分享4个最受欢迎的大数据可视化工具
想像阅读书本一样阅读数据流?这只有在电影中才有可能发生。 在现实世界中,企业必须使用数据可视化工具来读取原始数据的趋势和模式。

大数据可视化是进行各种大数据分析解决的最重要组成部分之一。 一旦原始数据流被以图像形式表示时,以此做决策就变得容易多了。 为了满足并超越客户的期望,大数据可视化工具应该具备这些特征:
· 能够处理不同种类型的传入数据
· 能够应用不同种类的过滤器来调整结果
· 能够在分析过程中与数据集进行交互
· 能够连接到其他软件来接收输入数据,或为其他软件提供输入数据
· 能够为用户提供协作选项
尽管实际上存在着无数专门用于大数据可视化的工具,且它们都是既开源又专有的,在这其中还是有一些工具表现比较突出,因为它们提供了上述所有或者很多部分功能。 我们将介绍4种最受欢迎的大数据可视化工具,帮助大家选择适合自己需求的工具。
Jupyter:大数据可视化的一站式商店
JupyteR是一个开源项目,通过十多种编程语言实现大数据分析、可视化和软件开发的实时协作。 它的界面包含代码输窗口,并通过运行输入的代码以基于所选择的可视化技术提供视觉可读的图像。
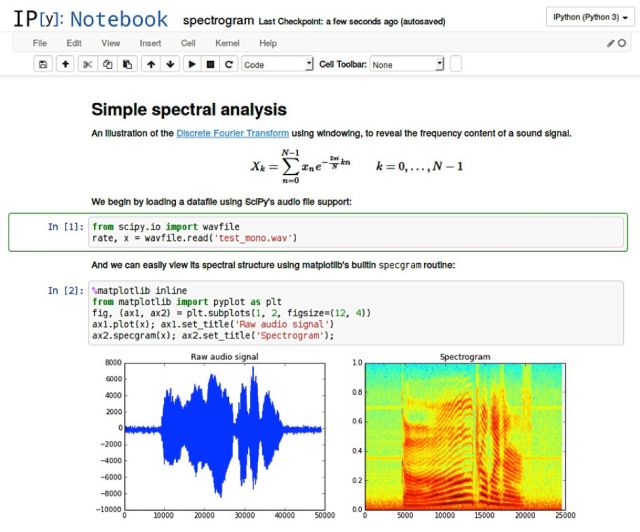
但是,以上提到的功能仅仅是冰山一角。 Jupyter Notebook可以在团队中共享,以实现内部协作,并促进团队共同合作进行数据分析。 团队可以将Jupyter Notebook上传到GitHub或Gitlab,以便能共同合作影响结果。团队可以使用Kubernetes将Jupyter Notebook包含在Docker容器中,也可以在任何其他使用Jupyter的机器上运行Notebook。 在最初使用Python和R时,Jupyter Notebook正在积极地引入Java,Go,C#,Ruby等其他编程语言编码的内核。
除此以外,Jupyter还能够与Spark这样的多框架进行交互,这使得对从具有不同输入源的程序收集的大量密集的数据进行数据处理时,Jupyte能够提供一个全能的解决方案。
Tableau:AI,大数据和机器学习应用可视化的最佳解决方案
Tableau是大数据可视化的市场领导者之一,在为大数据操作,深度学习算法和多种类型的AI应用程序提供交互式数据可视化方面尤为高效。
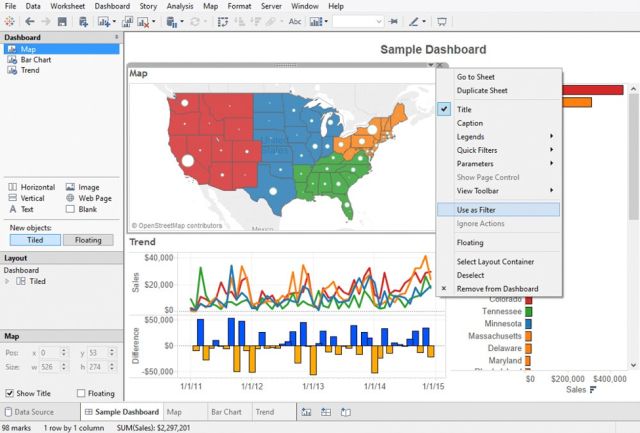
Tableau可以与Amazon AWS,MySQL,Hadoop,Teradata和SAP协作,使之成为一个能够创建详细图形和展示直观数据的多功能工具。 这样高级管理人员和中间链管理人员能够基于包含大量信息且容易读懂的Tableau图形作出基础决策。
Google Chart:Google支持的免费而强大的整合功能
谷歌是当今领导力的代名词。正如谷歌浏览器是当前最流行的浏览器一样,谷歌图表也是大数据可视化的最佳解决方案之一,更不用说它是完全免费的,并得到了Google的大力技术支持。 为什么它能得到Google的支持? 因为通过Google Chart来分析的数据显然是要用于训练Google研发的AI,这样的合作对于各方来说都是双赢的。
Google Chart提供了大量的可视化类型,从简单的饼图、时间序列一直到多维交互矩阵都有。 图表可供调整的选项很多。如果需要对图表进行深度定制,可以参考详细的帮助部分。
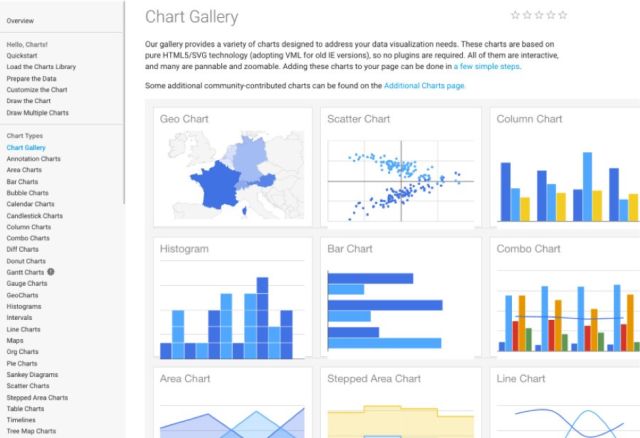
