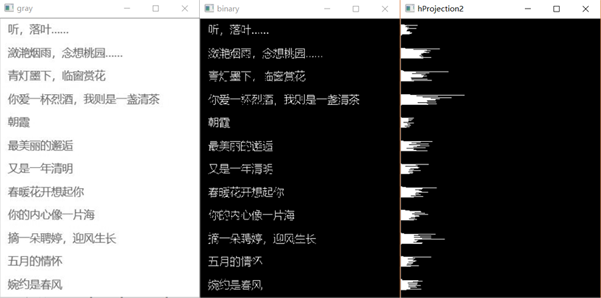
通过上面的水平投影,根据其白色小山峰的起始位置就可以界定出每一行的起始位置,从而把每一行分割出来。

获得每一行图像之后,可以对其进行垂直投影
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
cv2.imshow('vProjection',vProjection)
return w_

通过垂直投影可以获得每一个字符左右的起始位置,这样也就可以获得到每一个字符的具体坐标位置,即一个矩形框的位置。
下面是实现的全部代码:
import cv2
import numpy as np
'''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection)
return h_
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
#cv2.imshow('vProjection',vProjection)
return w_
if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#图像高与宽
(h,w)=img.shape
Position = []
#水平投影
H = getHProjection(img)
start = 0
H_Start = []
H_End = []
#根据水平投影获取垂直分割位置
for i in range(len(H)):
if H[i] > 0 and start ==0:
H_Start.append(i)
start = 1
if H[i] <= 0 and start == 1:
H_End.append(i)
start = 0
#分割行,分割之后再进行列分割并保存分割位置
for i in range(len(H_Start)):
#获取行图像
cropImg = img[H_Start[i]:H_End[i], 0:w]
#cv2.imshow('cropImg',cropImg)
#对行图像进行垂直投影
W = getVProjection(cropImg)
Wstart = 0
Wend = 0
W_Start = 0
W_End = 0
for j in range(len(W)):
if W[j] > 0 and Wstart ==0:
W_Start =j
Wstart = 1
Wend=0
if W[j] <= 0 and Wstart == 1:
W_End =j
Wstart = 0
Wend=1
if Wend == 1:
Position.append([W_Start,H_Start[i],W_End,H_End[i]])
Wend =0
#根据确定的位置分割字符
for m in range(len(Position)):
cv2.rectangle(origineImage, (Position[m][0],Position[m][1]), (Position[m][2],Position[m][3]), (0 ,229 ,238), 1)
cv2.imshow('image',origineImage)
cv2.waitKey(0)
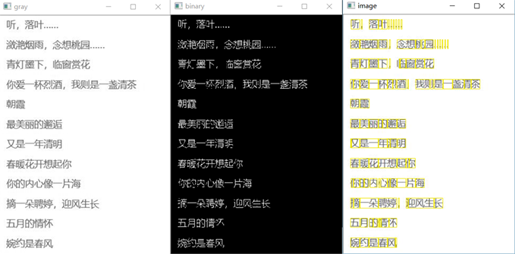
从分割的结果上看,基本上实现了图片中文字的分割。但由于中文结构复杂性,对于一些文字的分割并不理想,比如“叶”、“桃”等字会出现过度分割现象;对于有粘连的两个字会出现分割不够的现象,比如上图中的“念想”。不过可以从图像预处理(腐蚀),边界判断阈值的调整等方面进行优化。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python opencv实现图片旋转矩形分割
有时候需要对有角度的矩形框内图像从原图片中分割出来.这里的程序思想是,先将图片进行矩形角度的旋转,使有角度的矩形处于水平状态后,根据原来坐标分割图片. 参考:python opencv实现旋转矩形框裁减功能 修改原来的程序: 1.旋转函数的输入仅为矩形的四点坐标 2.角度由公式计算出来 3.矩形四点pt1,pt2,pt3,pt4由txt文件读入 4.在旋转程序中还处理了顺时针和逆时针及出现矩形框翻转的问题. 代码: # -*- coding:utf-8 -*- import cv2 from m
-
Python+opencv 实现图片文字的分割的方法示例
实现步骤: 1.通过水平投影对图形进行水平分割,获取每一行的图像: 2.通过垂直投影对分割的每一行图像进行垂直分割,最终确定每一个字符的坐标位置,分割出每一个字符: 先简单介绍一下投影法:分别在水平和垂直方向对预处理(二值化)的图像某一种像素进行统计,对于二值化图像非黑即白,我们通过对其中的白点或者黑点进行统计,根据统计结果就可以判断出每一行的上下边界以及每一列的左右边界,从而实现分割的目的. 下面通过Python+opencv来实现该功能 首先来实现水平投影: import cv2 impor