该工具将生成的图表以HTML5 / SVG呈现,因此它们可与任何浏览器兼容。 Google Chart对VML的支持确保了其与旧版IE的兼容性,并且可以将图表移植到最新版本的Android和iOS上。 更重要的是,Google Chart结合了来自Google地图等多种Google服务的数据。 生成的交互式图表不仅可以实时输入数据,还可以使用交互式仪表板进行控制。
D3.js:以任何您需要的方式直观地显示大数据
D3.js代表Data Driven Document,一个用于实时交互式大数据可视化的JS库。 由于这不是一个工具, 所以用户在使用它来处理数据之前,需要对Javascript有一个很好的理解,并能以一种能被其他人理解的形式呈现。 除此以外,这个JS库将数据以SVG和HTML5格式呈现,所以像IE7和8这样的旧式浏览器不能利用D3.js功能。

从不同来源收集的数据如大规模数据将与实时的DOM绑定并以极快的速度生成交互式动画(2D和3D)。 D3架构允许用户通过各种附件和插件密集地重复使用代码.
最后的想法
以上提到的4种可视化工具只不过是大量在线或独立的数据可视化解决方案和工具中的一部分 。 每家公司都能够找到最适合他们的工具,并能够使用这些工具帮助他们将输入的原始数据转化为一系列清晰易懂的图像和图表。 这些数据本身没有任何价值,是借助可视化做的决策帮助它们实现驱动价值的 - -数据可视化工具有助于确定趋势和模式,从而做出有证据支持的决策。
总结
以上所述是小编给大家介绍的分享4个最受欢迎的大数据可视化工具 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
phpexcel导入excel处理大数据(实例讲解)
先下载对应phpExcel 的包就行了https://github.com/PHPOffice/PHPExcel 下载完成 把那个Classes 这个文件夹里面的 文件跟文件夹拿出来就好了. 直接写到PHPExcel 这个文件里面的.调用很简单.引入phpExcel 这个类传递对应的excel 文件的路径就好了 现在上传到指定的目录,然后加载上传的excel文件读取这里读取是的时候不转换数组了.注意:是Sheet可以多个读取,php上传值要设置大,上传超时要设置长. header('Conten
-

为什么入门大数据选择Python而不是Java?
马云说:"未来最大的资源就是数据,不参与大数据十年后一定会后悔."毕竟出自wuli马大大之口,今年二月份我开始了学习大数据的道路,直到现在对大数据的学习脉络和方法也渐渐清晰.今天我们就来谈谈学习大数据入门语言的选择.当然并不只是我个人之见,此外我搜集了各路大神的见解综合起来跟大家做个讨论. java和python的区别到底在哪里? 官方解释:Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易
-
PHP实现实时生成并下载超大数据量的EXCEL文件详解
前言 最近在工作中接到一个需求,通过选择的时间段导出对应的用户访问日志到excel中, 由于用户量较大,经常会有导出50万加数据的情况.而常用的PHPexcel包需要把所有数据拿到后才能生成excel, 在面对生成超大数据量的excel文件时这显然是会造成内存溢出的,所以考虑使用让PHP边写入输出流边让浏览器下载的形式来完成需求. 我们通过如下的方式写入PHP输出流 $fp = fopen('php://output', 'a'); fputs($fp, 'strings'); .... ...
-
mysql大数据查询优化经验分享(推荐)
正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒. 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化. 实验环境:MacBook Pro MJLQ2CH/A,mysql5.7,数据量:212万+ ONE: select * from article INNER JOIN ( SELECT id FROM article WHERE length(content_url) > 0 an
-
30个mysql千万级大数据SQL查询优化技巧详解
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用
-
Python3实现将本地JSON大数据文件写入MySQL数据库的方法
本文实例讲述了Python3实现将本地JSON大数据文件写入MySQL数据库的方法.分享给大家供大家参考,具体如下: 最近导师给了一个yelp上的评论数据,数据量达到3.55个G,如果进行分析时直接使用本地文件,选择python来分析,那么效率是非常低的:另一方面使用SQL来储存文本文件最为安全,之前使用CSV,txt存储的文本文件最后莫名其妙地出现一些奇怪字符,导致读取数据分割时出现错乱.下面给出一个简单的代码,将本地JSON文件内容存入数据库. 说明:python版本为3.5,使用第三方库为
-
分享4个最受欢迎的大数据可视化工具
想像阅读书本一样阅读数据流?这只有在电影中才有可能发生. 在现实世界中,企业必须使用数据可视化工具来读取原始数据的趋势和模式. 大数据可视化是进行各种大数据分析解决的最重要组成部分之一. 一旦原始数据流被以图像形式表示时,以此做决策就变得容易多了. 为了满足并超越客户的期望,大数据可视化工具应该具备这些特征: · 能够处理不同种类型的传入数据 · 能够应用不同种类的过滤器来调整结果 · 能够在分析过程中与数据集进行交互 · 能够连接到其他软件来接收输入数据
-
SpringBoot+Thymeleaf+ECharts实现大数据可视化(基础篇)
目录 0x01 新建SpringBoot项目 2. 编写HelloWorld程序代码 0x02 引入ECharts资源 1. 获取JQuery与ECharts资源 2. 新建ECharts模版html文件 3. 添加后台java代码 4. ECharts模版样式预览 0x03 SpringBoot整合Thymeleaf 1. 新建myECharts方法 2. 引入Thymeleaf 3. ECharts新样式预览 4. 模式升级 0xFF 总结 0x01 新建SpringBoot项目 1. 新建
-
Python数据可视化常用4大绘图库原理详解
今天我们就用一篇文章,带大家梳理matplotlib.seaborn.plotly.pyecharts的绘图原理,让大家学起来不再那么费劲! 1. matplotlib绘图原理 关于matplotlib更详细的绘图说明,大家可以参考下面这篇文章,相信你看了以后一定学得会. matplotlib绘图原理:http://suo.im/678FCo 1)绘图原理说明 通过我自己的学习和理解,我将matplotlib绘图原理高度总结为如下几步: 导库;创建figure画布对象;获取对应位置的axes坐标
-
基于python分享一款地理数据可视化神器keplergl
目录 1.简介 2.例子 3.添加数据 4.定制图表 5.获取配置 6.导出图表 7.总结 1.简介 keplergl是由Uber开源的一款地理数据可视化工具,通过keplergl我们可以在Jupyter notebook中使用, 可视化效果如下图所示: 安装: 官方文档:https://docs.kepler.gl/docs/keplergl-jupyter 通过pip安装keplergl: pip install keplergl 如果你使用MAC通过PIP安装而且notebook版本在
-
Sqlserver 高并发和大数据存储方案
随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! 案例:游戏平台. 1.解决高并发 当客户端连接数达到峰值的时候,服务端对连接的维护与处理这里暂时不做讨论.当多个写请求到数据库的时候,这时候需要对多张表进行插入,尤其一些表 达到每天千万+的存储,随着时间的积累,传统的同步写入数据的方式显然不可取,经过试验,通过异步插入的方式改善了许多,但与此同时,对读取数据的实时性也需要做一定的牺牲. 异步的
-
php 在线导入mysql大数据程序
php 在线导入 mysql 大数据程序 <?php header("content-type:text/html;charset=utf-8"); error_reporting(E_ALL); set_time_limit(0); $file='./test.sql'; $data=file($file); echo "<pre>"; //print_r($data); $data_new=array(); $tmp=array(); fore
-
Java开发者必备10大数据工具和框架
当今IT开发人员面对的最大挑战就是复杂性,硬件越来越复杂,OS越来越复杂,编程语言和API越来越复杂,我们构建的应用也越来越复杂.根据外媒的一项调查报告,中软卓越专家列出了Java程序员在过去12个月内一直使用的一些工具或框架,或许会对你有意义. 先来看看大数据的概念.根据维基百科,大数据是庞大或复杂的数据集的广义术语,因此传统的数据处理程序不足以支持如此庞大的体量. 在许多情况下,使用SQL数据库存储/检索数据都是很好的选择.而现如今的很多情况下,它都不再能满足我们的目的,这一切都取决于用例的
-
大数据时代的数据库选择:SQL还是NoSQL?
一.专家简介VoltDB公司首席技术官Ryan Betts表示,SQL已经赢得了大型企业的广泛部署,大数据是它可以支持的另一个领域.Couchbase公司首席执行官Bob Wiederhold表示,NoSQL是可行的选择,并且从很多方面来看,它是大数据的最佳选择,特别是涉及到可扩展性时.二.SQL经历时间的考验,并仍然在蓬勃发展结构化查询语言(SQL)是经过时间考验的胜利者,它已经主宰了几十年,目前大数据公司和组织(例如谷歌.Facebook.Cloudera和Apache)正在积极投资于SQL