-
python opencv将图片转为灰度图的方法示例
使用opencv将图片转为灰度图主要有两种方法,第一种是将彩色图转为灰度图,第二种是在使用OpenCV读取图片的时候直接读取为灰度图. 将彩色图转为灰度图 import cv2 import numpy as np if __name__ == "__main__": img_path = "timg.jpg" img = cv2.imread(img_path) #获取图片的宽和高 width,height = img.shape[:2][::-1] #将图片缩小
-
Python OpenCV 直方图的计算与显示的方法示例
本篇文章介绍如何用OpenCV Python来计算直方图,并简略介绍用NumPy和Matplotlib计算和绘制直方图 直方图的背景知识.用途什么的就直接略过去了.这里直接介绍方法. 计算并显示直方图 与C++中一样,在Python中调用的OpenCV直方图计算函数为cv2.calcHist. cv2.calcHist的原型为: cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate ]]) #返回his
-
python opencv根据颜色进行目标检测的方法示例
颜色目标检测就是根据物体的颜色快速进行目标定位.使用cv2.inRange函数设定合适的阈值,即可以选出合适的目标. 建立项目colordetect.py,代码如下: #! /usr/bin/env python # -*- coding: utf-8 -*- import numpy as np import cv2 def colorDetect(): image = cv2.imread('./1.png') # 使用RGB颜色空间检测红 蓝 黄 灰,设置合适的阈值 boundaries
-
python OpenCV学习笔记之绘制直方图的方法
本篇文章主要介绍了python OpenCV学习笔记之绘制直方图的方法,小编觉得挺不错的,现在分享给大家,也给大家做个参考.一起跟随小编过来看看吧 官方文档 – https://docs.opencv.org/3.4.0/d1/db7/tutorial_py_histogram_begins.html 直方图会让你对图像的强度分布有一个全面的认识.它是一个在x轴上带有像素值(从0到255,但不总是),在y轴上的图像中对应的像素数量的图. 这只是理解图像的另一种方式.通过观察图像的直方图,你可以直
-
python简单实现图片文字分割
本文实例为大家分享了python简单实现图片文字分割的具体代码,供大家参考,具体内容如下 原图: 图片预处理:图片二值化以及图片降噪处理. # 图片二值化 def binarization(img,threshold): #图片二值化操作 width,height=img.size im_new = img.copy() for i in range(width): for j in range(height): a = img.getpixel((i, j)) aa = 0.30 * a[0]
-
Python Opencv实战之文字检测OCR
目录 1.相关函数的讲解 2.代码展示 Detecting Words Detecting ONLY Digits 3.问题叙述 4.image_to_data()配置讲解 5.项目拓展 6.总结与评价 1.相关函数的讲解 image_to_data()的输出结果是表格形式,输出变量的类型依旧是字符串. 你会得到一个这样的列表['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', '
-
python下的opencv画矩形和文字注释的实现方法
画矩形 函数调用:cv2.rectangle(img,pt1,pt2,color,thickness,line_type,shift) img: 图像. pt1: 矩形的一个顶点. pt2: 矩形对角线上的另一个顶点 color: 线条颜色 (RGB) 或亮度(灰度图像 )(grayscale image). thickness: 组成矩形的线条的粗细程度.取负值时(如 CV_FILLED)函数绘制填充了色彩的矩形. line_type: 线条的类型.见cvLine的描述 shift: 坐标点的
-
python opencv 读取图片 返回图片某像素点的b,g,r值的实现方法
如下所示: #coding=utf-8 #读取图片 返回图片某像素点的b,g,r值 import cv2 import numpy as np img=cv2.imread('./o.jpg') px=img[10,10] print px blue=img[10,10,0] print blue green=img[10,10,1] print blue red=img[10,10,2] print blue 以上这篇python opencv 读取图片 返回图片某像素点的b,g,r值的实现方